【W7】活性予測のための機械学習モデル_16_Step3_10_RBFカーネル

【W7の目的】
ターゲット分子(EGFR)に対して新規な化合物の活性を予測するために、様々な教師あり機械学習(supervised ML)アルゴリズムを使用する方法について学習します。
前回はサポートベクトルマシン(SVM)について勉強しました。
【RBFはガウシアン】
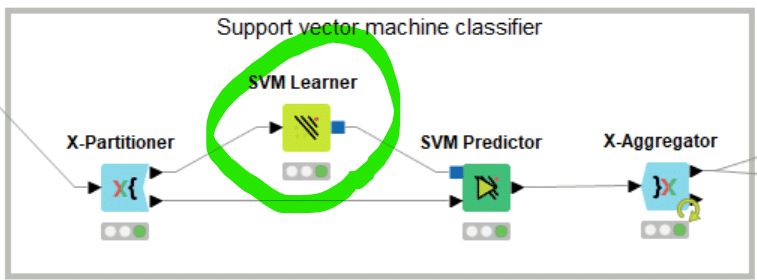
デモデータで体験するのもその一種、RBFカーネル(=ガウシアンカーネル)を用いる設定でSVM Learnerを実行します。

放射基底関数、英語でRadial basis function、略してRBFは、言葉として見ると難しそうだけど、
実際は何のことはない「距離に基づいて値が決まる関数」のこと。
変数xの原点からの距離を||x||で表せば、次のようになる。
φ(x)=φ(||x||)
代表的なのがガウス関数。
何のことはないとまでは思えなかったですが、RBFを選べばガウシアンカーネル関数を使うことができるようです。機械学習は開発の歴史の経緯で複数の名前を持つ技術がありますね。
そういえば類似度についても似たようなことがあったなと思いだしています。
RBFカーネル, ガウシアンカーネル, ガウスカーネルと私がいろいろ勉強している中でも3つの名前が出ていました。厳密には違いがありそうな気がしつつ、今回は区別なく取り上げていきます。
【SVM(RBFカーネル)のハイパーパラメータ】
SVMについて、
パラメータの調整さえ正しく行えば、手軽に精度が出せるので本研究室でも好んで使用されてきました。
と「ケモインフォマティクスのオンライン入門書。」でも紹介されてはいるのですが、そのパラメータ調整が重要そうです。
一方で、ha-te-knimeさんがSVM LearnerでのSVMを愉しんでおられるのですが、
デフォルト設定では期待に反して(むしろ期待通り?)精度が高くないそうです。
それでは世の中の皆さんはどうされているか?
例えば、
RBFカーネルを用いたSVMでは, 以下の2つのハイパーパラメータを調整します.
· コストパラメータ: C
· RBFカーネルのパラメータ: γ
コストパラメータCは, 誤分類をどの程度許容するかを決めるパラメータです.
CはSVMが解く2次計画問題の式に現れます.

Cが小さいほど誤分類を許容するように, 大きいほど誤分類を許容しないように超平面を決定します.
RBFカーネルのパラメータ: γは, 以下のRBFカーネルの式の中で現れます.

γの値が小さいほど単純な決定境界となり, 大きいほど複雑な決定境界となります.
Cとγを極端な値に設定したときの決定境界を描いてみます.
とPythonでのSVM実装結果を下図のように可視化して下さっています。

Cは2の-5乗と15乗に、γは-15乗と23乗にそれぞれ設定されたそうです。ふり幅が大きくて驚きました。
横軸と縦軸はそれぞれ2つの特徴量を表しています.
Cが小さいときは決定領域の中に多くの誤分類点を含んでいる一方で,Cが大きいときは決定領域内の誤分類点が少なくなっています.
γが小さいときの決定境界は単純な決定境界(直線)である一方で, γが大きいときの決定境界は複雑な形をしています.
ここまで上記数式や図もすべて引用です。感謝とともに。
ハイパーパラメータはデモデータでは固定で最適化はしないのですが、上記2つの最適化が精度や汎化性能に大きく影響することはよくわかる気がしました。
ガウスカーネルでのSVMを実装し、可視化してくれているサイトがありました。
上記のサイトをお勧めしたのは、ハイパーパラメータ2種のスライダーを動かしてインタラクティブにSVMの境界線を変えてみることができたので面白かったからです。
【コストパラメータ】
ではKNIMEでの実装に向けてSVM Learnerノードの設定画面を再び見てみます。
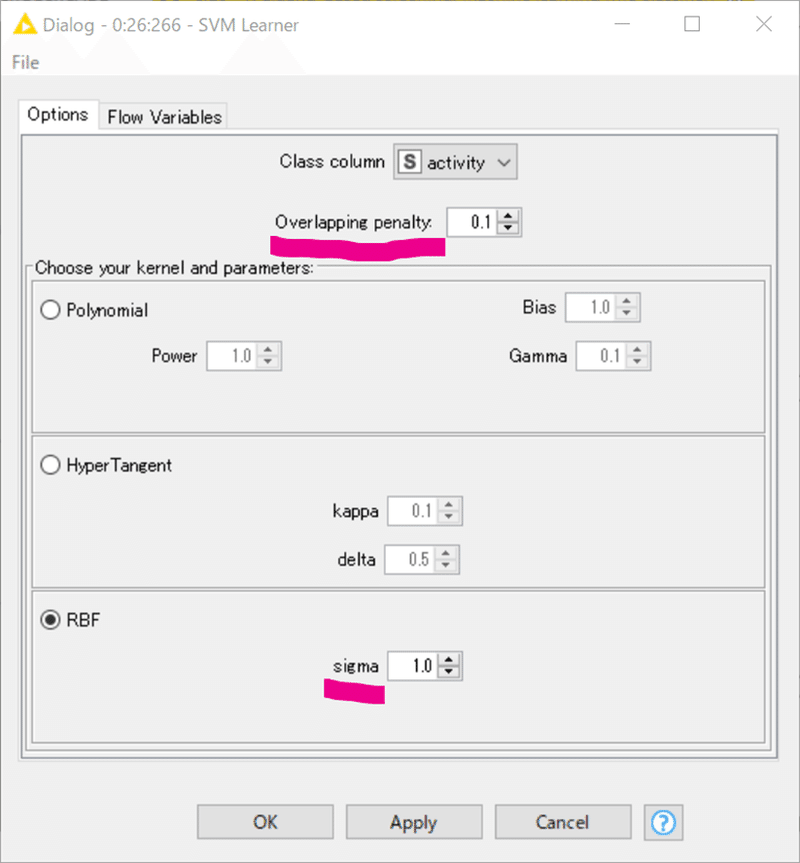
「コストパラメータCは, 誤分類をどの程度許容するかを決めるパラメータです.」とのことですので、Overlapping penaltyがCに当たるでしょう。
コストパラメータOverlapping penalty = 0.1は小さめな設定だなぁと感じたのですが、どのあたりがいいのかを知っているわけでもありません。むしろ解くべきデータの分布に合わせるほかないと考えます。本来は与える学習データが変わるたびに最適化が必要ではないでしょうか?
そこでt-kahiさんの優れたブログ記事を紹介します。
ハイパーパラメータ最適化のためにグリッドサーチされていますね。
一般的にはSVMのコストパラメーターとかは指数で範囲設定するのですが,このノードではそれができない(悲しい)ので,とりあえず範囲を設定しています
ともコメントされています。
もうこの記事を紹介したら私のここまでの話って要らなかった気もしますが、さらにもう少し。
【ハイパーパラメータσの謎】

さてここまであちこちのサイトを転々としながら、SVMの勉強をしてきました。ところがこの複数サイトをまたいだ勉強法だと結構悩むことがあります。
同じことを説明するための数式の表記が違うことがあるのです。
ちなみに先述のハイパーパラメータγ(ガンマ)はσ(シグマ)として書かれているサイトもいくつかありました。
例えば前回にも紹介したこちら。

先述の式と同じようですがγでなくσで記述されています。
σを上げ過ぎて過学習しているケースなども示してくださっています。
SVM LearnerノードのRBFカーネルは先ほど示した設定画面のsigmaで決定境界の複雑さを制御するでしょう。
ところがです。SVM LearnerノードのRBFカーネルはどうやら上記の式ではないようです。
気になるRBFカーネルの別式がありました。

KNIMEのSVM Learnerノードのsigmaはどっちなのかでsigmaを大きくしたときに決定境界の複雑さが増すのか減るのかが変わりますよね。どっちなんだろうと思って行き詰ってKNIME日本コミュニティに相談してみました。
なんと、どちらでもなかったです。
ソースコードを見た感じでは、2×sigmaの2乗っぽいので、こちらの式じゃないですかね。ですのでsigmaが減少するにつれて過剰適合するのではないかと思います。
ソースコードまで確認してくださり もう感涙ものです。
「 return Math.pow(Math.E, -result / 2.0 / m_sigma / m_sigma);」
の部分を指しておられると思います。Javaを読めていませんが。
つまり下記の式であろうかと思います。
<参考>
RBFカーネルは、カーネル化の最も一般化された形式であり、ガウス分布と類似しているため、最も広く使用されているカーネルの1つです。2つの点X1とX2のRBFカーネル関数は、類似性またはそれらが互いにどれだけ近いかを計算します。このカーネルは、数学的に次のように表すことができます。

またも定性的な理解となってしまいますが、σ(sigma)が減少するにつれて、モデルの決定境界は複雑な形になり、場合によっては過学習する傾向があります。先述したγと違って2乗で効いてくるようです。
ハイパーパラメータをうまくチューニングするのに正直手作業では難しいのでしょうね。玄人の方々はどうされているのでしょうね。
【ハイパーパラメータのベイズ最適化の例】
KNIMEでのSVMのハイパーパラメータをベイズ最適化した記事があります。
t-kahiさんがSVM Learnerノード単独ではできないと嘆いていた指数(2の累乗)で最適化の範囲設定をする、すなわちハイパーパラメータが2の何乗かを整数値で指定するWFを実装されています。後日改めて扱いたいです。
以下はKNIMEではないですが目で見てわかるベイズ最適化の実例をご覧ください。
KNIMEでもSVMでもないですけど、Optunaの詳しい検討例紹介に圧倒された記事を引用してここまでにします。
さて、すっかり深入りしてしまったのでそろそろ次へ。デモデータの内容を見てみましょう。
おまけ:
【mishima.syk#18参加しました】
尊敬してやまないmishima.syk#18に参加しました。
@tkochi0603
の
「KNIMEをSlurmで動かす話」
はこれがKNIMEの話なのかと驚く高度さでした。
mishima.sykのコアメンバー方々の活躍を見ていていつも思い出すのは、
勝負事で本当に楽しむ為には、強さが要る
の言葉です。今回の記事でもInfocomのOさんからSVM Learnerのソースコードまでみてご助言いただいたときも同じ気持ちになりました。
KNIMEに魅せられて非プログラマーでも何かできないかともがいて日々過ごしていますが、玄人の皆さんはそんな私にでも手を差し延べてくださいます。コミュニティーの中心にいる皆さんへの圧倒的な感謝をあらためて噛みしめているところです。
エモくなってきたうえに4000字近く書いているのでこの辺で。
おまけの蛇足:
【ギリシャ文字だと何かとややこしい】
上記のガンマとシグマのくだりを書いててふと連想したことを書いておきます。
もし「α,βの次は?」と質問されて正解がγ(ガンマ)でなかったとしたら、もちろんσ(シグマ)じゃなくΩ(オメガ)でしょって思った人は何人いますかね。
機械学習とは全く関係がなく、かつこれ以上詳しい説明はこのnoteでは避けるべきなのでここまでとします。
It’s all Greek to me.
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。