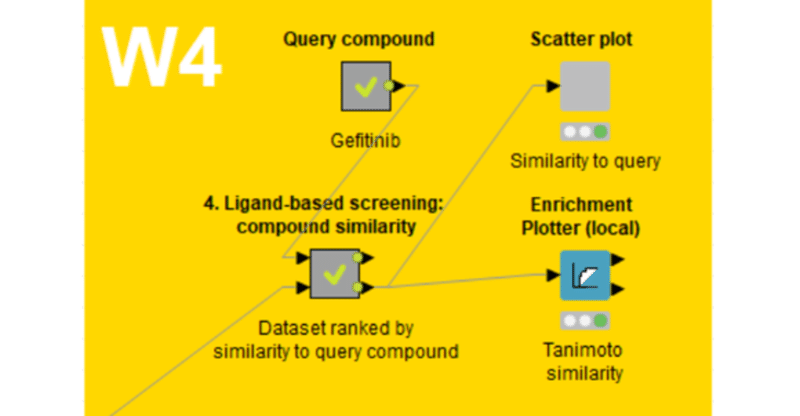
【W4】リガンドベーススクリーニング_07_Step3_前編

【本パート(W4)の目的】
化合物をエンコード(記述子、フィンガープリント)し、比較(類似性評価)する様々なアプローチを取り扱います。さらに、バーチャルスクリーニングを実施します。
上記はPython版のT4の説明ですが、W4の目的も同じです。
そのための教材として
既知のEGFR阻害剤ゲフィチニブ(Gefitinib)をクエリとして使用し、EGFRに対して試験済みの化合物データセットの中から類似した化合物を検索します。
Step1で化合物をエンコードし、Step2で類似性評価しました。
Step3ではバーチャルスクリーニングを体験しますが、その前に類似性評価の値の分布を可視化し、比較します。
【データ可視化機能に関して】
W2の体験時にも話題にしたのですが、データ可視化となると細やかな機能はPythonやRなどでのコーディングや、DataWarrior, Tableau, TIBCO Spotfireなどの可視化ツールにはなかなか及ばないのが実情です。
<参考>
KNIMEの基本的なノード群で実現できる可視化をしつつ、補足情報としてmagattacaさんの記事から可視化の結果を引用しながらコメントしていこうと思います。
前回おまけとして、Staticticsノードでは簡便なヒストグラム表示を体験しました。
今回はT4すなわちPythonでの可視化の結果を引用しておきます。
横軸は類似度(0から1)
縦軸は化合物数です。
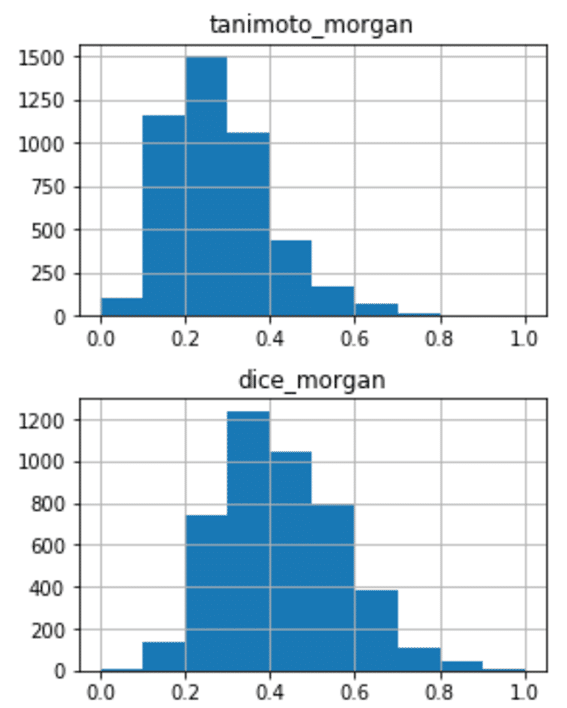
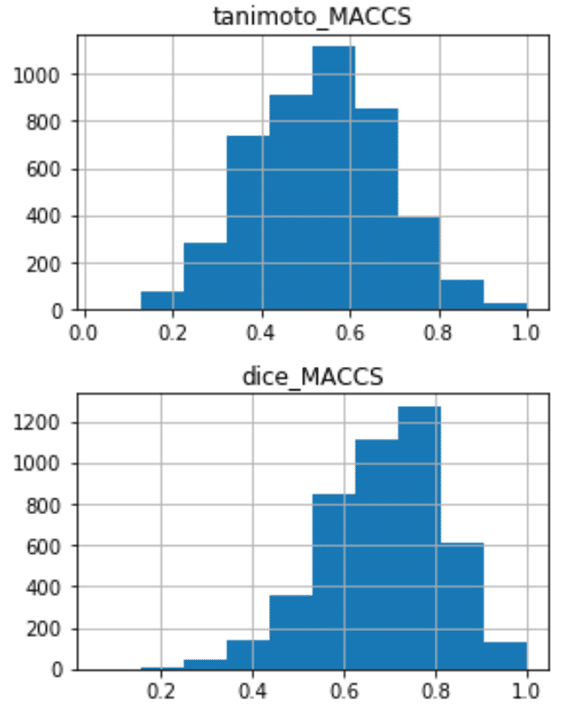
ヒストグラムに関しては、Pythonでもデータフレーム(下の例ではsimilarity_df)さえ適切に用意されていれば十分簡便に実現できるように感じたのでコードも引用しておきます。
%matplotlib inline
fig, axes = plt.subplots(figsize=(10,6), nrows=2, ncols=2)
similarity_df.hist(["tanimoto_MACCS"], ax=axes[0,0])
similarity_df.hist(["tanimoto_morgan"], ax=axes[0,1])
similarity_df.hist(["dice_MACCS"], ax=axes[1,0])
similarity_df.hist(["dice_morgan"], ax=axes[1,1])
axes[1,0].set_xlabel("similarity value")
axes[1,0].set_ylabel("# molecules")
plt.show()【類似性評価の値の分布】
解析結果は早速ですがMagattacaさんの記事から引用します。
理論編で述べたように、同じフィンガープリント(例 MACCSフィンガープリント)について比較すれば、タニモト類似度の値はDIce類似度の値よりも小さくなります。また、2つの異なるフィンガープリント(例 MACCSフィンガープリントとMorganフィンガープリント)を比較すると、類似性評価の値(例 タニモト類似度)は変化します。
先述のヒストグラムでも見て取れると思いますが、
今回は直接、2つのフィンガープリントに関するタニモト類似度とDice類似度を比較します。
【Scatter Plotコンポーネント】
Step3の上部「Scatter Plot」コンポーネントを見ていきます。
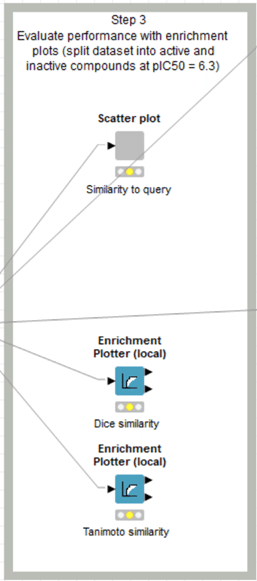
「Scatter Plot」コンポーネントの中身を見てみます。
ちなみに、
コンポーネントは入力画面を作ったり、出力に複数のチャートやビューを1つの画面で並べて表示させたい時などに使います。
「Scatter Plot」コンポーネントを右クリックし、
Component>Openを選択します。
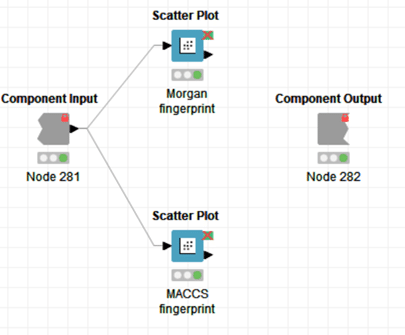
今回は2つの散布図を一つの画面に表示する設計になっています。
【Scatter Plot】Morgan fingerprint
Scatter Plotノードは意外なことにまっきーさんが扱っていません。
インフォコム社が日本語化したworkflowをKNIME Hubに上げてくださっていますので紹介しておきます。
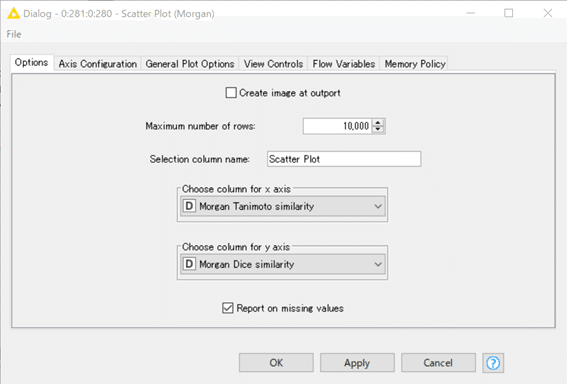
設定:
X軸はMorgan Tanimoto similarity
Y軸はMorgan Dice similarity
他のメニューやタブもいろいろ変えられますが、割愛して結果を見ます。
結果:
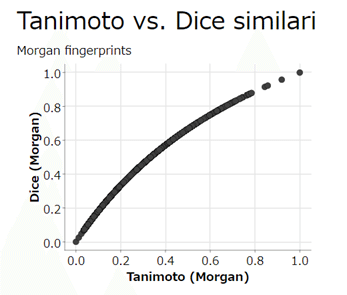
上に凸なので、Tanimoto よりDiceが全体で大きい傾向が見て取れます。
【Scatter Plot】MACCS fingerprint
Morganでの処理と同様なので割愛し、コンポーネントでまとめて表示した結果を示します。
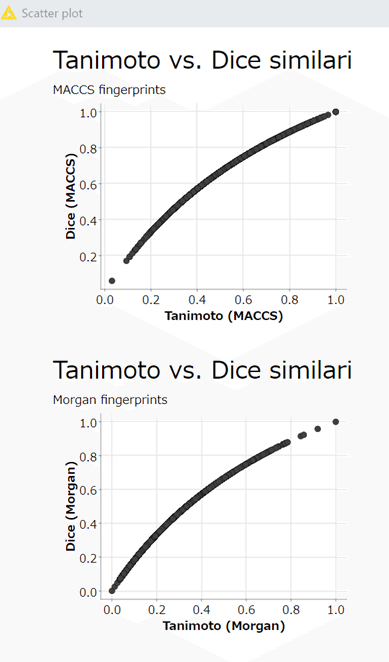
このコンポーネントはW4右上のものと全く同じ仕様なので、そちらの説明は省きます。
次回はW4の最終ステップであるエンリッチプロットについてです。
おまけ:
【Pythonでの可視化】
Magattacaさんのブログより、
類似度分布は類似度を解釈するのに重要です(例 MACCSフィンガープリントとMorganフィンガープリント、タニモト類似度とDice類似度について値0.6は異なる評価を与えられる必要があります)
またPythonでの可視化だとy = xの線を破線表示で重ねて示してくれているので、より見やすかったです。
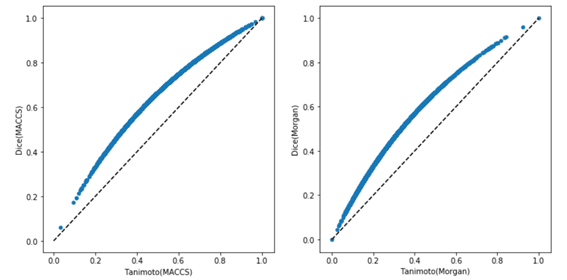
こういった可視化におけるこだわり部分はKNIMEで実装する方法を知らないです。
余談になりますが、玄人さんがKNIMEを使うとき、機械学習とか可視化はR SnippetやPython Scriptを使って連携する方が多いです。
ノーコードとコードの両刀遣いが最強と感じるところです。
特にt-kahiさんのクラスタリング3部作を推しておきます。本当に素晴らしい!
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。