【W5】化合物クラスタリング_01_概要

【W5の目的とT5の推薦】
・化合物をグループ化する方法と、多様性のある化合物セットを選ぶ方法
を学びます。
Python版TeachOpenCADDのT5が対応しますが、こちらはより発展的です。
上記の目的に加えて
• クラスタリングアルゴリズム2つの簡潔な紹介
• サンプル化合物セットへのButinaクラスタリングアルゴリズムの適用
理論
• クラスタリングとJarvis-Patrickアルゴリズムの紹介
• Butinaクラスタリングの詳細な説明
• 多様性の化合物の選択
実践
• Butinaクラスタリングと化合物選択の例
までを詳細な説明付きで体験可能です。一読されることを強くお勧めします。
【W5でのクラスタリング手法】
これまでにKNIMEでできること、苦手とするところをいくつか紹介してきました。
Pythonなどを使わない限り、KNIMEの既存ノードではButinaクラスタリングを実装できないです。
代わってHierarchical Clustering (Dist Matrix)ノードを利用してクラスタリングを行います。参考としたworkflowはこちら。
ではW5の本体であるメタノード「5. Compound clustering」の中身を見ていきます。
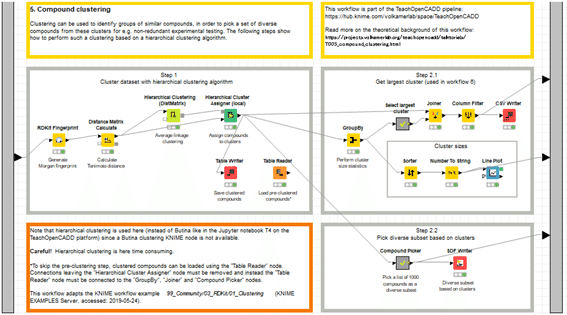
【Step1: 階層型クラスタリング】
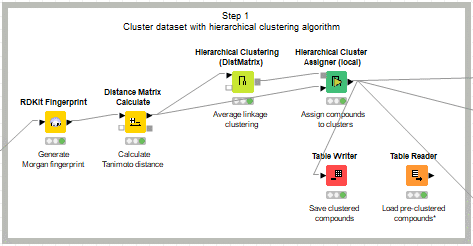
前回まで体験していたW4と同様にMorganフィンガープリントを算出したのち、タニモト距離を用いて階層型クラスタリングを実施します。
階層型クラスタリングの説明は多くあると思うのですが、おすすめはこちら。
金子先生のブログ、素晴らしいですよね。偉業に敬意を表しつつ引用します。
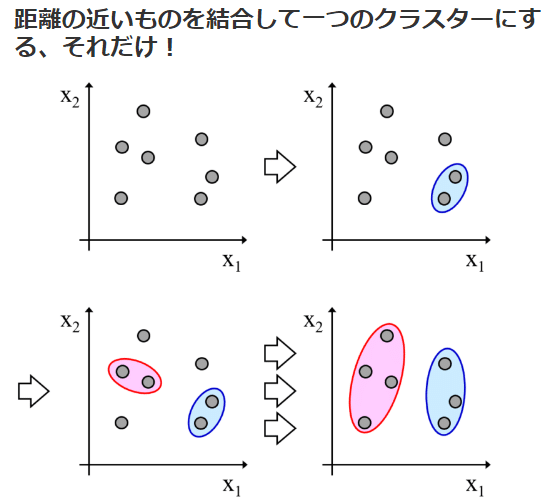
まずはそれぞれのサンプルを一つのクラスターとして、近いクラスター同士を次々に結合して新たなクラスターとすることで、クラスターの数を減らしていきます。
さらに詳しく調べるのは次回に譲ります。
【Step2.1: クラスターサイズに基づくデータ処理】
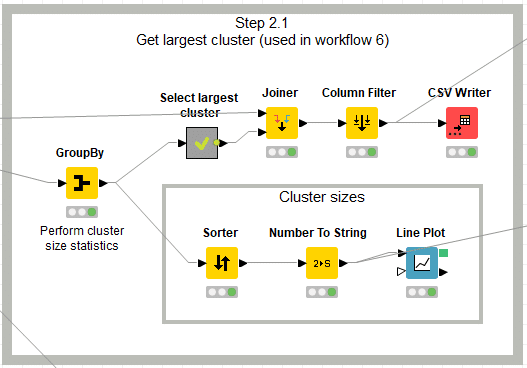
上部では次のW6のMCS解析に用いるためのデータセットとして、最大クラスターを抽出します。
下部はクラスター毎の化合物数で並べ替えてグラフ化しています。クラスターの大きさの分布を知ることができます。
【Step2.2: 多様性のある化合物セットを選ぶ】
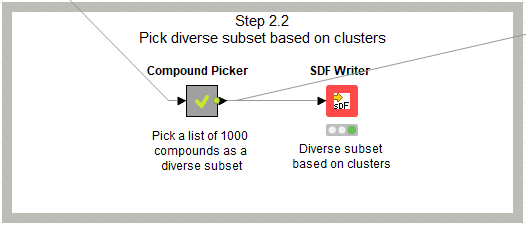
デモデータではW5の入力は4511化合物あります。そこから1000化合物を多様性に配慮しつつ選抜する方法を体験します。
おまけ:
【クラスタリングという深淵】
化合物クラスタリングについて、日本語に限定してもRDKitの玄人さんたちの情報がふんだんにあります。また、クラスタリングした結果をマッピングする手法も様々です。
いくつかの優れた記事を紹介しておきますので、深淵を垣間見てはいかがかと思います。
数年前になりますが玄人の方に、「ケモインフォマティクスは結局のところクラスタリングの問題に行き着く」と言われたことを覚えています。余談ですが、大学時代に同級生が「ギャンブルの終着駅は競輪だ」と言っていたのも想い出します。関係ないな。
正直素人が独自にコメントするなど蛇足の極み。私は浅瀬でパチャパチャ水遊びがせいぜいです。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。