
Pythonライブラリ(SQL):SQLAlchemy

概要
SQLAlchemyの紹介
PythonのO/RマッパーでSQLを操作できるSQLAlchemyを紹介します。他のPythonライブラリとの連動もしやすいため非常に便利なライブラリです。
[Terminal]
pip instal sqlalchemyO/Rマッパーのメリット/デメリット
O/Rマッパーのメリット/デメリットの記事を参考に貼っておきます。
サンプルデータ
なおサンプルデータは下記を使用していきます。
[IN]
import pandas as pd
import numpy as np
from sklearn import datasets
np.random.seed(0) #乱数値を固定
idx_random = np.random.randint(0, len(datasets.load_iris().data), size=10) #乱数で10個のインデックスを取得->array([ 47, 117, 67, 103, 9, 21, 36, 87, 70, 88])
iris = datasets.load_iris() #Irisデータセットを読み込み
columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] #列名指定※半角スペースやカッコはエラーになるため除去
df_data, df_label = pd.DataFrame(iris.data, columns=columns), pd.DataFrame(iris.target, columns=['id_label'])
df_data = pd.concat([df_data, df_label], axis=1) #dataにラベルを追加
df_label['labelname'] = df_label['id_label'].map({0: 'setosa', 1: 'versicolor', 2: 'virginica'}) #ラベルを数値から文字列に変換
df_data, df_label = df_data.iloc[idx_random, :], df_label.iloc[idx_random, :] #ランダムに10個データを取得
display(df_data, df_label)
print(df_data.shape, df_label.shape) #各DataFrameの形状(データ数とカラム数)を確認
[Out]
(10, 5) (10, 2)
DataFrame詳細は下記参照
1.DBの設定
SQLAlchemyではDBと連携するためのengineオブジェクトを作成してSessionでengineとDBをつなぐことで操作できます。
本記事ではSQLはsqliteを使用していきます。
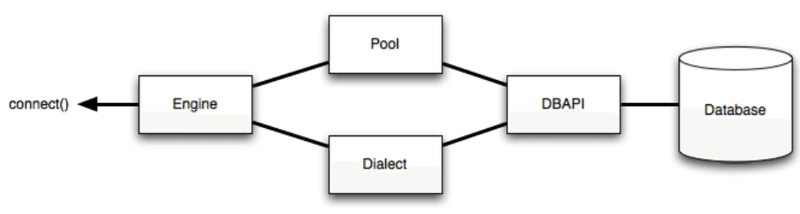
1-1.DB設定/engine作成:create_engine(DBpath)
まず初めにDB接続のためにDBファイルのパスをengineオブジェクトに指定します。
[In]
from sqlalchemy import create_engine
DB_file = 'note_irisdata.db'
engine = create_engine('sqlite:///' + DB_file) #DB接続の設定
engine
[Out]
Engine(sqlite:///note_irisdata.db)【create_engineの引数】
●echo (defalut:False):SQLを実行時にターミナルに処理内容を表示します。
●connect_args:辞書型形式で特定のパラメータを調整できます。
●pool_recycle:MySQLで接続する時のエラー回避用っぽい(Qiita)
(設定無しでも使用可能ですが)sqlite3を使用時に"check_same_thread"という引数を設定できます(※他のDBでは設定不要)。
設定の内容は追って追記(下記公式Docsを見ても理解できない)
[In]
from sqlalchemy import create_engine
DB_file = 'note_irisdata.db'
engine = create_engine('sqlite:///' + DB_file,
connect_args = {"check_same_thread":False}) #DB接続の設定
engine
[Out]
Engine(sqlite:///note_irisdata.db #同上1-2.DBへの接続設定:sessionmaker()
次にDB接続の設定としてsessionmaker()に条件およびengineを渡して、DB接続のためのオブジェクト(Session)を作成します。
Sessionの作成方法は複数(Qiita:SQLAlchemyのSession生成方法)ありますがここではsessionmakerを使用しました。
【sessionmakerの引数】
●bind:エンジンまたは接続可能なSessionオブジェクト
●autoflush: flushの自動化の設定(SQLAlchemy flush(), commit()の違い)
->データ変更(CREATE, UPDATE, DELETE)後に呼び出し(READ)可能
->rollback()でデータ変更操作を元に戻すことができる
->commit()せずにDB切断すると実際にDBにデータは保存されない
●autocommit:commitの自動化の設定
->データ変更(CREATE, UPDATE, DELETE)後に呼び出し(READ)可能 -
->rollback()でデータ変更操作を戻せずDBデータが更新される。
●class_(Defalusts=Session): 新規Sessionオブジェクト作成用クラス
●expire_on_commit=True:Session.expire_on_commitの設定用
●info : ー(意味は公式参照のこと)
[In]
from sqlalchemy.orm import sessionmaker, scoped_session
Session = scoped_session(
sessionmaker(
autocommit=False, #commit自動化の設定
autoflush=False, #flush自動化の設定
bind = engine
)
)
Session
[Out]
<sqlalchemy.orm.scoping.scoped_session at 0x214e07f87f0>1-3.DBテーブル用のクラス作成:declarative_base()
次の章でDBテーブル用クラスを作成しますが、クラスを継承させてORMと連携させるためのオブジェクト(Base)を作成します。
[In]
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base() #DB基底クラスの作成
Base.query = Session.query_property() #DBクエリの設定Session.query_property()はなくても使用できますが、設定しておくと下記の通り作成した(テーブル)クラスから直接クエリを読み込めます。
[参考コード]
db = Session.query(Iris).all() #DBからデータを取得
db = Iris.query.all() #Session.query_property()の設定で使用可能1-4.まとめコード
1章のまとめコードは下記の通りです。
[In]
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker, scoped_session
from sqlalchemy.ext.declarative import declarative_base
DB_file = 'note_irisdata.db'
engine = create_engine('sqlite:///' + DB_file) #DB接続の設定
Session = scoped_session(
sessionmaker(
autocommit=False, #commit自動化の設定
autoflush=False, #flush自動化の設定
bind = engine
)
)
Base = declarative_base() #DB基底クラスの作成
Base.query = Session.query_property() #DBクエリの設定2.テーブルクラスの定義:class(Base)
DBの設定完了後はテーブル設計を実施します。テーブルに必要な設定は通常のSQLと基本的には同じになります。
2-1.DBテーブルの作成:Column()
DBとPythonで作成した(テーブル用)オブジェクトを紐づけるためにBaseを継承してクラスを作成します。大まかな作成要領は下記の通りです。
idはデータ照合用のカラムとして設定しますがprimary_key=Trueを設定すると自動でautoincrement機能が入るため__init__(self)での設定は不要です。
[In]
from sqlalchemy import Column, Integer, Float, String, DateTime, ForeignKey #SQLテーブルのカラム設定用
class クラス名(Base):
__tablename__ = 'テーブル名' #テーブル名の設定
id_xx = Column(Integer, primary_key=True) #idの設定
col1 = Column(カラムの型) #カラム名の設定
def __init__(self, col1): #初期化
self.col1 = col1 #インスタンス変数の設定Column()に設定できる引数はたくさんありますので一部を紹介します。
【Column()の引数一覧】
●primary_key:主キー制約の設定
->複合Keyにしたい場合は複数の変数(カラム)に設定
->主キーは暗黙にNOT NULL制約・一意制約がかかる
●ForeignKey('tablename.column', ondelete):外部キーの設定
->親テーブルの設定はテーブル名(クラス名ではない)
->ondeleteは設定した親テーブルが削除された時の動作を設定する。
●SET NULL:親テーブル削除時にNULL、CASCADE:追って
●index:indexを割り当てる(※十分に調べきれなかったため追って修正)
●unique:一意制約を設定:Trueにすると重複データの入力を制限
->主キー制約は1テーブルにつき1つだが一意制約は何個でも可能
●nullable:NOT NULL制約を設定(False=Not Nullと同じ動作)
●autoincrement:連番を自動で入力する機能を設定
2-2.テーブルの詳細設定:__table_args__
テーブル名はBaseを継承したクラスの"__tablename__"で設定しますが、テーブルの詳細を設定する場合は”__table_args__”を使用します。
【__table_args__の引数一覧】
●ForeignKeyConstraint:外部キー制約を設定
●UniqueConstraint:ユニーク制約の設定
●UniqueConstraint:複数カラムにユニーク制約(Qiita記事)
※十分に理解できていないため追って修正
2ー3.テーブルクラスの実装(サンプル)
前節をもとにテーブルクラスを2つ作成しました。
[In]
from sqlalchemy import Column, Integer, Float, String, DateTime, ForeignKey #SQLテーブルのカラム設定用
class Iris(Base):
__tablename__ = 'Iris' #テーブル名の作成
id = Column(Integer, primary_key=True) #データログid設定:主キー制約
sepal_length = Column(Float)
sepal_width = Column(Float)
petal_length = Column(Float)
petal_width = Column(Float)
id_label = Column(Integer, ForeignKey('Label_iris.id_label')) #外部キー設定
def __init__(self, sepal_length, sepal_width, petal_length, petal_width, id_label):
self.sepal_length = sepal_length
self.sepal_width = sepal_width
self.petal_length = petal_length
self.petal_width = petal_width
self.id_label = id_label
class Label_iris(Base):
__tablename__ = 'Label_iris' #テーブル名の作成
id_label = Column(Integer, primary_key=True, unique=True) #データログid設定:主キー制約
labelname = Column(String, unique=True) #ラベル名
def __init__(self, id_label, labelname):
self.id_label = id_label
self.labelname = labelname参考までにSQL文でのテーブル定義(+作成)は下記の通りです。
[SQL:テーブル作成]
CREATE TABLE <テーブル名>
(<列名1> <データ型> <列名1へのデータ制約>
<列名2> <データ型> <列名2へのデータ制約>
<列名3> <データ型> <列名3へのデータ制約>
・
・
・
);3.DB操作
3-1.DB初期化/テーブル作成:CREATE TABLE
DBファイル及びテーブルの作成をBase.metadata.create_all(bind=engine)で実行します。これでDBファイルの作成が完了しました。
[In]
def init_DB():
Base.metadata.create_all(bind=engine) #DB作成/初期化
init_DB()
[Out]
下記参照
3-2.クエリ(SQL文)の実行:Session.query()
DBにSQL操作をする場合はsessionmaker()で作成したSessionのqueryメソッドを使用します。
[In]※参考例
Session.query(<設定したテーブルclass>).method()
[Out]
※初期ではデータ登録していないため出力無しまた前述の通り”Session.query_property()”を設定しておくことでクラスからプロパティの様な処理(queryの後ろに"()"は不要)も可能です。
[In]※参考例
<設定したテーブルclass>.query.method()
[Out]
※初期ではデータ登録していないため出力無し3-3.登録の確定:Session.commit()
sessionmaker(autocommit=False)の場合はトランザクションは自動で反映されないため、確定する場合はcommit()します。
commit()を実行するとrollback()で元に戻せないため注意が必要です。
[In]
Session.commit()3-4.登録の反映(未確定):Session.flush()
sessionmaker(autoflush=False)の場合はトランザクションは自動で反映されないためflush()します。commit()と異なりrollback()で元に戻せますがDB切断時にデータは保存されません。保存したいデータがある場合はcommit()の処理が必要です。
[In]
Session.flush()3-4.登録の取り消し:Session.rollback()
クエリ処理をリセットしたい場合はSession.rollback()を使用します。commit()後はrollback()はできないため注意が必要です。
[In]
Session.rollback()3-5.登録のリフレッシュ:Session.refresh()
よくわからんけど使うかもしれないので(必要であれば追って追記)
4.テーブル操作:(CRUD操作)
4-1.テーブル作成:CREATE TABLE
2,3章の通りテーブルはオブジェクトを用いて作成するためDBファイル作成と同時に作成されます。
4-2.テーブルにデータ追加:INSERT
SQL文でのテーブルへのデータ追加は下記の通りです。
[SQL文:INSERT]
INSERT INTO <テーブル名> (列1, 列2, 列3,・・・・) VALUES (値1, 値2, 値3・・・);SQLAlchemyではPythonのオブジェクト指向を踏襲してインスタンスを用いてSession.add(instance)で追加します。
【個別で入力】
まずはラベル情報を手動で追加します。
[In]
#追加するデータのインスタンス作成
label0 = Label_iris(0, 'setosa') #0:setosa
label1 = Label_iris(1, 'versicolor') #1:versicolor
label2 = Label_iris(2, 'virginica') #2:virginica
#DBへの追加
Session.add(label0)
Session.add(label1)
Session.add(label2)
#DBへ反映(commit)
Session.commit()先行しますがREAD操作でデータが追加されていることが確認できます。
[IN]
for row in Label_iris.query.all():
print(row.id_label, row.labelname)
[Out]
0 setosa
1 versicolor
2 virginica【まとめて追加:for文】
まとめて追加する場合は基本的に手動と同じ操作をfor文で実施します。
[In]
for idx, rowdata in df_data.iterrows():
iris = Iris(rowdata.sepal_length, rowdata.sepal_width, rowdata.petal_length, rowdata.petal_width, int(rowdata.id_label))
Session.add(iris)
Session.commit()同様にデータが登録されていることが確認できます。またidの値は与えていませんが自動で連番が作成されています。
[In]
for row in Session.query(Iris).all():
print(row.id, row.sepal_length, row.sepal_width, row.petal_length, row.petal_width, row.id_label)
[Out]
1 4.6 3.2 1.4 0.2 0
2 7.7 3.8 6.7 2.2 2
3 5.8 2.7 4.1 1.0 1
4 6.3 2.9 5.6 1.8 2
5 4.9 3.1 1.5 0.1 0
6 5.1 3.7 1.5 0.4 0
7 5.5 3.5 1.3 0.2 0
8 6.3 2.3 4.4 1.3 1
9 5.9 3.2 4.8 1.8 1
10 5.6 3.0 4.1 1.3 14-3.データの読み込み:SELECT
DBに保存されているデータを取得します。Session.query_property()を設定しておくとSessionを記載しないコードも使用できます。
[参考コード]
db = Session.query(Iris).all() #DBからデータを取得
db = Iris.query.all() #Session.query_property()の設定で使用可能4-3-1.データの取得(全カラム)
SQL文でのテーブルデータの取得は下記の通りです。
[SQL文:データ取得]
SELECT <列名1>, <列名2>,・・・・
FROM <テーブル名>;
[全列データ取得]
SELECT *
FROM <テーブル名>;データ取得方法は2つあり①全データをList形式で取得するall()、②1つのデータをオブジェクト形式で取得するfirst()があります。
[In -> SELECT * FROM Iris;]
print(type(Session.query(Iris)))
print(type(Session.query(Iris).all()))
for row in Session.query(Iris).all():
print(row.id, row.sepal_length, row.sepal_width, row.petal_length, row.petal_width, row.id_label)
[Out]
<class 'sqlalchemy.orm.query.Query'>
<class 'list'>
1 4.6 3.2 1.4 0.2 0
2 7.7 3.8 6.7 2.2 2
3 5.8 2.7 4.1 1.0 1
4 6.3 2.9 5.6 1.8 2
5 4.9 3.1 1.5 0.1 0
6 5.1 3.7 1.5 0.4 0
7 5.5 3.5 1.3 0.2 0
8 6.3 2.3 4.4 1.3 1
9 5.9 3.2 4.8 1.8 1
10 5.6 3.0 4.1 1.3 1[In -> SELECT * FROM Iris LIMIT 1;]
print(Session.query(Iris).first())
data_1st = Session.query(Iris).first()
print(data_1st.id, data_1st.sepal_length, data_1st.sepal_width, data_1st.petal_length, data_1st.petal_width, data_1st.id_label)
[Out]
<__main__.Iris object at 0x000002BCF850C490>
1 4.6 3.2 1.4 0.2 04-3-2.データの取得(カラム指定)
ほしいカラムだけ抽出する場合はqueryの中に”class.変数"を指定します。この場合指定しなかった変数を呼び出そうとするとエラーがでます。
[In -> SELECT id, sepal_length, id_label FROM Iris;]
row = Session.query(Iris.id, Iris.sepal_length, Iris.id_label).first()
print(row.id, row.sepal_length, row.id_label)
[Out]
1 4.6 04-3-3.データ数指定(LIMIT):limit
取得データ数を指定する場合は"limit(データ数)"とします。出力はList形式になるため"limit(1)"と"first()"は処理方法が異なります。
[In -> SELECT * FROM Iris LIMIT 3;]
db = Session.query(Iris).limit(3) #DBからデータを3つ取得
for row in db:
print(row.id, row.sepal_length, row.sepal_width, row.petal_length, row.petal_width, row.id_label)
[Out]
1 4.6 3.2 1.4 0.2 0
2 7.7 3.8 6.7 2.2 2
3 5.8 2.7 4.1 1.0 14-3-4.ソート抽出(ORDER BY):order_by
データをソートする場合はORDER BYを使用します。通常は昇順ソートですが降順にするときは”desc”を呼び出します。
[In 昇順ソート-> SELECT * FROM Iris ORDER BY id_label;]
db = Session.query(Iris).order_by(Iris.id_label) #id_labelで昇順ソート
for row in db:
print(row.id, row.sepal_length, row.sepal_width, row.petal_length, row.petal_width, row.id_label)
[Out]
1 4.6 3.2 1.4 0.2 0
5 4.9 3.1 1.5 0.1 0
6 5.1 3.7 1.5 0.4 0
7 5.5 3.5 1.3 0.2 0
3 5.8 2.7 4.1 1.0 1
8 6.3 2.3 4.4 1.3 1
9 5.9 3.2 4.8 1.8 1
10 5.6 3.0 4.1 1.3 1
2 7.7 3.8 6.7 2.2 2
4 6.3 2.9 5.6 1.8 2[In 降順ソート-> SELECT * FROM Iris ORDER BY id DESC;]
from sqlalchemy import desc #降順ソート
db = Session.query(Iris).order_by(desc(Iris.id)).limit(3) #idで降順ソート/データは3つ取得
for row in db:
print(row.id, row.sepal_length, row.sepal_width, row.petal_length, row.petal_width, row.id_label)
[Out]
10 5.6 3.0 4.1 1.3 1
9 5.9 3.2 4.8 1.8 1
8 6.3 2.3 4.4 1.3 14-3-5.条件指定(WHERE):filter
抽出条件を設定する場合はfilter(条件)を指定します。
[In -> SELECT * FROM Iris WHERE id_label = 0;]
db = Session.query(Iris).filter(Iris.id_label==0).all() #id_labelが{0:"setosa"}
for row in db:
print(row.id, row.sepal_length, row.sepal_width, row.petal_length, row.petal_width, row.id_label)
[Out]
1 4.6 3.2 1.4 0.2 0
5 4.9 3.1 1.5 0.1 0
6 5.1 3.7 1.5 0.4 0
7 5.5 3.5 1.3 0.2 04-4.データの更新:UPDATE
SQL文でのテーブルデータの更新(上書き)は下記の通りです。
[SQL文:データ更新(列全体)]
UPDATE <テーブル名>
SET <列名> = <式> ;
[SQL文:データ更新(条件指定)]
UPDATE <テーブル名>
SET <列名> = <式>
WHERE <条件>;SQLAlchemyでデータ更新する場合は、更新したいデータオブジェクトの変数に値を入力します。よってPythonと同じ操作でデータ更新が可能です。
[In -> UPDATE Iris SET id_label=100 WHERE id = 10; ※idは最終行のため本ケースは10]
db = Session.query(Iris).order_by(desc(Iris.id)).first() #最終行のデータ取得
db.id_label = 100 #id_labelを100に更新
#下記処理は確認用:チェック後に更新前の状態に戻す
Session.flush() #更新を一時的に反映
print(db.id, db.sepal_length, db.sepal_width, db.petal_length, db.petal_width, db.id_label)
Session.rollback() #処理をもとに戻す
[Out]
10 5.6 3.0 4.1 1.3 1004-5.データの削除:DELETE
SQL文でのテーブルデータの削除は下記の通りです。
[SQL文:データ削除(全データ)]
DELETE FROM <テーブル名>;
【SQL文:データ削除(条件指定)】
DELETE FROM <テーブル名>
WHERE <条件>;SQLAlchemyでデータ削除する場合は、削除したいsqlalchemy.Queryオブジェクトにdelete()を実行します(作成したclassやListではないためall()やfirst()は不要)。よってPythonと同じ操作でデータ更新が可能です。
[In]
#DELETE
Session.query(Iris).filter(Iris.id>=4).delete() #最終行のデータ削除
#下記処理は確認用:チェック後に更新前の状態に戻す
Session.flush() #更新を一時的に反映
for row in Session.query(Iris).all():
print(row.id, row.sepal_length, row.sepal_width, row.petal_length, row.petal_width, row.id_label)
Session.rollback() #処理をもとに戻す
[Out]
1 4.6 3.2 1.4 0.2 0
2 7.7 3.8 6.7 2.2 2
3 5.8 2.7 4.1 1.0 15.DBデータ(メタ情報):inspect(engine)
作成したデータベース内の詳細情報を取得します。データ取得方法として①inspect、②MetaData の2つがあります。
[In ->inspect]
from sqlalchemy import inspect
inspector = inspect(engine) #SQLAlchemyのメタ情報用オブジェクト[In ->Metadata]
from sqlalchemy import MetaData
m = MetaData()
m.reflect(bind=engine) #DBからデータを取得5-1.テーブルの一覧取得
テーブル情報をリストで取得する場合はget_table_names()です。
[In]
from sqlalchemy import inspect
inspector = inspect(engine) #SQLAlchemyのメタ情報用オブジェクト
inspector.get_table_names() #DBのテーブル名を取得
[Out ※別テーブル(Iris_pandas)追加したため3つ]
['Iris', 'Iris_pandas', 'label_iris']Metadataの場合は"dict_values"形式(SQLAlchemy用の型?)で出るためfor文で取得します。
[In]
from sqlalchemy import MetaData
m = MetaData()
m.reflect(bind=engine) #DBからデータを取得
for table in m.tables.values():
print(table.name)
[Out]
Iris
label_iris
Iris_pandas5-2.テーブルの情報取得
テーブル情報を取得する場合はsinpector.get_columns("tablename")です。出力はリスト内に辞書型のためPandasに渡すときれいに表示できます。
[In]
import pandas as pd
inspector.get_columns("label_iris")
pd.DataFrame(inspector.get_columns("label_iris"))
[Out]
[{'name': 'id_label',
'type': INTEGER(),
'nullable': False,
'default': None,
'autoincrement': 'auto',
'primary_key': 1},
{'name': 'labelname',
'type': VARCHAR(),
'nullable': True,
'default': None,
'autoincrement': 'auto',
'primary_key': 0}]
全テーブルの情報を取得する場合は前節のテーブル一覧をfor文で回すことで取得できます。
[In]
for table_name in inspector.get_table_names(): #DBのテーブル名を取得
display(pd.DataFrame(inspector.get_columns(table_name))) #テーブル名を指定してカラム情報を取得
[Out]
-6.応用操作
6-1.DBの型取得: from sqlalchemy.orm import Session
型ヒントなどでSession DBの型を取得したい場合は下記を使用します。
[In]
from sqlalchemy.orm import Session
Session # <class 'sqlalchemy.orm.session.Session'>
type(Session) #type
type(int) #参考:整数型intをtypeで入れると型はtypeとなる
[Out]
sqlalchemy.orm.session.Session
type
type6-2.一時使用:create_engine('sqlite:///:memory:')
sqlite3での紹介と同様にDBpathを指定する代わりに':memory:'と記載することでDB切断時まで一時的に使用可能です(データはメモリ上で管理)。
[In]
from sqlalchemy import create_engine
engine = create_engine('sqlite:///:memory:')
#後はengineを通常通り使用する。7.予備章
増えるかもしれないので。
8.Engine API×SQL文
通常は作成したEngineオブジェクトにSessionを連動させていましたが、EngineだけでもDB操作は可能です。記載は下記のどちらでも問題ないです。
[In_1]
from sqlalchemy import create_engine
engine = create_engine(DBpath)
with engine.connect() as con: #ここでDB接続
con.execute(query)
[In_2]
from sqlalchemy import create_engine
engine = create_engine(DBpath)
con = engine.connect()
con.execute(query)
con.close()
サンプルコードは下記の通りです。ORMの良さはなくなりますがSQLでサクッと操作したいときに便利です。
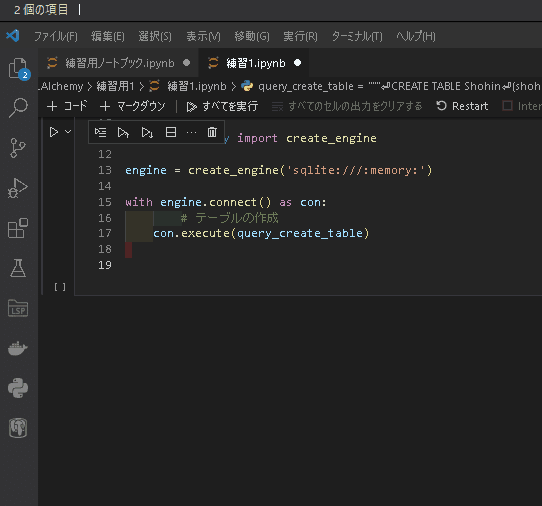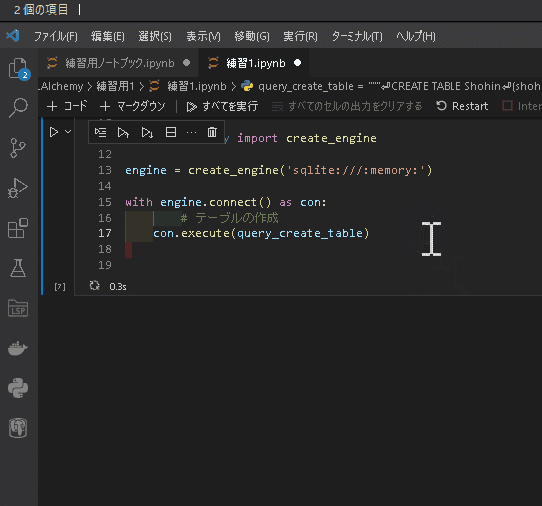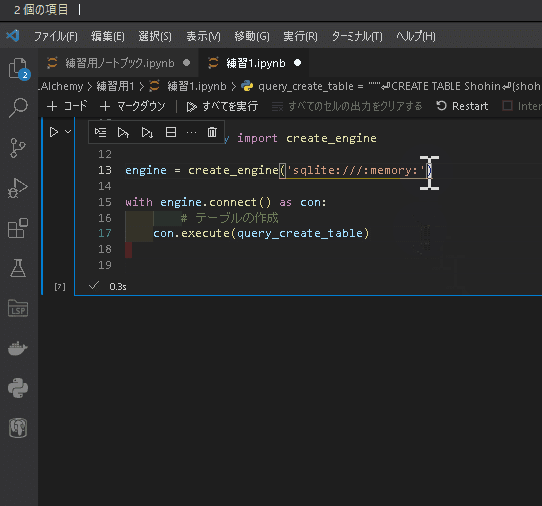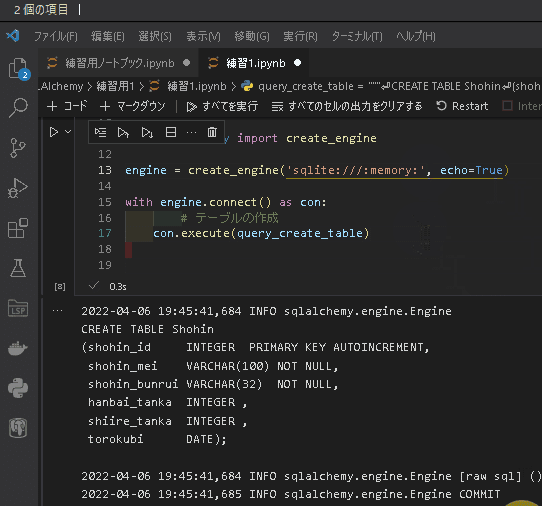
[In]
query_create_table = """
CREATE TABLE Shohin
(shohin_id INTEGER PRIMARY KEY AUTOINCREMENT,
shohin_mei VARCHAR(100) NOT NULL,
shohin_bunrui VARCHAR(32) NOT NULL,
hanbai_tanka INTEGER ,
shiire_tanka INTEGER ,
torokubi DATE);
"""
from sqlalchemy import create_engine
engine = create_engine('sqlite:///:memory:')
# 接続する
with engine.connect() as con:
# テーブルの作成
con.execute(query_create_table)
# Insert文を実行する
con.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('Tシャツ' ,'衣服', 1000, 500, '2009-09-20');")
con.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('穴あけパンチ', '事務用品', 500, 320, '2009-09-11');")
con.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('カッターシャツ', '衣服', 4000, 2800, NULL);")
con.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('包丁', 'キッチン用品', 3000, 2800, '2009-09-20');")
con.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('圧力鍋', 'キッチン用品', 6800, 5000, '2009-01-15');")
con.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('フォーク', 'キッチン用品', 500, NULL, '2009-09-20');")
con.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('おろしがね', 'キッチン用品', 880, 790, '2008-04-28');")
con.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('ボールペン', '事務用品', 100, NULL, '2009-11-11');")
# Select文を実行する
rows = con.execute("SELECT * FROM Shohin;")
for row in rows:
print(row)
[Out]
(1, 'Tシャツ', '衣服', 1000, 500, '2009-09-20')
(2, '穴あけパンチ', '事務用品', 500, 320, '2009-09-11')
(3, 'カッターシャツ', '衣服', 4000, 2800, None)
(4, '包丁', 'キッチン用品', 3000, 2800, '2009-09-20')
(5, '圧力鍋', 'キッチン用品', 6800, 5000, '2009-01-15')
(6, 'フォーク', 'キッチン用品', 500, None, '2009-09-20')
(7, 'おろしがね', 'キッチン用品', 880, 790, '2008-04-28')
(8, 'ボールペン', '事務用品', 100, None, '2009-11-11')9.PandasでのSQL操作
Pandasを使用してSQLAlchemyへデータ追加や抽出をしたいと思います。まずサンプル用データを下記の通り作成しました。
[In]
import pandas as pd
import numpy as np
from sklearn import datasets
np.random.seed(0) #乱数値を固定
idx_random = np.random.randint(0, len(datasets.load_iris().data), size=10) #乱数で10個のインデックスを取得->array([ 47, 117, 67, 103, 9, 21, 36, 87, 70, 88])
iris = datasets.load_iris() #Irisデータセットを読み込み
columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] #列名指定※半角スペースやカッコはエラーになるため除去
data, label = pd.DataFrame(iris.data, columns=columns), pd.DataFrame(iris.target, columns=['target'])
label = label['target'].map({0: 'setosa', 1: 'versicolor', 2: 'virginica'}) #ラベルを数値から文字列に変換
df = pd.concat([data, label], axis=1) #データとラベルを結合
df_iris = df.iloc[idx_random, :] #ランダムに10個データを取得
df_iris
9-1.テーブル作成:df.to_sql()
df.to_sql()でDataFrame型データをテーブルとしてDBに追加できます。df.to_sql()実行時点でデータは追加されておりますがクラスの定義をしていないためこの時点ではSessionでデータは取得できないと思います。
[In]
df_iris.to_sql('Iris_pandas', engine, if_exists='replace') #SQLAlchemyに保存
[Out]
テーブル作成+データ追加9-2.データの読み込み:pd.read_sql(query, engine)
PandasはDBを指定してクエリを記載することでDataFrame型データとしてテーブルを取得することが可能です。
[IN]
pd.read_sql("SELECT * FROM Iris_pandas", engine) #SQLAlchemyから読み込み
[Out]
下記参照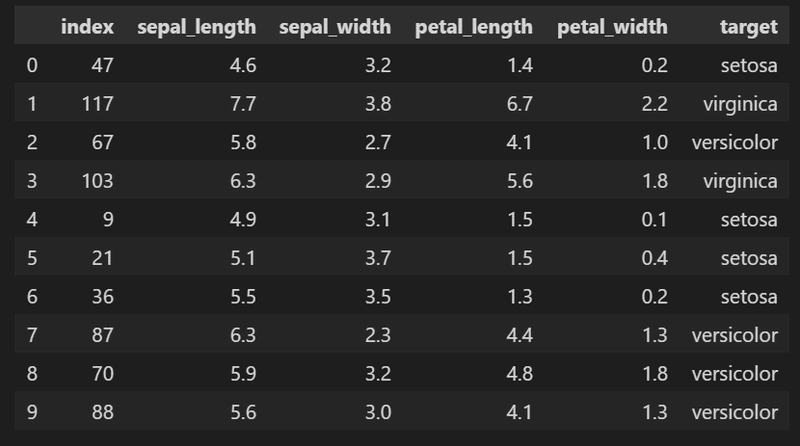
10.データベース(PostgreSQL)への接続
上記ではDBファイルやSQLテーブルまで一から作成しましたが、本章では既設のSQL-DBに接続してSQLAlchemyでの操作を紹介します。SQLはPostgreを使用しておりデータは参考資料のshopデータベースを使用します。
なおpostgreSQLへの接続には"psycopg2"ライブラリが必要です。
[Terminal]
pip install psycopg210-1.DB接続の設定/engine作成:URL.create()
始めにDB接続情報を記載します。今回は「PostgreSQLで作成したlocalhostにあるshopデータベース」に接続します(作成要領は参考資料の書籍参照)。
次に接続情報をSQLAlchemyのengineオブジェクトに渡します。
[In]
from sqlalchemy import create_engine
from sqlalchemy.engine.url import URL
#PostgreSQLへの接続情報を記載
url = URL.create(
drivername = 'postgresql', #ドライバ名
username = 'postgres', #ユーザ名
password = '123456789', #PostgreSQLで設定したパスワード
host = 'localhost', #PostgreSQLサーバーのホスト名
port = '5432', #PostgreSQLサーバーのポート番号※初期値
database='shop' #接続したいDB名
)
print(url) #接続するためのURL:<class 'sqlalchemy.engine.url.URL'>
engine = create_engine(url) #SQLAlchemyのengineを作成
engine
[Out]
postgresql://postgres:123456789@localhost:5432/shop
Engine(postgresql://postgres:***@localhost:5432/shop)10-2.DBのテーブルクラスの定義:class(Base)
次にSQLAlchemyでテーブル情報を取得するためにテーブルクラスを作成していきます。注意点として「テーブル名の大文字/小文字は区別される」ため登録したテーブル名を記載する必要があります(Shohinだとエラー)。
[In]
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
Base = declarative_base() #SQLAlchemyのBaseクラスを作成
#テーブルクラスの作成
class Shohin(Base):
__tablename__ = 'shohin' #PostgreSQLで作成したテーブル名
shohin_id = Column(Integer, primary_key=True)
shohin_mei = Column(String)
shohin_bunrui = Column(String)
hanbai_tanka = Column(Integer)
shiire_tanka = Column(Integer)
torokubi = Column(DateTime)10-3.Postgres接続:sessionmaker(bind=eigine)()
最後にsessionmakerでDBに接続で完成です。あとは通常のSQLAlchemyと同じ操作でDB操作が可能となります。
[In]
from sqlalchemy.orm import sessionmaker
session = sessionmaker(bind=engine)() #sessionを作成
shohins = session.query(Shohin).all() #全てのShohinを取得
for row in shohins:
print(row.shohin_id, row.shohin_mei, row.shohin_bunrui, row.hanbai_tanka, row.shiire_tanka, row.torokubi)
session.close() #sessionを閉じる
[Out]
0001 Tシャツ 衣服 1000 500 2009-10-10
0002 穴あけパンチ 事務用品 500 320 2009-10-10
0008 ボールペン 事務用品 100 None None
0004 包丁 キッチン用品 30000 1400 2009-10-10
0006 フォーク キッチン用品 5000 None 2009-10-10
0007 おろしがね キッチン用品 8800 395 2009-10-10PostgreSQLに接続しているためCRUD操作がすべてできるためREAD以外の操作をする場合は注意が必要です。またsession.close()が十分に理解できていないので追って修正予定
サンプルコード(自分用)
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker, scoped_session, relationship
from sqlalchemy.orm import Session #データ型取得
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, Float, String, DateTime, Boolean, ForeignKey #SQLテーブルのカラム設定用
from sqlalchemy import desc #降順ソート
import pandas as pd
DB_file = 'dbfilename.db'
engine = create_engine('sqlite:///' + DB_file, echo=True) #DB接続の設定
# engine = create_engine('sqlite:///:memory:') #メモリ上にDB作成(一時的な処理用)
Session = scoped_session(
sessionmaker(
autocommit=False, #commit自動化の設定
autoflush=True, #flush自動化の設定
bind = engine
)
)
Base = declarative_base() #DB基底クラスの作成
Base.query = Session.query_property() #DBクエリの設定
class Iris(Base):
__tablename__ = 'Iris' #テーブル名の作成
id = Column(Integer, primary_key=True) #データログid設定:主キー制約
col1 = Column(Float)
col2 = Column(String)
def __init__(self, col1, col2):
self.col1 = col1
self.col2 = col2
def init_DB():
Base.metadata.create_all(bind=engine) #DB作成/初期化参考資料
MySQLのテーブル結合チートシートhttps://t.co/cVjapx8Vl0 pic.twitter.com/cIMFzZs46z
— QDくん⚡️Python x 機械学習 x 金融工学 (@developer_quant) January 29, 2023
あとがき
SQLAlchemyの公式Docsの英文の意味が分からないのでDeepLで翻訳してみたけど、さらに意味がわからんのでまじでしんどかった・・・今更だが説明用だったらengineのechoはTrueにしておくべきだったな・・
まだまだ追記があると思うのでとりあえずいったん公開します。
【自分用メモ:不明点】
●Foreign Keyとrelationの関係
ー>親テーブルを消しても子テーブルが残る
ー>制約がうまくかかってないので削除できる:多分__table_args__
●Sessionが残っていくので管理:Session.close()だけでOK?
●session.refresh()の意味
この記事が気に入ったらサポートをしてみませんか?