
Python基礎13:正規表現(regular expression):re

0.概要
Pythonの標準ライブラリである"re"を使用して正規表現を扱います。標準ライブラリのため環境構築などは不要です。
なお文字列操作は完全に理解しているものとして進めます。
0-1.サンプルデータ
本記事で使用するサンプルデータとして下記使用しました。
【データ1:AV女優のリスト】
データ数は最大8個であり(年齢、身長、カップ数、バスト、ウエスト、ヒップ、血液型、出身地)です。
データには欠損値があり、データがない部分部分は左埋め(Noneは無し)
[IN]
['桃乃りん\nもものりん\n19',
'逢月ひまり\nあいづきひまり\n20 155 88 60 86 兵庫県',
'合原槻羽\nあいはらきう\n20 C 85 58 86 福岡県',
'小倉七海\nおぐらななみ\n20 161 92 58 88 A',
'七咲みいろ\nななさきみいろ\n20 156 E 86 58 89',
'花柳杏奈\nはなやぎあんな\n20 151 G 97 59 93 奈良県',
'神木蘭\nかみきらん\n20 163 E 86 54 84 兵庫県',
'朝田ひまり\nあさだひまり\n20 147 G 84 56 81 B 宮城県',
'横宮七海\nよこみやななみ\n20 154 E 88 58 84',
'小野六花\nおのりっか\n20 148 C 84 58 86']
[OUT]
-【データ2:CIF(Crystallograhic Information File)】
CIFとは”国際結晶学連盟が推奨している結晶学情報共通データ・フォーマット”であり、結晶構造データと特定の形で保存したもの
データは1個のStringに格納されている
データ元はMaterial Projectですが、データ自体はNishikaのコンペを参照しました。
[IN]
raw_cif = """# generated using pymatgen\r\n
data_K2MgMo2(H2O5)2\r\n
_symmetry_space_group_name_H-M 'P 1'\r\n
_cell_length_a 6.00896235\r\n
_cell_length_b 6.55026940\r\n
_cell_length_c 7.95639355\r\n
_cell_angle_alpha 111.39242719\r\n
_cell_angle_beta 96.77130034\r\n
_cell_angle_gamma 109.07338782\r\n
_symmetry_Int_Tables_number 1\r\n
_chemical_formula_structural K2MgMo2(H2O5)2\r\n
_chemical_formula_sum 'K2 Mg1 Mo2 H4 O10'\r\n
_cell_volume 265.39072919\r\n
_cell_formula_units_Z 1\r\n
loop_\r\n
_symmetry_equiv_pos_site_id\r\n
_symmetry_equiv_pos_as_xyz\r
\n
1 'x, y, z'\r\n
loop_\r\n
_atom_site_type_symbol\r\n
_atom_site_label\r\n
_atom_site_symmetry_multiplicity\r\n
_atom_site_fract_x\r\n
_atom_site_fract_y\r\n
_atom_site_fract_z\r\n
_atom_site_occupancy\r\n
K K0 1 0.33066327 0.70285292 0.24630803 1\r\n
K K1 1 0.66933673 0.29714708 0.75369197 1\r\n
Mg Mg2 1 -0.00000000 -0.00000000 -0.00000000 1\r\n
Mo Mo3 1 0.33274891 0.66534980 0.76077634 1\r\n
Mo Mo4 1 0.66725109 0.33465020 0.23922366 1\r\n
H H5 1 0.92202881 0.86654805 0.28439073 1\r\n
H H6 1 0.07797119 0.13345195 0.71560927 1\r\n
H H7 1 0.12465733 0.12755969 0.37626561 1\r\n
H H8 1 0.87534267 0.87244031 0.62373439 1\r\n
O O9 1 0.36066563 0.82312200 0.62054963 1\r\n
O O10 1 0.63933437 0.17687800 0.37945037 1\r\n
O O11 1 0.23666938 0.34989125 0.61648940 1\r\n
O O12 1 0.76333062 0.65010875 0.38351060 1\r\n
O O13 1 0.62693462 0.76248819 0.92136504 1\r\n
O O14 1 0.37306538 0.23751181 0.07863496 1\r\n
O O15 1 0.10929347 0.70888614 0.89009389 1\r\n
O O16 1 0.89070653 0.29111386 0.10990611 1\r\n
O O17 1 0.05337462 0.97851338 0.25767835 1\r\n
O O18 1 0.94662538 0.02148662 0.74232165 1\r\n
"""
[OUT]
-0-2.raw文字列
正規表現では様々な記号を使用するため(特にWindowsでは)直接記載するとエスケープシーケンスと混在してしまいエラーが発生する恐れがあります。それを避けるために、使用する記号をすべて文字列として扱う処理としてraw文字列があります。
記法としては文字列の頭にrをつけるだけとなります。
[IN]
esc_seq = "\\n : 改行\\r : キャリッジリターン\\t : タブ\\\\ : バックスラッシュ\\\" : ダブルクォーテーション\\\' : シングルクォーテーション"
print(esc_seq)
esc_raw = r"\\n : 改行\\r : キャリッジリターン\\t : タブ\\\\ : バックスラッシュ\\\" : ダブルクォーテーション\\\' : シングルクォーテーション"
print(esc_raw)
[OUT]
\n : 改行\r : キャリッジリターン\t : タブ\\ : バックスラッシュ\" : ダブルクォーテーション\' : シングルクォーテーション
\\n : 改行\\r : キャリッジリターン\\t : タブ\\\\ : バックスラッシュ\\\" : ダブルクォーテーション\\\' : シングルクォーテーション1.正規表現
正規表現とは「ある文字の並び(文字列)を表現する一つの方式」です。
データを抽出する時にテキストデータで情報が固まっていることが多いため、正規表現により文字列の中からほしい情報を抽出することが出来ます。
reライブラリを触る前に正規表現の記法を簡単に説明します。
1-1.正規表現の特殊文字
正規表現ではテキストを条件抽出するために、各種記号に意味を持ちます。その特殊文字に関して一覧は下記の通りです。
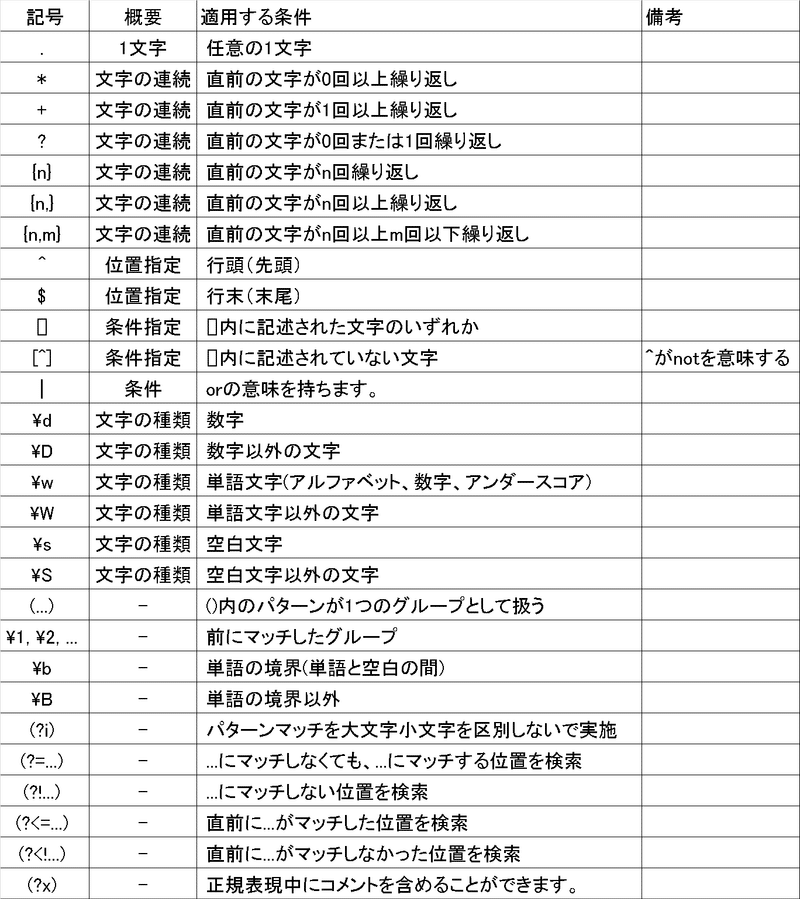
2.re基礎:テキスト処理
reでは文字列処理と同様にテキストを処理することが出来ます。詳細は公式Docsの"関数"をご確認ください。
2-1.テキスト分割:re.split()
指定した文字でテキストを分割する場合は"re.split()"を使用します。
re.split(pattern, string, maxsplit=0, flags=0)下記サンプルでは改行("\n")で文字列を分割してみました。分割後はListとして出力されます。
[IN]
girl = girlsinfo[6]
#テキストを改行(\n)で分割
display(girl)
datas_kamiki = re.split('\n', girl)
print(datas_kamiki)
[OUT]
'神木蘭\nかみきらん\n20 163 E 86 54 84 兵庫県'
['神木蘭', 'かみきらん', '20 163 E 86 54 84 兵庫県']今回は簡単な例として改行で分割しましたがpattern部分を正規表現で記載することも可能です。例として文字列:"0a3B9"に対して”aからfの文字を1個以上含む箇所で分割”という正規表現を与えると下記の通りに分割します。またflagをつけると大文字小文字の違いも自動で処理してくれます。
[IN]
_text = '0a3B9'
out = re.split('[a-f]+', _text)
out_ignorecase = re.split('[a-f]+', _text, flags=re.IGNORECASE)
print(out)
print(out_ignorecase)
[OUT]
['0', '3B9']
['0', '3', '9']2-2.テキスト置換:re.sub()
指定した文字でテキストを置換する場合は"re.sub()"を使用します。
re.sub(pattern, repl, string, count=0, flags=0)例えば名字が変更したとして、”re.sub(<検索文字>, <置換後文字>, String )”で置換可能です。
[IN]
name_kamiki = datas_kamiki[0]
print(name_kamiki)
re.sub('神木', 'XYZ', name_kamiki)
[OUT]
神木蘭
'XYZ蘭're.sub()も検索条件においてpattern部分を正規表現で記載することも可能です。サンプルのカップ数をE->Fに変更する際に”AからZ内の文字列を抽出”する正規表現を記載して、その値を指定文字に変更しました。
[IN]
info_kamiki = datas_kamiki[2]
print(info_kamiki)
re.sub(r'[A-Z]', 'F', info_kamiki)
[OUT]
20 163 E 86 54 84 兵庫県
'20 163 F 86 54 84 兵庫県'3.re基礎:テキストの検索・抽出
3-1.文字列の先頭から1個検索:re.match()
正規表現で文字列検索する関数は"re.match()"と"re.search()"があります。
re.match(pattern, string, flags=0) "re.match()"は「文字列の先頭」がパターンにマッチするかを調べます。
出力はオブジェクトで出力され中には(文字列のindex, マッチした文字列)が出力されます。また抽出した文字列も出力可能です。
[IN]
aiduki = re.split('\n', girlsinfo[1])[0]
kamiki = re.split('\n', girlsinfo[6])[0]
asada = re.split('\n', girlsinfo[7])[0]
girlsname = [aiduki, kamiki, asada]
for girlname in girlsname:
print(girlname)
match = re.match(r'神木', girlname)
print(match)
print(re.match(r'神木', kamiki)[0])
[OUT]
逢月ひまり
None
神木蘭
<re.Match object; span=(0, 2), match='神木'>
朝田ひまり
None
神木3-2.文字列内から1個検索:re.search()
"re.search()"は対象の文字列のどこかに正規表現パターンを含むかどうかを調べます。match()は文章の先頭ですが、search()は文全体で検索します。
re.search(pattern, string, flags=0)検索条件として正規表現で”AからZを含む”としております。注意点は下記の通りです。
出力値はオブジェクトであり、値が存在しない場合はNoneを出力
抽出できる値が複数あっても、抽出されるのは一番最初に検索された値である。(※複数抽出するなら次節のfindall()を使用)
[IN]
aiduki = re.split('\n', girlsinfo[1])[2] #2データ欠損(カップ数・血液型:両方アルファベット)
kamiki = re.split('\n', girlsinfo[6])[2] #1データ欠損(血液型)
asada = re.split('\n', girlsinfo[7])[2] #全データ(8次元)あり
infos = [aiduki, kamiki, asada]
for info in infos:
print(info)
#アルファベットがあるか確認
search = re.search(r'[A-Z]', info)
print(search)
[OUT]
20 155 88 60 86 兵庫県
None
20 163 E 86 54 84 兵庫県
<re.Match object; span=(7, 8), match='E'>
20 147 G 84 56 81 B 宮城県
<re.Match object; span=(7, 8), match='G'>3-3.文字列内の複数検索:re.findall()
抽出条件に当てはまる全値をリストで抽出する場合は”re.findall()”を使用します。
re.findall(pattern, string, flags=0)検索条件として正規表現で”AからZを含む”としております。注意点は下記の通りです。
出力値はリストであり、値が存在しない場合は空リストを出力
抽出できる値が複数あるなら全データをリストに格納して出力
[IN]
aiduki = re.split('\n', girlsinfo[1])[2] #2データ欠損(カップ数・血液型:両方アルファベット)
kamiki = re.split('\n', girlsinfo[6])[2] #1データ欠損(血液型)
asada = re.split('\n', girlsinfo[7])[2] #全データ(8次元)あり
infos = [aiduki, kamiki, asada]
for info in infos:
print(info)
#アルファベットがあるか確認
allinfo = re.findall(r'[A-Z]', info)
print(allinfo)
[OUT]
20 155 88 60 86 兵庫県
[]
20 163 E 86 54 84 兵庫県
['E']
20 147 G 84 56 81 B 宮城県
['G', 'B']3-4.検索するイテレータ出力:re.finditer()
基本的には”re.findall()”と同じであり検索した値を複数出力可能です。出力値はyieldでのイテレータのためメモリ節約にはなると思います。
re.finditer(pattern, string, flags=0)検索条件として正規表現で”AからZを含む”としております。注意点は下記の通りです。
出力値はイテラブルなオブジェクトであり、値が存在しない場合でもオブジェクトが出力されます。
オブジェクトは(イテラブルのため)for文などで抽出できます
値はgroup()メソッドで取得可能です。
[IN]
aiduki = re.split('\n', girlsinfo[1])[2] #2データ欠損(カップ数・血液型:両方アルファベット)
kamiki = re.split('\n', girlsinfo[6])[2] #1データ欠損(血液型)
asada = re.split('\n', girlsinfo[7])[2] #全データ(8次元)あり
infos = [aiduki, kamiki, asada]
for info in infos:
print("="*50)
print(info)
#アルファベットがあるか確認
iters = re.finditer(r'[A-Z]', info)
print('iterator:', iters)
for i in iters:
print(i) #マッチした文字列の位置を取得
print('span():', i.span()) #マッチした文字列の位置を取得
print('group():', i.group()) #マッチした文字列を取得
[OUT]
==================================================
20 155 88 60 86 兵庫県
iterator: <callable_iterator object at 0x000001FB15A1B7F0>
==================================================
20 163 E 86 54 84 兵庫県
iterator: <callable_iterator object at 0x000001FB13C92400>
<re.Match object; span=(7, 8), match='E'>
span(): (7, 8)
group(): E
==================================================
20 147 G 84 56 81 B 宮城県
iterator: <callable_iterator object at 0x000001FB15A1BDF0>
<re.Match object; span=(7, 8), match='G'>
span(): (7, 8)
group(): G
<re.Match object; span=(18, 19), match='B'>
span(): (18, 19)
group(): B4.予備章
予備
5.実践編:正規表現でデータ抽出
複数のパターンを記載しながら正規表現の記法を学びます。基礎は前述の通り下記を参照します。
5-1.例1_数値(整数と小数点)を抽出:\d+\.\d+|\d+
まずはサンプルテキストを取得しました。
[IN]
ciflists = re.split(r'\r\n\n', raw_cif)
ciflists = [i.strip() for i in ciflists]
ciflists = [i for i in ciflists if not i.startswith('_')]
ciflists = [i for i in ciflists if not i.startswith('#')]
ciflists = ciflists[3:]
cif = ciflists[0]
[OUT]
'K K0 1 0.33066327 0.70285292 0.24630803 1'今回は整数と小数点だけをリストで取得します。思想は下記の通りであり、正規表現は”\d+\.\d+|\d+”になります。
記号として、数値:"\d"と任意の1文字:"."を使用します。
失敗例1として、"\d"だけだとK0の0を取得したり、小数点の"."前後の数値を分けて取得します。よって小数点抽出には<数値+小数点+数値>の正規表現が必要です。これは”\d+\.\d+”となります。
失敗例2として、”\d+\.\d+”だけだと小数点だけが抽出されるため整数も取得できるようにします。よって条件orとして”|”を使用します。
[IN] #整数と小数点を抽出
re.findall(r'\d+\.\d+|\d+', cif)
[OUT]
['0', '1', '0.33066327', '0.70285292', '0.24630803', '1']参考記事
あとがき
苦手意識あったけど、やっぱ慣れは必要
この記事が気に入ったらサポートをしてみませんか?