【W7】活性予測のための機械学習モデル_13_Step3_07_ANN_RPrep

【W7の目的】
ターゲット分子(EGFR)に対して新規な化合物の活性を予測するために、様々な教師あり機械学習(supervised ML)アルゴリズムを使用する方法について学習します。
前回で人工ニューラルネットワーク(ANN)の基礎概念まで学習してきました。
【RProp MLP Learnerの説明だけでも1章かかる】
KNIMEのworkflowは一見簡単に見えますよね。
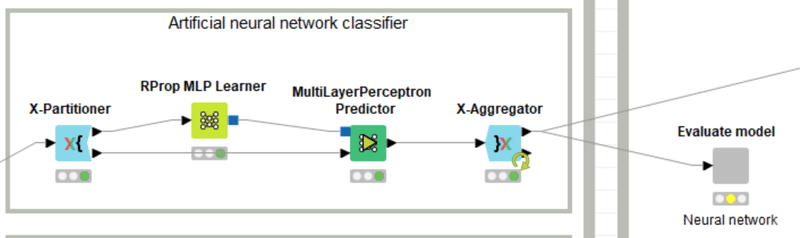
もうランダムフォレスト(RF)で、k分割交差検証する例を見ました。
アルゴリズムがRFからANNに変わったのに合わせて、KNIMEノードが置き換わっただけです。ただしこのノードに盛り込まれている技術は先週だけでは紹介しきれなくて今週もその続きをしています。
先週ANNのためのノードの1種であるRProp MLP LearnerのMLPとは多層パーセプトロンのことですという話をしました。まだRPropを取り上げていませんでした。
日本語化されたディスクリプションによると、
RPROPは、誤差関数の振る舞いに応じて、重み更新の局所的な適応を行います。
この文章を読んだだけで、理解には数学必須とわかるので、深追いはやめたのですが前回同様にインフォマジシャン研究所で藤さんから定性的な特徴は教えていただきましたので紹介しておきます。
RPropは
バックプロパゲーション(逆誤差伝播法)を改良した手法
のようです
RPropにはバックプロパゲーションと比べて2つの利点があるようです。
1つ目は、バックプロパゲーションよりも学習時間が速い、
2つ目は、バックプロパゲーションでは学習率(Learning Rate)を設定する必要がある一方で、RPropではパラメータの設定が必要ない
とのことです
RPropの欠点としては、バックプロパゲーションよりもアルゴリズムが複雑で、実装するのが難しいようですが、既にKNIMEのノードになっているので、そこは問題ないですね
そしてより理解を深めるにはとまずはバックプロパゲーション(逆誤差伝播法)の勉強をお勧めいただきました。
よびのりの動画の11分50秒くらいででてくる学習係数 η(イータ)をRProp独自のルール
Each weight is changed by its own update value, in the opposite direction of that weight’s partial derivative, so as to minimize the total error function, η+ is empirically set to 1.2 and η- to 0.5
としているようで、これがディスクリプションにあった「誤差関数の振る舞いに応じて、重み更新の局所的な適応」にあたるようです。

さらに補足して情報もいただきました。藤さん、改めましていろいろと教えていただきましたこと感謝します。
例えば、KNIMEのMuitiPerceptronノードを使うと、Optionsの中でL: Learning Rate for the backpropagation algorism (Default = 0.3) というhyperparameterを設定する必要があります。
<参考>MultilayerPerceptronノード
この値をRPropでは設定する必要がないのですね。
ちなみに、縦軸が誤差、横軸がweightのグラフ(YouTubeの9:25くらいのところ) で誤差を最小化するときに、学習係数が大きいと、weightの変化 (X軸方向の動き) が大きくなり、なかなか収束しません。
始めは学習効率を大きくして、Local Minimumに落ちないようにしますが、ある程度Global Minimumの近くになってきたら、学習効率を小さくすることで、細かくGlobal Minimumを探し出すことができるのです。
逆誤差伝播法を使う時には、このような工夫が必要です。
【RProp MLP Learnerの強みを知って】
KNIMEでのANN実装例のWFではRProp MLP Learnerがしばしば使われてきました。
下記の記事、ドイツ語で書かれてますが、Chromeで日本語訳して読めます。
彼らの報告では標準設定でAccuracy = 73.7%との精度が観測されたのですが、
興味深いことに、さまざまなハイパーパラメータを(非体系的に)テストした場合でも、75%を超えることはほとんどありませんでした。
標準設定ですでにより高いレベルの精度を持っていました。
学習効率というハイパーパラメータの調節は、本来上述のように注意深く行う必要があるので初心者にはなかなか難しいのですが、RPropをノードで実装してくれているからこそ、手軽にANNを体験できるということなのかもしれないと思いました。TeachOpenCADDは初心者にケモインフォマティクスを体験してもらうことが主目的ですから、この選択がベストではないでしょうか。
藤さんから教わったことの紹介で1章を終わりました。次回こそはWFを実行してみましょう。
おまけ:
【有償コミュニティの価値を考える】
有償コミュニティであるインフォマジシャン研究所の参加メンバーはケモインフォマティクスに関しての情報交換や質問ができるのですが、2021年の夏にはKNIME研究室も立ち上げてくださいました。
玄人さん達はPythonでの最新技術の実装例などを議論されていますが、私のような初心者にとってはKNIMEを利用して基礎的な技術概要を教わることができることもありがたいです。
過去に幾つかの無償コミュニティに参加してきたのですが、COVID-19禍などの影響もあって休眠状態になってしまい寂しく思っています。
ずいぶん前の話になりますが、ケモインフォマティクスの大御所の方が、いろいろな無償のコミュニティで運営者が素人の質問対応で疲弊していくのを見て、質問する側の事前の勉強不足を憂いておられたことを忘れられずにいます。
Py4cheminformaticsなどはまさに初心者がまずここまでは独力で学んでから玄人への相談をするようにと工夫されているのかもと想像しています。
一方で、有償のコミュニティだから何でも1から聞いていいわけではないですが、今回のような質問に真摯に対応いただける機会が得られることに本当に感謝しています。上記のMuitiPerceptronノードと比較してRProp MLP Learnerノードの特長を説明いただいた時は感激しました。主宰者の藤さんは講演や動画教材作成などの経験が豊富なだけあって人にわかりやすく教えることが上手です。
皆さんがもし一緒に勉強してみたくなったら、DMなどでお声がけください。紹介キャンペーンもあるし、どんな会なのかより詳しくお話しできます。
実のところこのnoteを始めた重要なきっかけも藤さんから頂きました。末永くよろしくお願いしたいと思っています。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。