Pythonでやってみた14:特許情報の可視化

1.概要
特許調査において技術の漏れが発生してほしくない場合情報量は数百件以上(多いなら数万件)になることもあり調査には非常に時間を費やします。
ほしい情報だけを抽出できるようにしたいため、簡易ではありますが情報の可視化に挑戦してみます。
なおサンプルとして特許庁が公開しているGXTIを使用しました。
2.GX技術区分表(GXTI)
「GXTI (Green Transformation Technologies Inventory)」は、グリーン・トランスフォーメーション(GX)に関する技術を俯瞰するために、2022年6月に特許庁が作成した技術区分表であり、各技術区分に含まれる特許文献を検索するための特許検索式も併せて公開するものです。

2-1.特許調査の目的・種類
特許調査目的で分かりやすいのは下記動画となります。

2-2.検索式の確認
検索式の書き方の詳細は省きますがメインの演算子は「AND(かつ)」と「OR(両方含む)」となります。今回はGXTIで表示されている検索式をそのまま使用します。
GXTIのページから「GXTI技術区分表」を取得します。今回はExcelで取得しました。次で使用するJ-PlatPatでは検索件数が3,000件を超えると表示できないため、適当に「地熱発電-【参考】J-Platpat形式(和文)」を選定しました。


参考としてExcel内の”検索式の説明”シートを抜粋しました。

2-3.特許情報の抽出:J-PlatPat
特許情報プラットフォーム(J-PlatPat)は、日本だけでなく欧米等も含む世界の特許・実用新案、意匠、商標、審決に関する公報情報、手続や審査経過等の法的状態(リーガルステイタス)に関する情報等が収録されており、無料で特許情報の検索・閲覧サービスを提供しています。

「特許・実用新案検索」から「論理式入力」を選択して論理式を入力後に検索ボタンを押すと結果一覧が表示されます。


結果一覧表示後に「CSV出力」で結果を出力します。なお結果出力には利用申請が必要なため、未登録の方はCSV認証の”ご利用申請はこちら”からご登録ください。

CSVの構造は下図の通りです。

【参考:検索式の構造】
間違っている可能性がありますが、ChatGPTに検索式をくわせて解説してもらいました。どちらか言うと、自分で学習して学んだ認識が間違っていないかの答え合わせの参考くらいには使えると思います。

3.データ解析1:EDA/前処理編
まず初めにどういうデータがあるかを確認していきます。出力形式を理解済みであれば飛ばしても問題ないと思います。参考として使用する関数は下記を使用しました。
まずは事前に必要そうなライブラリのインストールし、CSVファイルはPandasでDataFrameとして読み込みます。
[IN]
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
from datetime import datetime
import os
import glob
import re
import matplotlib.patches as mpatches
from janome.tokenizer import Tokenizer
from wordcloud import WordCloud
class HorizontalDisplay:
def __init__(self, *args): self.args = args
def _repr_html_(self): return '\n'.join('<div style="float: left; padding: 10px;">{}</div>'.format(a._repr_html_()) for a in self.args)
path_CSV = '特実_国内文献.csv'
df = pd.read_csv(path_CSV, encoding='utf-8')
display(df.head())
[OUT]
3-1.サマリーの確認
データ情報の一覧を表示し、出力は下記の通りです。数値データではないためmin/maxはコメントアウトしています。
データフレーム(df)の形状(行と列の数): df.shape
各列のデータ型(整数型や浮動小数点型など): df.dtypes
各列の欠損値(null)の数とその割合: df.isnull().sum()
各列に含まれるユニークな値の数: df.nunique()
各列の1~3つ目の値: df.loc[0], df.loc[1], df.loc[2]
[IN]
def summary(df):
print(f'data shape: {df.shape}')
summ = pd.DataFrame(df.dtypes, columns=['data type'])
summ['#missing'] = df.isnull().sum().values * 100
summ['%missing'] = df.isnull().sum().values / len(df)
summ['#unique'] = df.nunique().values
desc = pd.DataFrame(df.describe(include='all').transpose())
# summ['min'] = desc['min'].values
# summ['max'] = desc['max'].values
summ['first value'] = df.loc[0].values
summ['second value'] = df.loc[1].values
summ['third value'] = df.loc[2].values
return summ
display(summary(df))
[OUT]
data shape: (653, 13)
データ数(抽出した特許件数)は653件あり全データがカテゴリカルデータ(文字列、Noneなど)であることが確認できます。
3-2.欠損値の確認
欠損値を可視化します。そもそもKaggle用(AIコンペ)に作っているため関数の変数名が今回用とはあっていないのですが動いているからヨシ!。
[IN]
def plot_missing_values_ratio(df_list, titlenames, threshold=1, verbose=False):
if isinstance(df_list, pd.DataFrame):
df_list = [df_list]
fig, axes = plt.subplots(nrows=1, ncols=len(df_list), figsize=(8 * len(df_list), 8))
plt.rcParams['font.size'] = 16
if len(df_list) == 1:
axes = [axes]
for i, (df, titlename) in enumerate(zip(df_list, titlenames)):
missing_ratios = df.isna().sum() / len(df)
colors = ['red' if ratio == 1 else
'pink' if ratio >= threshold else
'orange' for ratio in missing_ratios.values]
#欠損値を割合による色分けで棒グラフを描画
axes[i].bar(missing_ratios.index,
missing_ratios.values,
color=colors)
#閾値の線を描画
axes[i].axhline(y=threshold, color='red', linestyle='--', lw=0.5)
axes[i].set_xlabel('Feature', fontsize=12)
axes[i].set_ylabel('Missing values ratio', fontsize=12)
axes[i].set_yticks(np.arange(0, 1.1, 0.1))
axes[i].set_title(f'Missing values ({titlename})', fontsize=12)
axes[i].tick_params(axis='x', labelrotation=90)
axes[i].legend(handles=[mpatches.Patch(color='orange'),
mpatches.Patch(color='pink'),
mpatches.Patch(color='red')],
labels=[f'部分欠損 < {threshold}' ,
f'部分欠損 >= {threshold}',
'完全欠損'],
fontsize=12)
#グリッド線を描画
if verbose:
axes[i].grid(axis='y')
plt.tight_layout()
plt.show()
plot_missing_values_ratio(df, titlenames=['特実_国内文献'], threshold=0.9, verbose=True)
[OUT]
特定のデータに欠損値があることが確認できます。特に使用するデータではないため問題なしと判断します。
【参考:欠損値がある理由】
特定データに関して欠損値(データが発行されていない)がある理由としては下記のようなものがあります。


4.データ解析2:データの可視化
ほとんどのデータはカテゴリカルデータであるため前処理は難しいですが、比較的簡単に処理できそうなものは下記があります。
本当はFIの数も可視化したいのですがFIを十分に理解できていないためこちらは除外しました。なお今回の分析は検索式次第で結論が異なる可能性があることに注意が必要です。
出願日:特許を出願した日
公知日:各案件が公知になった日であり、国内案件については 公開公報、登録公報のうち先に発行された公報の発行日を指す
出願人/権利者:出願した人
FI:IPC (International Patent Classification)とは、世界各国で共通に使用できる特許分類であり、FIタームはIPCを基礎として所定の技術分野ごとにあらゆる技術観点(目的や用途、構造など)から細区分したもの

4-1.出願/公知件数の推移
出願日、公知日の件数を可視化することで特許数の推移を可視化してその技術が伸び盛りかどうかを判定できます。処理手順としては下記の通りです。
出願日、公知日のデータをdatetimeに変換
年毎の件数を抽出
可視化
「綺麗さより迅速さ/簡易さ」として関数内でまとめて処理します。2個目のグラフは少し体裁を増やすパターンを追加しました。
[IN]
def countApps_yearly(df, col_date:str):
#文字列をDatetime型に変換
df[col_date] = pd.to_datetime(df[col_date])
df['year'] = df[col_date].dt.year #年を抽出
counts_per_year = df['year'].value_counts().sort_index()
return counts_per_year
countApps_yearly(df, col_date='出願日').plot.bar(figsize=(12, 4), color='orange')
plt.show() #棒グラフの重なり防止
countApps_yearly(df, col_date='公知日').plot.bar(figsize=(12, 4), color='blue',
alpha=0.5, label='公知日', legend=True,
position=0, width=0.4, rot=45,
fontsize=12, grid=True,
ylim=(0, 40), ylabel='公知日の件数',
xlabel='年度', title='公知日件数の推移')
[OUT]

結果として今回の抽出結果では地熱発電はやや下火になってきていることが確認できます
4-2.出願人/権利者の数
出願人/権利者の数はPandasのvalue_counts()メソッドで抽出できます。
[IN]
df['出願人/権利者'].value_counts()
注意点として記載方法で別物としてカウントされます。下記を見ると古い特許情報はカタカナ表記になっているため同じ会社でも別物になります。

まずは全データ抽出して指定の数だけ表示しました。なお、1行目のコードは検算用です。結果は下記の通りですが三菱重工は漢字とカタカナが混じっていたり、MHPSとの共同もあるため見方には注意が必要です。
[IN]
print(df['出願人/権利者'].value_counts().sum(), df.shape) #件数の確認(検算)
df['出願人/権利者'].value_counts().head(20).plot.bar(figsize=(12, 4), color='orange')
[OUT]
653 (653, 13)
出願日が2018年以降のデータのみを抽出しました。下図は32件と少ないため全データプロットしました。基本的には大手プラントメーカーが上位に来ることが確認できます。そもそも地熱発電は掘削も含めたEPCや地元住民との交渉なども含めた調整など参入障壁が大きいため(特許は誰でも出せますが)社会実装は誰でもできるものではありません。
[IN]
df['出願日'] = pd.to_datetime(df['出願日'])
df['year'] = df['出願日'].dt.year #年を抽出
df_2018 = df[df['year'] >= 2018]
print(df_2018['出願人/権利者'].value_counts().sum(), df_2018.shape) #件数の確認(検算)
df_2018['出願人/権利者'].value_counts().plot.bar(figsize=(12, 4), color='orange')
[OUT]
32 (32, 14)
5.データ解析3:文字列の解析/可視化
特許データには発明の名称がありますので、ここに含まれる文字列を抽出してどのようなキーワードがあるかを可視化します。
本当は文献URLから全文抽出->全体要約->可視化までしたいのですがスクレイピングなども入るため今回は避けました(多分技術的にもできないので)。

5-1.形態素解析
「発明の名称」の文字列を形態素解析します。形態素解析のライブラリは複数ありますが、比較的簡単に使用できるjanomeを使用しました。
参考ですがjanomeだと形態素解析が十分でない時もある(特に新しい用語)ため、より良いライブラリを使用できる人はそちらの方がよいと思います。
janomeでは下記のように形態素解析ができますので、そこから名詞だけ抽出しました。まずは動作確認だけしてみます。
Tokenizer()でインスタンス化してtokenize()で形態素解析
形態素解析した変数をpart_of_speechで品詞確認
形態素解析した変数をsurfaceで単語だけ抽出
[IN]
from janome.tokenizer import Tokenizer
appnames = df['発明の名称'].values
tokenizer = Tokenizer()
for appname in appnames[:5]:
print(appname)
tokens = [t.surface for t in tokenizer.tokenize(appname) if t.part_of_speech.startswith('名詞')]
print(tokens)
print('-' * 40)[OUT]
直接接触式復水器、及び地熱発電システム
['直接', '接触', '式', '復', '水', '器', '地熱', '発電', 'システム']
----------------------------------------
地球上が必要とする、全てのエネルギーを、極く安価なコストと、二酸炭素の発生は、全くない、0にて、地球上が必要とする、全てのエネルギーを賄う方法。
['地球', '上', '必要', '全て', 'エネルギー', '安価', 'コスト', '二', '酸', '炭素', '発生', '0', '地球', '上', '必要', '全て', 'エネルギー', '方法']
----------------------------------------
地熱発電設備の異常判定システム、異常判定装置、データ取得装置、異常判定プログラム及びデータ取得プログラム
['地熱', '発電', '設備', '異常', '判定', 'システム', '異常', '判定', '装置', 'データ', '取得', '装置', '異常', '判定', 'プログラム', 'データ', '取得', 'プログラム']
----------------------------------------それでは実際に値を抽出して文字列をカウントする処理を実装します。処理のポイントは下記の通りです。
内包表記を用いて形態素解析した品詞が”名詞”から始まる物だけ抽出
形態素(tokens)をextendでリストに格納:リスト内に1次元配列で追加
Series化した後にvalue_counts()を使用して計算
出力をDict化/そのまま可視化
[IN]
from janome.tokenizer import Tokenizer
appnames = df['発明の名称'].values
tokenizer = Tokenizer()
words = []
for appname in appnames:
tokens = [t.surface for t in tokenizer.tokenize(appname) if t.part_of_speech.startswith('名詞')]
words.extend(tokens) #リストを1次元で結合
df_words = pd.Series(words).value_counts()
word_counts = df_words.to_dict()
print(word_counts)
df_words.head(20).plot.bar(figsize=(12, 4), color='orange')[OUT]
{'地熱': 419,
'発電': 367,
'装置': 267,
'方法': 154,
'-': 147,
'システム': 143,
'熱': 102,
'蒸気': 99,
'プラント': 93,
'ビン': 88,
'タ': 83,
'タービン': 58,
'制御': 51,
'水': 48,
'利用': 43,
'サイクル': 40,
'設備': 40,
'エネルギ': 38,
'用': 33,
'エネルギー': 29,
'型': 28,
'器': 27,
'式': 25,
'交換': 24,
'発生': 24,
...
'照明': 1,
'調整': 1,
'1つ': 1,
'電圧': 1,
'ハツデンホウホウオヨビソウチ': 1}
5-2.文字の可視化
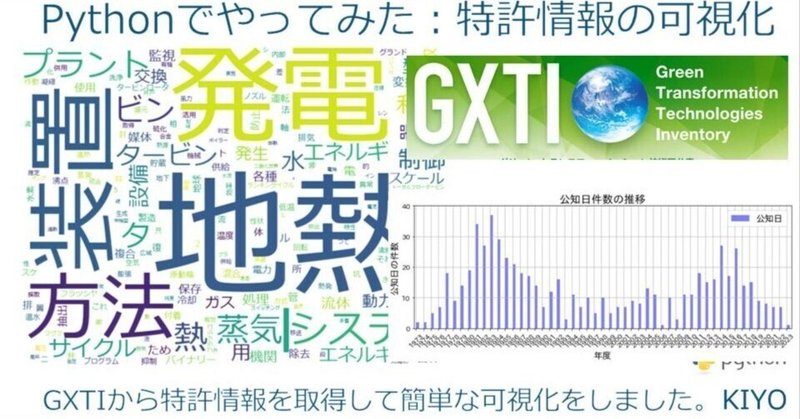
先ほど文字列を辞書型で取得できましたのでそれを用いてWordCloudで可視化します。地熱発電のため「地熱」、「発電」の文字は多いですが、それ以外にもバイナリーや太陽熱、ランキンサイクルもあるため、バイナリー形式や太陽熱も利用した複合型があるのかもしれないと推測できます。
[IN]
# Create a WordCloud object
wordcloud = WordCloud(background_color='white',
width=800, height=600,
font_path='meiryo.ttc')
# Generate the word cloud
wordcloud.generate_from_frequencies(word_counts)
# Display the word cloud
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
[OUT]
【参考:地熱発電におけるバイナリー発電とは】
バイナリー発電とは、加熱源により沸点の低い媒体を加熱・蒸発させてその蒸気でタービンを回す方式です。加熱源系統と媒体系統の二つの熱サイクルを利用して発電することから、バイナリーサイクル(Binary(注)-Cycle)発電と呼ばれており、地熱発電などで利用されています。地熱バイナリー発電では、低沸点媒体を利用することにより、媒体の加熱源に従来方式では利用できない低温の蒸気・熱水を利用することができます。

6.所感
欲しいキーワードを綺麗に抽出できれば「キーワード別の件数/可視化」が出来ますし、要約も含めて全部抽出できるならさらに深いところまで可視化できます。
直近のAIの進化のおかげでやりたいことの幅が広がりますが、まだ処理速度が足りない、人間がやるレベルまでの要約(特に専門分野のところ)、スクレイピングの禁止・APIの未開放などまだまだなところはあります。まずは補助ツールとして使いながら業務効率化ができればよいなと思います。
参考資料
あとがき
形態素解析の精度向上×ChatGPTによる要約なども組み合わせたら欲しい情報だけ抜けそうだけど、まだ先なのかな・・・・・
この記事が気に入ったらサポートをしてみませんか?