【Python】GPT+Whisper+gradio+VOICEVOXで疑似Siriを作ってみた

前書き
前回までの記事でOpenAI API(GPT及びWhisper)を使ってみたり、gradioでの簡易Webアプリ作成、VOICEVOXエンジンによる音声読み上げを試してみました。そこでこれらを結合させて以下を実現してみようと思います。
gradioによる音声入力
Whisperによる音声⇒テキストへの変換
変換されたテキストを入力としたGPTの実行
GPTのレスポンスをVOICEVOXで読み上げる
GPTのレスポンスをチャットボット風にWeb出力
実践…の前に見た目を少し気にしてみたり
前回の記事で音声入力⇒GPTによるレスポンスの取得までは実施していたので、ここにVOICEVOXのAPIを付け加えれば完成!なのですが、それではあまりにも味気無さすぎなので画面上の見た目も少し変えてみようと思います。
前回の記事では2カラム構成になっていましたが、GPTとのやり取りが片方のカラムに貯まり続けるのは少し見づらい状態でした。なので今回は1カラム構成に変更してみようと思います。
★前回の記事
で、実際はどのようにすればよいかというとgradioのBlockクラスを使用することでレイアウトを操作することが出来ます。
これまではInterfaceクラスを使っていましたのでザックリ違いを記載します。
Interfaceクラス⇒Blockクラスより上位のクラスであらかじめ骨組みが作られている。そのため数行のコーディングのみで画面を作ることが可能。
Blockクラス⇒Interfaceクラスより下位のクラスで骨組みが定まっていないためカスタムしやすい。その代わりにコーディングの知識がInterfaceクラスよりは必要となる。
公式docs:Gradio Blocks Docs
実践
with句で始まるBlockクラス内で画面レイアウトを定めてsubmitボタンにメソッドを埋め込んでいます。VOICEVOXによる読み上げを行っているのでプログラムを実行する前にVOICEVOXエンジンを立ち上げておきましょう。
import openai
import gradio as gr
import secret_keys
import requests
import json
import pyaudio
# OpenAIで発効したトークンを設定
openai.api_key = secret_keys.openai_api_key
def vvox_test(text):
# エンジン起動時に表示されているIP、portを指定
host = "127.0.0.1"
port = 50021
# 音声化する文言と話者を指定(3で標準ずんだもんになる)
params = (
('text', text),
('speaker', 3),
)
# 音声合成用のクエリ作成
query = requests.post(
f'http://{host}:{port}/audio_query',
params=params
)
# 音声合成を実施
synthesis = requests.post(
f'http://{host}:{port}/synthesis',
headers = {"Content-Type": "application/json"},
params = params,
data = json.dumps(query.json())
)
# 再生処理
voice = synthesis.content
pya = pyaudio.PyAudio()
# サンプリングレートが24000以外だとずんだもんが高音になったり低音になったりする
stream = pya.open(format=pyaudio.paInt16,
channels=1,
rate=24000,
output=True)
stream.write(voice)
stream.stop_stream()
stream.close()
pya.terminate()
def gpt_connect(prompt):
# GPTに直接APIを送っている部分
comp = openai.ChatCompletion.create(
# 処理モデルを指定
model = "gpt-3.5-turbo",
messages = [
{"role" : "user", "content" : prompt}
]
)
message = comp.choices[0].message.content
return message.strip()
def chatbot(input, history=[]):
# 入力音声をWhisperで文字に変換
audiofile = open(input, "rb")
conversion = openai.Audio.transcribe("whisper-1", audiofile)
# 入力を履歴へ追加
history.append({
"role" : "user", "content" : conversion["text"]
})
# 音声から変換した文字列をGPTへ送信
output = gpt_connect(conversion["text"])
history.append({
"role" : "assistant", "content" : output
})
vvox_test(output)
return [(history[i]["content"], history[i+1]["content"]) for i in range(0, len(history)-1, 2)]
with gr.Blocks() as demo:
chat = gr.Chatbot()
msg = gr.Audio(source = "microphone", type = "filepath")
btn = gr.Button("submit")
btn.click(fn=chatbot, inputs=msg, outputs=chat)
clear = gr.ClearButton(components=msg, value="clear")
if __name__ == "__main__":
demo.launch(debug=True)
★VOICEVOXについては以下の記事へ
起動して実行してみるとちゃんと回答して喋ってくれますね。ただし、読み上げている最中はチャットログが更新されない&読み上げるまでの変換に時間が掛かるといった部分はやはり気になりました。
実行⇒30~40秒経過してからVOICEVOXによる読み上げ⇒読み上げ後にチャットログ出力といった流れでしたので、テンポよく実施するには①マシンスペックを上げてVOICEVOXでの変換速度を上げる②別のフレームワークを使ってカスタマイズ性を上げる、などの試行が必要になりそうでした。
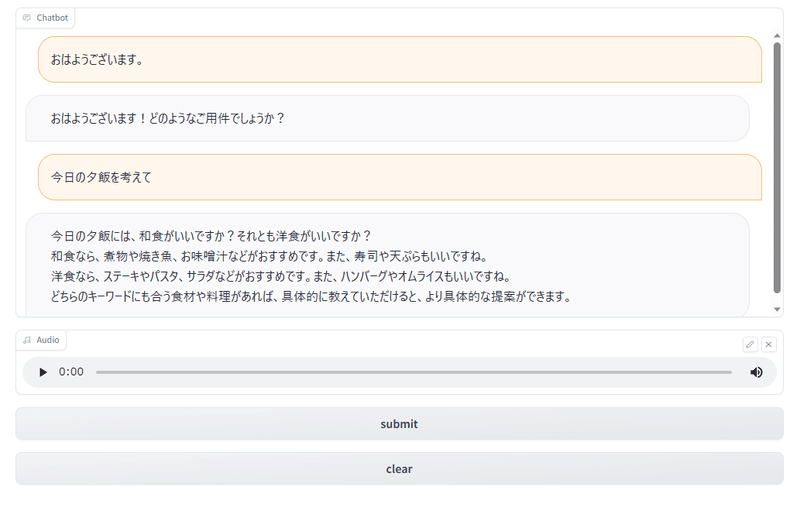
使ってみた感想
テンポはよくないものの対話できている感があってとても面白いと思いました!
今回はGPTを頭脳役に使ってみましたが、例えばTRPGのルールブックを読ませたAIとかに差し替えればAIがゲームマスターをやってくれたりするんですかね?そんなAIを複数用意してプロンプトで性格やVOICEVOXの話者を別々に設定したら穴埋め要員も簡単に作れそうですよね(どれだけ遊び相手が少ないんだっていう思考ですが)。
この記事が気に入ったらサポートをしてみませんか?