
分類AIの進化史㉒MobileViT

前回は、畳み込みもアテンションも使わないMLP-Mixerの解説をしました。今回は、畳み込みもアテンションも使う(組み合わせた)MobileViTを紹介します。
MobileViTの論文は、2021年にAppleが発表しました。
そのタイトルは「MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer」で、日本語に訳すとしたら「MobileViT: 軽量、汎用、モバイル・フレンドリーなビジョン・トランスフォーマー」といったところでしょうか。
意図としては、モバイル向け(軽量、高速)なモデルを構築することを目指しています。そのため、パラメータが比較的に少ない畳み込みを画像の局所的な特徴を捉えるために使い、アテンションを画像全体を通じたパターンを認識するために使うことを提案しました。
MobileViTは、畳み込みニューラルネットワーク(CNN)とビジョントランスフォーマー(ViT)を組み合わせたモデルであり、ResNetやMobileNetV3などと比較して、より軽量でより高い精度を達成しました。
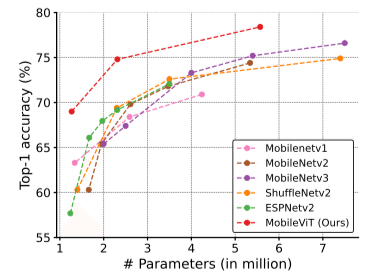
なお、MobileViTのソースコードは、CVNetsという名前のライブラリの一部として公開されています。
さて、MobileViTでは、どのようにしてCNNとViTを組み合わせたのでしょうか?
この記事では、MobileViTの仕組みを解説します。
この記事が気に入ったらサポートをしてみませんか?