
Pythonライブラリ(SQL):SQLAlchemy-relationshipとテーブル設計

概要
下記記事でSQLを操作できるORMのSQLAlchemyを紹介しました。
SQLAlchemyの機能であるrelation/relationshipに関して内容が多く、かつ事前に必要な知識が多かったため別記事で作成しました。なお事前知識のキーワードは下記に一覧で紹介します。
※現在勉強中のため内容は不足しているためあくまで備忘録レベルです。
【キーワード】
●主キー
●外部キー
●DB設計
●正規化/非正規化
●無損失分解:可逆的にテーブルを結合・分割できるようなテーブル分割
1.DB設計
文字通りデータベース(DB)の設計ですが下記を目的としております。
【DB設計の目的】
●冗長性の排除+一貫性と効率性を保持
ー>データの更新処理を簡略化など
ー>データの不整合防止
ー>そもそもデータが入力できないようなテーブルの防止
●NULL値入力の防止※大前提としてNULL値はよくない
●SQL操作のパフォーマンス向上
ー>第一正規化ができていないとそもそも主キーが決められない
ー>正規化するとJOINが入るため性能は低下する点は注意が必要
ここで特に重要なのが正規化となります。具体的にはDBのテーブルをひとまとめにするのではなく目的・機能に応じて(分割して)複数のテーブルを作成します(ほしいテーブルはJOIN結合して作成する)。
【参考記事】
●データベースの正規化とは? 株式会社システムインテグレータ
●正規化の要点を理解する(Qiita)
●正規化とは(データベース)
●Wiz テックブログ
2.正規化
正規化に関しては本・ブログ・Youtubeなどで情報が出ているため、本章はあくまで自分用の備忘録に近い内容になります。正規化は第1~6(+第3.5:ボイス-コッド)までありますが、本章では第1~3のみ紹介します。
サンプルテーブルとしては下記をイメージしております。

2-1:第1正規化
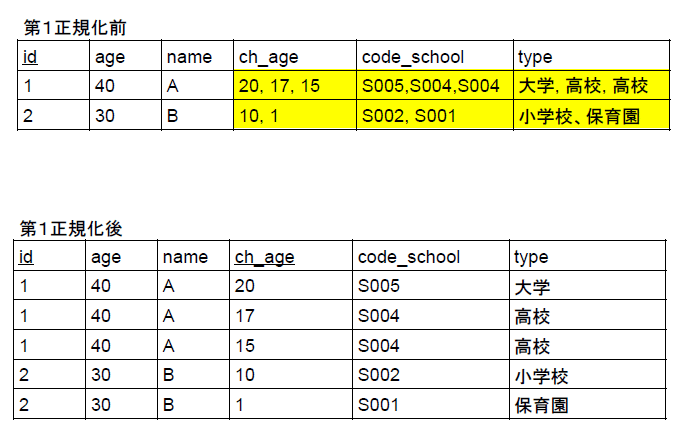
第1正規化の定義は「一つのセルの中には一つの値しか含まない」です。1つのセルに複数データ入力しているテーブルは間違いです(下表参照)。
【第1正規化ではないときの問題点】
●主キーだと値を一意に決めることができない。
●2つのデータがあるとその中でほしいデータを抽出できない(関数従属性がない)
2-2:第2正規化~部分関数従属
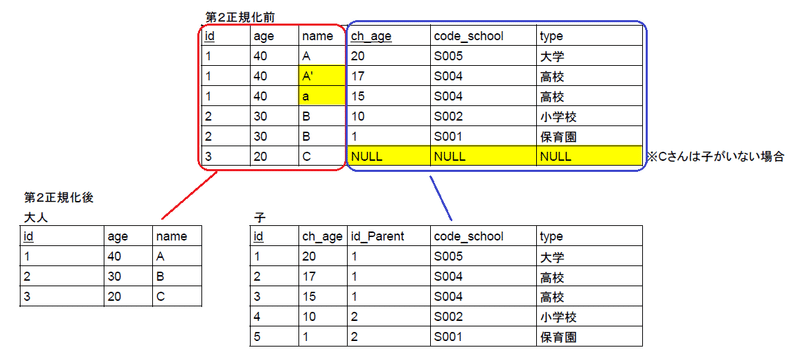
第2正規化の定義は「テーブルの部分関数従属を解消して完全関数従属にする」です。関数従属性とは関数f(x)の様に、特定の値xに対して一意の値f(x)がでる関係です。例として大人テーブルよりid選択で名前が決まる({id}→{名前})ような状態です。
部分関数従属は主キーに対して関数従属性がある列が存在することであり、問題点は下記の通りです。
【第2正規化ではないときの問題点】
●データ登録時にNULLが発生する可能性が出る。
●データの不整合が起こる可能性が出てくる(入力ミスなど)。
【第2正規化のポイント】
●テーブルを分割していくがJOINにより元のテーブルに戻すことができるように分割する(無損失分解)
具体例でいうと元の表だと名前の入力間違いで{id}->{name}の整合性が取れなくなったり、必要なデータを入力するとNULLが発生したりします。

そのような問題をなくすためにテーブルを分割して第2正規化します。
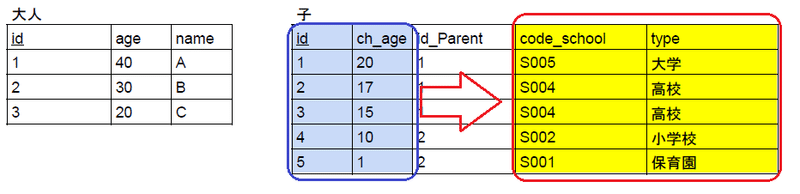
2-3:第3正規化~推移的関数従属
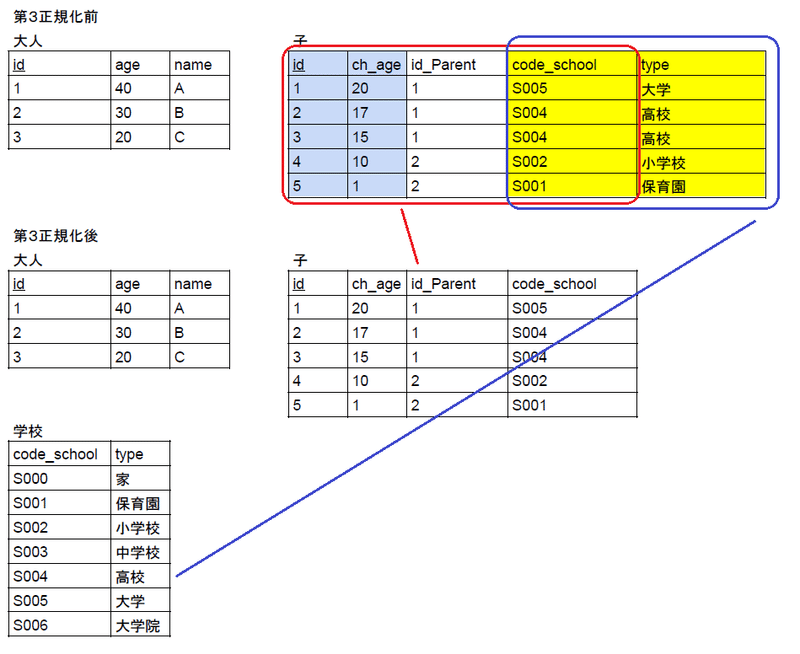
第3正規化の定義は「推移的関数従属が存在しない」です。推移的関数従属とはテーブル内に存在する段階的な従属関係です。
現状だと{id, ch_age}->{code_school}->{type}と段階的な従属性があるため第2正規化と同様に必要なデータが入力できません。
この従属性をなくすためにテーブルを更に分割します。これにより必要なデータ(中学校、大学院)も追加することができました。
2-4.ER図(Entity-Relationship Diagram)
正規化をするとテーブルが増え管理が難しくなるため見える化が必要です。各テーブルの関係を示す図をER図と呼びます。
ここでは用語のみの紹介であり今回のケースでは(多分)下記のような図になります。
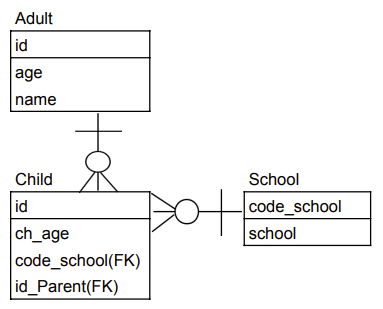
2-4.まとめ(自分流)
SQLでのテーブル作成時の注意点は下記の通りです。
【DB設計の注意点(自分用備忘録レベル)】
●基本的にはNULLが入らない設計とする。
ー>不要な列はつけない、または別テーブルとする
ー>NULLが一時的にでも入る可能性があるなら第2正規化
●ヒューマンエラーは起こりえるので入力間違いを防止
ー>Webアプリ(GUI)側で処置できるならする
ー>第2正規化を理解して実施する。
●第2・3正規化の理解は難しいが、入力し得るデータを全部考慮したうえでNULLが発生したり更新作業が手間になる場合は正規化しよう。
●DB作成時は自分だけで決めずにユーザー(部門メンバー)も含めて必要データの打ち合わせはした方がよい
3.SQLAlchemy:コード(外部キー設定なし)
まずは細かい説明を抜きにして正規化の動きを確認します。なお出力は作成した"HorizontalDisplay"を使用しますが見やすさの観点からOUTPUTの一部は切り取り加工しております。
3-1.サンプルデータ作成(Pandas)
今回使用するサンプルデータをPandasを用いて作成しました。後ほど下記データをfor文でDBに追加していきます。
[In]
import pandas as pdm
#Notebookに複数のDataFrameを(水平に)出力する
class HorizontalDisplay:
def __init__(self, *args):
self.args = args
def _repr_html_(self):
template = '<div style="float: left; padding: 10px;">{0}</div>'
return "\n".join(template.format(arg._repr_html_())
for arg in self.args)
parents =[
{'p_age':40, 'p_name':'A'},
{'p_age':30, 'p_name':'B'},
{'p_age':20, 'p_name':'C'},
]
children = [
{'ch_age':20, 'code_school': 'S005','id_Parent':1},
{'ch_age':17, 'code_school': 'S004','id_Parent':1},
{'ch_age':15, 'code_school': 'S004','id_Parent':1},
{'ch_age':10, 'code_school': 'S002','id_Parent':2},
{'ch_age':1, 'code_school': 'S001','id_Parent':2}
]
schools = [
{'code_school':'S000', 'type':'家'},
{'code_school':'S001', 'type':'保育園'},
{'code_school':'S002', 'type':'小学校'},
{'code_school':'S003', 'type':'中学校'},
{'code_school':'S004', 'type':'高校'},
{'code_school':'S005', 'type':'大学'},
{'code_school':'S006', 'type':'大学院'},
]
df_parent = pd.DataFrame(parents)
df_children = pd.DataFrame(children)
df_schools = pd.DataFrame(schools)
display(HorizontalDisplay(df_parent, df_children, df_schools))
[Out]
【class HorizontalDisplayについて】
PandasのDataFrame型をJupyterで横並びに表示させるためのクラスです。体裁を整えるためだけのため通常は記載不要です。
3-2.SQLAlchemyのコード(engine, session, table)
データベース作成のためのコードを記載します。今回はDBファイルは作成せずメモリ上('sqlite:///:memory:')で作成しました。
注意点として「relationshipにcascadeを設定していない」状態であり、これは別章で修正(追記)します。
[In]
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker, scoped_session, relationship
from sqlalchemy.orm import Session #データ型取得
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Table, Column, Integer, Float, String, DateTime, Boolean, ForeignKey #SQLテーブルのカラム設定用
from sqlalchemy import desc #降順ソート
import pandas as pd
from typing import Optional, List, Dict
engine = create_engine('sqlite:///:memory:', echo=True) #メモリ上にDB作成(一時的な処理用)
Session = scoped_session(
sessionmaker(
autocommit=False, #commit自動化の設定
autoflush=True, #flush自動化の設定
bind = engine
)
)
Base = declarative_base() #DB基底クラスの作成
Base.query = Session.query_property() #DBクエリの設定
class Parent(Base):
__tablename__ = 'parent' #テーブル名の作成
id = Column(Integer, primary_key=True) #データログid設定:主キー制約
age = Column(Float)
name = Column(String)
children = relationship('Child', backref='parent') #Childテーブルとのリレーション設定
def __init__(self, age, name):
self.age = age
self.name = name
class Child(Base):
__tablename__ = 'child' #テーブル名の作成
id = Column(Integer, primary_key=True) #データログid設定:主キー制約
ch_age = Column(Float)
code_school = Column(String, ForeignKey('school.code_school'))
id_Parent = Column(Integer, ForeignKey('parent.id')) #外部キー設定
# parents = relationship('Parent', backref='child') #backrefのため記載不要※back_populatesの場合は要記載
# schools = relationship('School', backref='child') #backrefのため記載不要※back_populatesの場合は要記載
def __init__(self, ch_age, code_school, id_Parent):
self.ch_age = ch_age
self.code_school = code_school
self.id_Parent = id_Parent
class School(Base):
__tablename__ = 'school'
code_school = Column(String, primary_key=True)
type = Column(String)
childen = relationship('Child', backref='school') #Parentクラスとの関連付け
def __init__(self, code_school, type):
self.code_school = code_school
self.type = type
def init_DB():
Base.metadata.create_all(bind=engine) #DB作成/初期化
init_DB()
[Out]
メモリ上にParent, Child, Schoolテーブルが作成されます。
※echo=Trueにしているため、詳細はそちらで確認のこと3-3.データ追加(INSERT):Session.add(instance)
前節で作成したテーブルにデータを追加していきます。
[In]
def insert_data():
for p in parents:
p_ins = Parent(p['age'], p['name'])
Session.add(p_ins)
for chl in children:
chl = Child(chl['ch_age'], chl['code_school'], chl['id_Parent'])
Session.add(chl)
for school in schools:
school = School(school['code_school'], school['type'])
Session.add(school)
Session.commit()
insert_data()
[Out]
サンプルデータを各テーブルに登録3-4.テーブル確認用関数:READ及びJOIN
動作確認用にテーブルを表示する関数を作成しました。テーブル同士の結合はSQL文で作成しております(参考資料の本をベースに作成)。
【関数の説明】
●showdfs():各テーブル(3つ)を表示
●showjoin_2tbl():ParentとChildを①INNER JOINと②OUTER JOINで結合
●showjoin_all():全テーブルを①INNER JOINと②OUTER JOINで結合
【JOINの説明】
JOINは別テーブルからほしい列を追加するための処理であり内部結合(INNER JOINと外部結合(OUTER JOIN)の2種類あります。
●INNER JOIN:結合テーブル同士の指定列における同じ値を結合する
ー>Cさんは子情報がないためデータがもれる。
●OUTER JOIN:片方のテーブル情報を全て出力したうえで結合
ー>Cさんの子情報はNULLで出力される。
[IN]
def showdfs():
df_P = pd.read_sql_query('SELECT * FROM parent', engine)
df_Chl = pd.read_sql_query('SELECT * FROM child', engine)
df_Sch = pd.read_sql_query('SELECT * FROM school', engine)
display(HorizontalDisplay(df_P, df_Chl, df_Sch))
showdfs()
[OUT]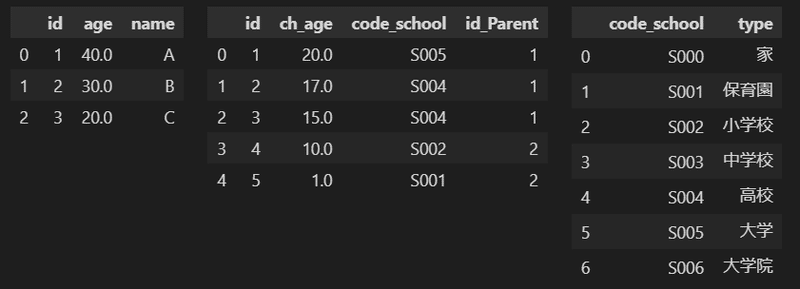
[IN]
def showjoin_2tbl():
df_INjoin = pd.read_sql_query('''SELECT chl.id, chl.ch_age, chl.code_school, chl.id_parent, P.age, P.name
FROM parent AS P INNER JOIN child AS chl
ON P.id = chl.id_Parent'''
, engine)
df_OUTjoin = pd.read_sql_query('''SELECT chl.id, chl.ch_age, chl.code_school, chl.id_parent, P.age, P.name
FROM parent AS P LEFT OUTER JOIN child AS chl
ON P.id = chl.id_Parent'''
, engine)
display(HorizontalDisplay(df_INjoin, df_OUTjoin))
showjoin_2tbl()
[OUT]
※OUTER JOINにおいてCさんのParentテーブル側のid(P.id)は3という数値がありますが、Child側に情報がないためid_ParentはNullになります。
[IN]
def showjoin_all():
df_INjoin = pd.read_sql_query('''SELECT chl.id, chl.ch_age, chl.code_school, chl.id_parent,
P.age, P.name, sch.type
FROM parent AS P INNER JOIN child AS chl
ON P.id = chl.id_Parent
INNER JOIN school As sch
ON sch.code_school = chl.code_school
''' , engine)
df_OUTjoin = pd.read_sql_query('''SELECT chl.id, chl.ch_age, chl.code_school, chl.id_parent,
P.age, P.name, sch.type
FROM parent AS P LEFT OUTER JOIN child AS chl
ON P.id = chl.id_Parent
LEFT OUTER JOIN school As sch
ON sch.code_school = chl.code_school
''' , engine)
display(HorizontalDisplay(df_INjoin, df_OUTjoin))
showjoin_all()
[OUT]
3-5.動作確認1:UPDATE
「Aさんの名前を変更(UPDATE)」した場合の動作を確認しました。
【結果】
●(正規化したテーブルでは)Parentテーブルの変更だけでほしいテーブル(結合テーブル)の情報がすべて更新されている
●正規化するとJOINの手間やパフォーマンスはデメリットだが、更新は非常に楽になる。
[In]
# データ更新
p1 = Session.query(Parent).filter(Parent.id == 1).first()
p1.name = "A変更"
Session.commit()
showdfs()
showjoin_all()
[OUT]

3-6.動作確認2:DELETE
次に「Aさんを削除(DELETE)」した場合の動作を確認しました。
【結果】
●ParentテーブルからはAさん情報が削除された(DELETE処理は正常終了)
●外部キーに設定しているChildテーブルのid_Parentは変更されていない(CASCADE処理を設定していないため)
●結合テーブルに関しては「結合キー」であるidがParentテーブルから削除されているため削除された情報は出力されない(id=1のデータがない)。


3-7.動作確認3:CREATE(※制約条件)
次に親テーブル(Parent, School)に存在しないデータを子テーブル(Child)に登録できるか確認しました。
【結果】
●Childテーブルには存在しないデータ(id=10)も登録できたー>現時点では制約(参照整合性制約)はかかっていない。
●親テーブルに無いidは結合されないため結合テーブルには表示されない。
[IN]
child_er = Child(100, 'S100', 10)
Session.add(child_er)
Session.commit()
showdfs()
showjoin_all()
[OUT]

4.SQLAlchemy:relation設定
前章で既に使用済みですがテーブル関係の設定に関して紹介します。
4-1.★外部キーの設定(SQLite)★
大前提として「SQLite v3.6.19まで外部キー制約が機能していない」です。よって旧式のSQLiteの場合は"engine.execute('PRAGMA foreign_keys = true;')"で機能をONにする必要があります。
[IN]
engine = create_engine('sqlite:///:memory:', echo=True)
engine.execute('PRAGMA foreign_keys = true;') #外部キー制約追加
[OUT]
制約追加4-2.relationship
relationship(relationも存在するがrelationshipと同義)は別テーブルとの紐づけ設定に使用され、テーブルの整合性を保つために重要な機能です。
記法としてrelationship("関連テーブルクラス名")とします。また引数は下記の通りです。
【relationshipの引数】
●back_populates/backref:関係するテーブルの1対多の相互関係を設定
->back_populates:親テーブル、子テーブル共にrelationshipの記載が必要。複数のrelationを設定する場合に使用
->backref:親テーブルのみへの記載だけでよい
●cascade:親テーブルが削除された時の子テーブルデータの更新方法を設定
[IN]
class Parent(Base):
__tablename__ = 'parent'
id = Column(Integer, primary_key=True)
children = relationship("Child", back_populates="parent")
class Child(Base):
__tablename__ = 'child'
id = Column(Integer, primary_key=True)
parent_id = Column(Integer, ForeignKey('parent.id'))
parent = relationship("Parent", back_populates="children")
[OUT]
※参考用コードのため出力無し4-3.ForeignKey(外部キー)
ForeignKey(外部キー)とは別テーブルを結合するときの”結合列”同士を紐づける設定となります。(前章では制約がかかっていませんが)外部キーを設定すると親テーブルには存在しないデータを子ファイルに登録できない(制約を課す)ように設定できます。
外部キーの記法はColumnの中にForeignKey('親テーブル名.属性')です。
【ForeignKeyの引数】
●'親テーブル名.属性':関連する属性情報を入力
●ondelete:多対多において親テーブル削除時の動作設定
->設定値:"CASCADE", "SET NULL" など
[IN]
class Parent(Base):
__tablename__ = 'parent' #テーブル名称:親テーブル
id = Column(Integer, primary_key=True)
children = relationship("Child") #適当な変数 = relationship("子テーブルクラス名")
class Child(Base):
__tablename__ = 'child' #テーブル名称:子テーブル
id = Column(Integer, primary_key=True)
parent_id = Column(Integer, ForeignKey('parent.id'))
[OUT]
※参考用コードのため出力無し4-4.CASCADE(カスケード)
カスケードは親テーブルのレコードが削除された時に、関連された子テーブルのデータの動作(そのまま、削除に合わせてNULL設定など)設定です。
理想として「子テーブルのデータを変更・削除してから親テーブルも更新」すればトラブルは避けられます。
記法はcascade="設定1, 設定2,・・"のようにカンマ区切りで文字列として入力します。
【cascadeの設定※デフォルト:cascade="save-update, merge"】
●save-update:Session.add()時の関連テーブル側のデータ追加設定
●merge:Session.merge()時の動作設定(※詳細は理解できなかった)
●delete:親テーブルのレコードが削除されたら子テーブルも削除される
●delete-orphan:リレーションの解除+オブジェクト削除
●refresh-expire:-
●expunge:-
(詳細は下記ブログ参照)
5.SQLAlchemy:コード(外部キー設定あり)
5-1.サンプルコード作成
前章でrelation設定をいろいろ記載しましたが、ここではengineオブジェクトの下に「engine.execute('PRAGMA foreign_keys = true;')」のみ追記して動作チェックします。
[IN]
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker, scoped_session, relationship
from sqlalchemy.orm import Session #データ型取得
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Table, Column, Integer, Float, String, DateTime, Boolean, ForeignKey #SQLテーブルのカラム設定用
from sqlalchemy import desc #降順ソート
import pandas as pd
from typing import Optional, List, Dict
engine = create_engine('sqlite:///:memory:', echo=True) #メモリ上にDB作成(一時的な処理用)
engine.execute('PRAGMA foreign_keys = true;') #SQLiteの外部キー制約をON
Session = scoped_session(
sessionmaker(
autocommit=False, #commit自動化の設定
autoflush=True, #flush自動化の設定
bind = engine
)
)
Base = declarative_base() #DB基底クラスの作成
Base.query = Session.query_property() #DBクエリの設定
class Parent(Base):
__tablename__ = 'parent' #テーブル名の作成
id = Column(Integer, primary_key=True) #データログid設定:主キー制約
age = Column(Float)
name = Column(String)
children = relationship('Child', backref='parent') #Childテーブルとのリレーション設定
# children = relationship('Child', backref='parent', cascade="all, delete-orphan") #Childテーブルとのリレーション設定
def __init__(self, age, name):
self.age = age
self.name = name
class Child(Base):
__tablename__ = 'child' #テーブル名の作成
id = Column(Integer, primary_key=True) #データログid設定:主キー制約
ch_age = Column(Float)
code_school = Column(String, ForeignKey('school.code_school', ondelete="SET NULL"))
id_Parent = Column(Integer, ForeignKey('parent.id', ondelete="SET NULL")) #外部キー設定
# parents = relationship('Parent', backref='child') #backrefのため記載不要※back_populatesの場合は要記載
# schools = relationship('School', backref='child') #backrefのため記載不要※back_populatesの場合は要記載
def __init__(self, ch_age, code_school, id_Parent):
self.ch_age = ch_age
self.code_school = code_school
self.id_Parent = id_Parent
class School(Base):
__tablename__ = 'school'
code_school = Column(String, primary_key=True)
type = Column(String)
childen = relationship('Child', backref='school') #Parentクラスとの関連付け
# childen = relationship('Child', backref='school', cascade="all, delete-orphan") #Parentクラスとの関連付け
def __init__(self, code_school, type):
self.code_school = code_school
self.type = type
def init_DB():
Base.metadata.create_all(bind=engine) #DB作成/初期化
init_DB()
[OUT]
メモリ上にDB作成[IN]※上記実行でDBがリセットされるためデータ追加を再実施
def insert_data():
for p in parents:
p_ins = Parent(p['age'], p['name'])
Session.add(p_ins)
for chl in children:
chl = Child(chl['ch_age'], chl['code_school'], chl['id_Parent'])
Session.add(chl)
for school in schools:
school = School(school['code_school'], school['type'])
Session.add(school)
Session.commit()
insert_data()
[OUT]
データが追加(CREATE)5-2.動作確認1:UPDATE
「Aさんの名前を変更(UPDATE)」した場合の動作を確認しました。
【結果】
●外部キー制約設定前と変化なし。
●(正規化したテーブルでは)Parentテーブルの変更だけでほしいテーブル(結合テーブル)の情報がすべて更新されている
●正規化するとJOINの手間やパフォーマンスはデメリットだが、更新は非常に楽になる。
[IN]
# データ更新
p1 = Session.query(Parent).filter(Parent.id == 1).first()
p1.name = "A変更"
Session.commit()
showdfs(), showjoin_all()
[OUT]

5-3.動作確認2:DELETE
次に「Aさんを削除(DELETE)」した場合の動作を確認しました。
【結果】
●結合されたテーブルは(正規化されているため)外部キー設定前と変化がないが、Childに設定した外部キーにカスケードが実行された。
●ParentテーブルからはAさん情報が削除され、それに連動して外部キーに設定しているChildテーブルのid_ParentがNULLになった。
●結合テーブルはidがParentテーブルから削除されているため削除された情報は出力されない(id=1のデータがなくNULLは結合されない)。


5-4.動作確認3:CREATE(※制約条件)
次に親テーブル(Parent, School)に存在しないデータを子テーブル(Child)に登録できるか確認しました。
【結果】
●Childテーブルには存在しないデータ(id=10)は登録できない
●外部キー制約(参照整合性制約)がかかり、データの整合性がとれる
[IN]
child_er = Child(100, 'S100', 10)
Session.add(child_er)
Session.commit()
showdfs(), showjoin_all()
[OUT]
IntegrityError: (sqlite3.IntegrityError) FOREIGN KEY constraint failed
[SQL: INSERT INTO child (ch_age, code_school, "id_Parent") VALUES (?, ?, ?)]
[parameters: (100.0, 'S100', 10)]
(Background on this error at: https://sqlalche.me/e/14/gkpj)6.まとめ(自分用)
最後に備忘録用のまとめです。
【DB設計の注意点(自分用備忘録レベル)】
●基本的にはNULLが入らない設計とする。
ー>不要な列はつけない、または別テーブルとする
ー>NULLが一時的にでも入る可能性があるなら第2正規化
●ヒューマンエラーは起こりえるので入力間違いを防止
ー>Webアプリ(GUI)側で処置できるならする
ー>第2正規化を理解して実施する。
●第2・3正規化の理解は難しいが、入力し得るデータを全部考慮したうえでNULLが発生したり更新作業が手間になる場合は正規化しよう。
●DB作成時は自分だけで決めずにユーザー(部門メンバー)も含めて必要データの打ち合わせはした方がよい
【SQLAlchemyの注意点】
●(なぜか色々な記事には記載がないのだが)SQLiteで外部キーを使用するなら「engine.execute('PRAGMA foreign_keys = true;') 」の設定は必要?
●まずは正規化をしっかりしてわかりやすいテーブルを作ること
●テーブル結合時にカラム名(列名)は重要なため十分に事前検討
7.番外編:Pandasによるデータ結合
メイン記事の説明ではSQL文のJOINを使用したデータ結合を実施しましたが参考までにPandasでも同様の結合ができることを紹介します。
データは本編でも使用した下記を使用します。
[IN]
import pandas as pd
df_P = pd.read_sql_query('SELECT * FROM parent', engine)
df_Chl = pd.read_sql_query('SELECT * FROM child', engine)
df_Sch = pd.read_sql_query('SELECT * FROM school', engine)
display(HorizontalDisplay(df_P, df_Chl, df_Sch))
[OUT]
7-1.df.merge()の記法
DataFrameの結合はdf.merge()メソッドを使用します。記法としては2種ありますがどちらでも対応可能です。
[記法1:df.merge()]
df1.merge(df2, how = <結合方法>, on = ”結合キー”)
[記法2:pd.merge()]
pd.merge(df1, df2, how = <結合方法>, on = ”結合キー”)【pd.mergeの引数】
●how:結合方法(内部結合、外部結合など)を指定
ー>{‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}, default ‘inner’
ー>left:LEFT OUTER JOIN、inner:INNER JOINと同等
●on:結合キー用カラムの指定 ※結合するDataFrameに同じ名前のカラム名がある場合のみ使用可能
●left_on:結合キー用カラムの指定(LEFT側)
●right_on:結合キー用カラムの指定(RIGHT側)
●suffixes:結合時のカラム名への"接尾語"を指定
●sort:結合キーをソート(bool, default False)
7-2.実践コード1:内部結合(INNER JOIN)
7-2-1.接続キー名が異なるテーブルの結合
内部結合はhow='inner'を使用します。howのデフォルトが'inner'のため下記で実行可能です。df.merge()では結合時に使用したカラム名の後ろに自動で接尾語として'_x', '_y'が接続されます。
[IN]
df = df_P.merge(df_Chl, left_on='id', right_on='id_Parent')
# pd.merge(df_P, df_Chl, left_on='id', right_on='id_Parent') #同上
df
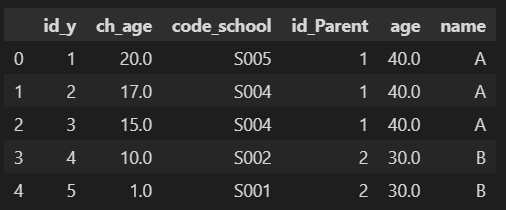
df[['id_y', 'ch_age', 'code_school', 'id_Parent', 'age', 'name']] #表示カラムを指定
[OUT]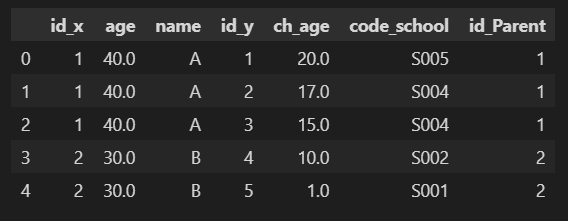
【注意事項】
引数のsuffixesを使用して接尾語を変更可能ですが、接尾語そのものをなくそうとすると「カラム名の重複」でエラーが出ます。
[In]
df_P.merge(df_Chl, left_on='id', right_on='id_Parent', suffixes=(False, False))
[OUT]
ValueError: columns overlap but no suffix specified: Index(['id'], dtype='object')7-2-2.接続キー名が同じ(揃えた)テーブルの結合
接尾語が邪魔だと感じる場合は①親テーブルと子テーブルのカラム名を統一、②df.merge(on='接合キー')を使用します。
※もともと両テーブルの接続キー名が同じ場合も下記記法で実行できます。
[IN]
df_P = df_P.rename(columns={'id':'id_Parent'}) #df_Pのカラム名をid->id_Parentに変更
df_P.merge(df_Chl, on='id_Parent') #id_Parentを指定してマージ
[OUT]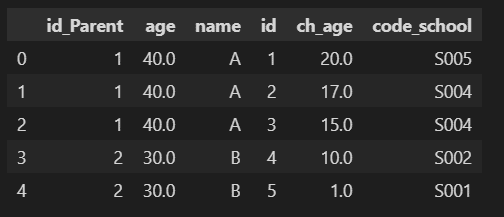
7-2-3.必要なカラムを抽出して結合
結合時に必要なカラムを抽出するなら、結合時にdf[['col1', 'col2',・・・]]のようにDataFrameから必要なカラムを事前に選択します。
[IN]
df_P = df_P.rename(columns={'id':'id_Parent'}) #df_Pのカラム名をid->id_Parentに変更
df_P.merge(df_Chl[['id', 'id_Parent']], on='id_Parent') #Childのidとid_Parentのみ抽出ー>id_Parentで結合
[OUT]
7-2-4.複数(3つ以上)のテーブルを結合
すべてを応用して3つのテーブルを結合します。
[IN]
df_P = df_P.rename(columns={'id':'id_Parent'}) #df_Pのカラム名をid->id_Parentに変更
_df = df_P.merge(df_Chl, on='id_Parent') #id_Parentを指定してマージ
df = _df.merge(df_Sch, on='code_school') #code_schoolを指定してマージ
df
[OUT]
7-3.実践コード:外部結合(OUTER JOIN)
7-3-1.接続キー名が異なるテーブルの結合
外部結合の記法は内部結合と同じであり、how='left'を設定します。
[IN]
import pandas as pd
df_P = pd.read_sql_query('SELECT * FROM parent', engine)
df_Chl = pd.read_sql_query('SELECT * FROM child', engine)
df_Sch = pd.read_sql_query('SELECT * FROM school', engine)
df = df_P.merge(df_Chl, left_on='id', right_on='id_Parent', how='left')
display(df)
[OUT]
7-3-2.接続キー名が同じ(揃えた)テーブルの結合
こちらも同様に①親テーブルと子テーブルのカラム名を統一、②df.merge(on='接合キー')、③how='left' とします。
[IN]
df_P = df_P.rename(columns={'id':'id_Parent'}) #df_Pのカラム名をid->id_Parentに変更
df_P.merge(df_Chl, on='id_Parent', how='left') #Childのidとid_Parentのみ抽出ー>id_Parentで結合
[OUT]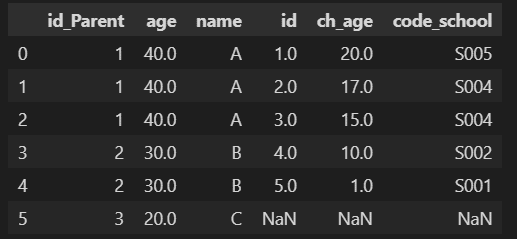
7-2-3.複数(3つ以上)のテーブルを結合
すべてを応用して3つのテーブルを結合します。
[IN]
df_P = df_P.rename(columns={'id':'id_Parent'}) #df_Pのカラム名をid->id_Parentに変更
_df = df_P.merge(df_Chl, on='id_Parent', how='left') #Childのidとid_Parentのみ抽出ー>id_Parentで結合
df = _df.merge(df_Sch, on='code_school', how='left') #code_schoolを指定してマージ
df
[OUT]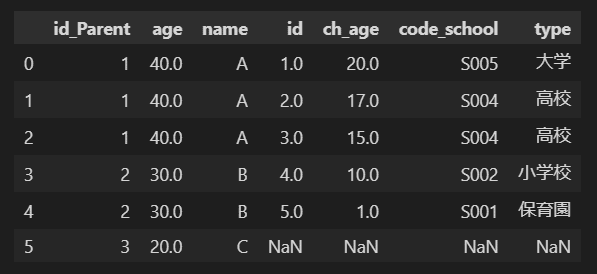
参考資料
あとがき
いろいろ調べながら変なところをぐるぐる回ったため体系的にまとめられていない可能性が高いです。
とりあえず使えるところまで行ったのでいったん投稿。
この記事が気に入ったらサポートをしてみませんか?