【W6】最大共通部分構造_03_Step1後編

【W6の目的】
化合物セットが共通してもつ最大の部分構造を計算する方法を学びます。
【MCS解析データ処理】
最大共通部分構造(maximum common structure、MCS)は2つあるいはそれ以上の対象化合物に含まれる最大の部分構造として定義されています。
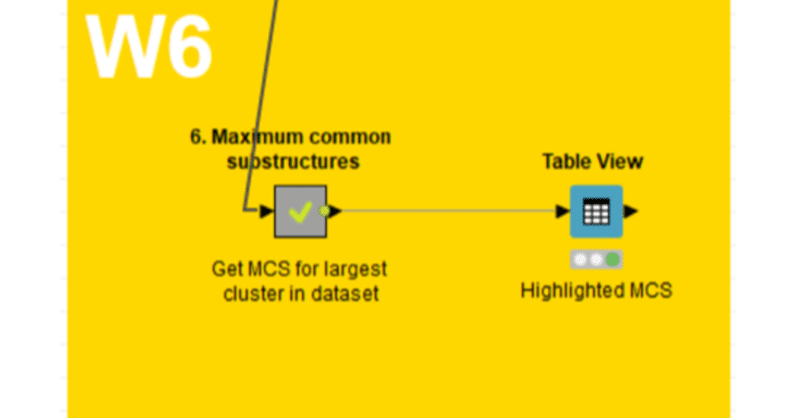
6. Maximum common substructuresメタノード
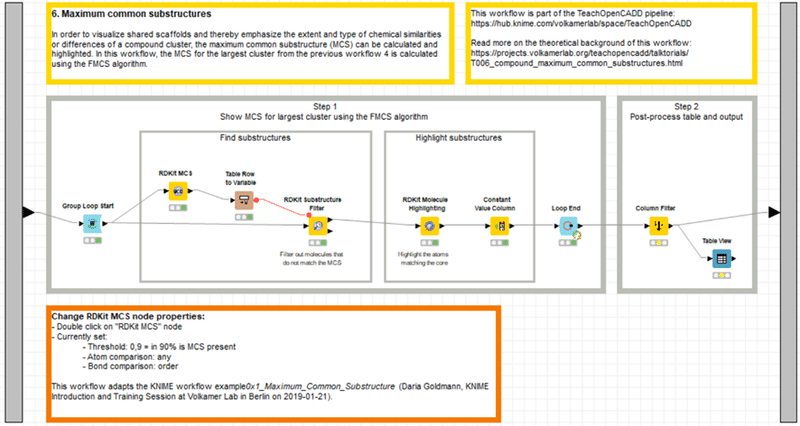
のStep1を体験中です。MCS解析までを前回実施しました。
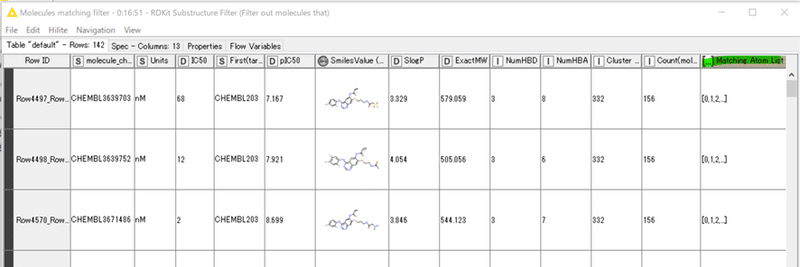
KNIMEを利用してノーコードでMCS解析が実施できました。
デモデータではW6に入力した156化合物のうち、9割に当たる142化合物に共通する最大共通部分構造(MCS)がありました。
Step1の後半ではMCSを可視化します。
【RDKit Molecule Highlighting】
日本語化されたディスクリプションより
入力テーブルの情報に基づいて、原子と結合をハイライトした分子を示すSVGコラムを作成します。
分子の列と、ハイライトされる原子や結合のインデックスのリストを持つ列が提供される必要があります。
今回はMatching Atom Listカラムにハイライトしたい原子のデータがリスト形式で格納されています。
また、このノード自体はW3でも利用しました。構造検索結果の可視化にはとても便利ですね。
設定:
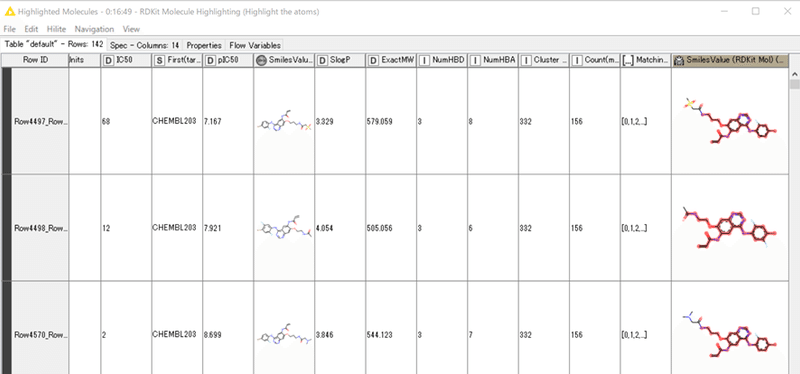
結果:
各化合物のMCS部分が赤色表示されます。
【Constant Value Column】
MCSのSMARTSを加えています。一つの値を全ての行に入力するノードですが、今回のようにGroup Loopをかけていて、かつLoopごとに変化する変数で入力値を定義するのは有用な利用法です。
設定:
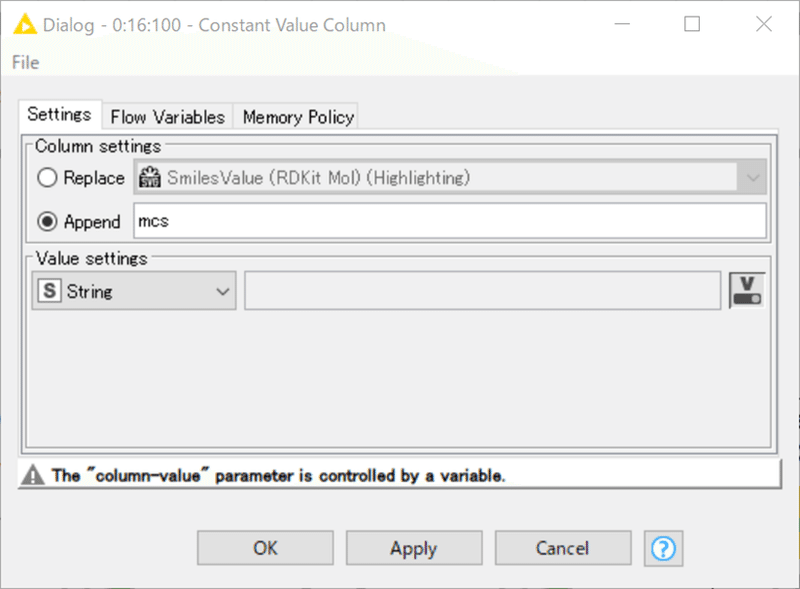
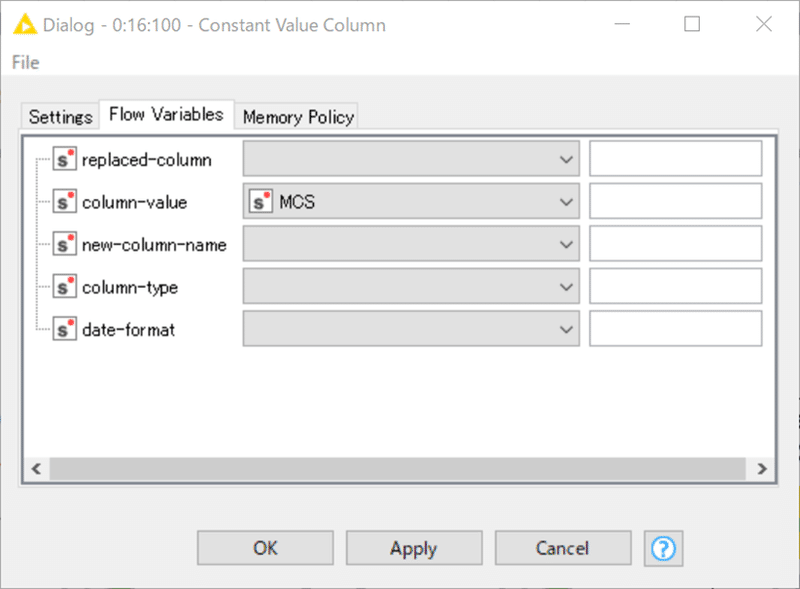
ただ、とても不思議なことに次のStep2でこのカラムを削除するんですよね。なんでここでカラムを作ったのかなぁと思いますが後日また。
【Loop End】
紹介済のノードではありますが、
日本語化されたディスクリプションより引用します。
ループの最後に位置するノード。
これは、ワークフローのループの終わりを示すために使用され、入力されたテーブルを行単位で連結して中間結果を収集します。
前回説明した通り、今回は単一のクラスターすなわち1つしかGroupのないデータセットをGroup Loopにかけてますが、もし複数クラスターを扱った場合は行単位でつまり縦に連結して集計してくれます。
データ数次第ではその集計に時間がかかってこのノードで止まってしまうこともしばしばあります。
設定:
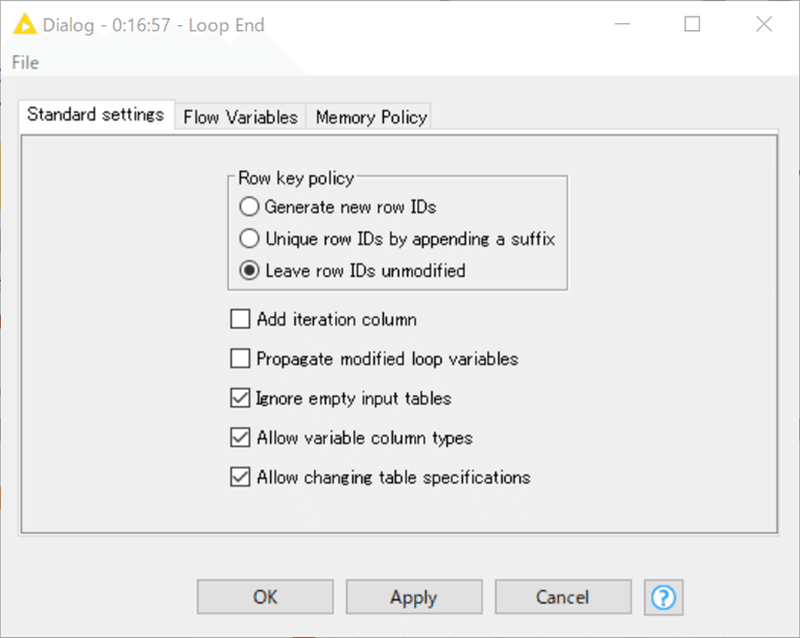
各設定の意味はディスクリプションで解説されてはいますが、二項目のみ紹介しておきます。
今回実施しているGroup Loopの場合は、入力が同じデータテーブルからのループ処理なので、おねじ名前のカラムのデータ型が変わってしまうことはまずないですので余談と思ってお読みください。
Allow variable column types
チェックした場合、異なるテーブル反復の間でカラムタイプが変わっても、ループは失敗しません。
Allow changing table specifications
チェックされていると、イテレーション間でテーブルの仕様が異なることがあります。
イテレーションの間にカラムが追加または削除された場合、欠損値は結果テーブルに適宜挿入されます。
チェックされておらず、テーブルの仕様が異なる場合は、ノードは失敗します。
例えばですが複数のExcelシート群からデータを取ってくるときにシート間でデータ型(数値と文字列とか) が違っているとかデータ種の増減がある時でもループが止まらないようにすることができます。
結果:
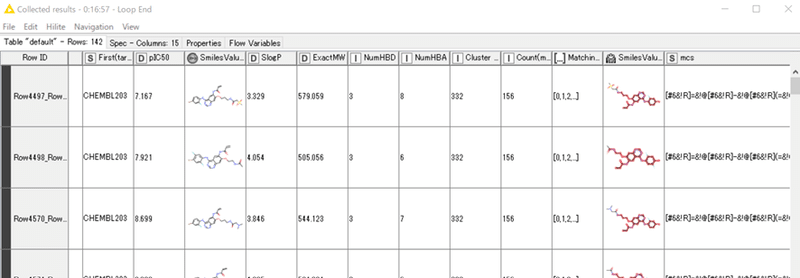
デモデータでMCS解析された142化合物について、
RDKit Molecule HighlightingでMCS部分を可視化し、
Constant Value ColumnでMCSのSMARTS情報も加えられました。
MCS解析とデータ処理が完了です。
次回、Table Viewでデータを表示し、内容も見てみます。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。