【W5】化合物クラスタリング_03_Step2.1_前編

【W5の目的】
・化合物をグループ化する方法と、多様性のある化合物セットを選ぶ方法
を学びます。Python版TeachOpenCADDのT5が対応しますが、こちらはより発展的です。
W5の本体であるメタノード「5. Compound clustering」
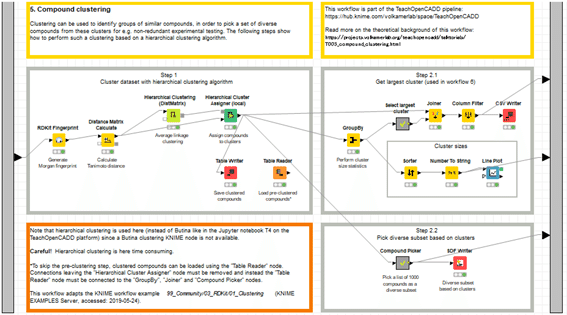
のStep1で階層型クラスタリングを体験しました。
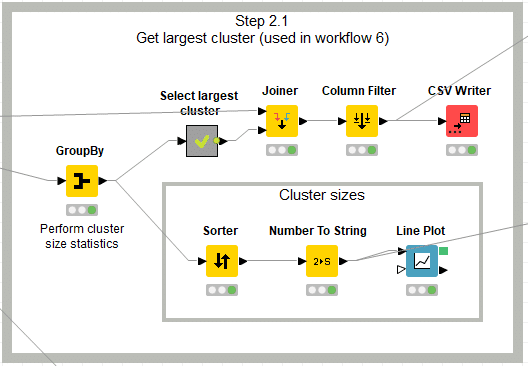
Step2.1ではクラスターサイズを算出してデータ処理します。今回は上下に分岐しているうちの上部のworkflowだけ扱います。最大のクラスターを抽出します。
【GroupBy】
GroupByは何度か紹介済みです。
設定:
各クラスターのIDであるCluster numberで集計します。
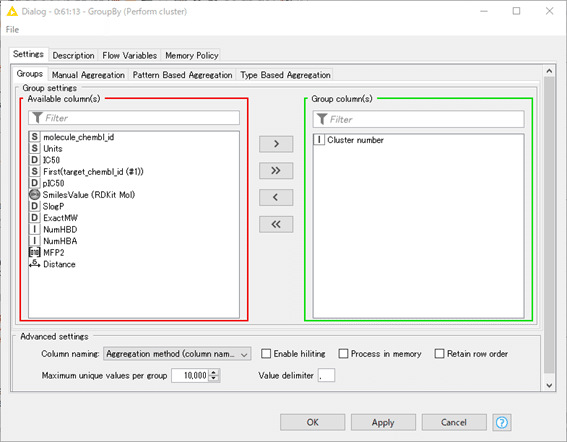
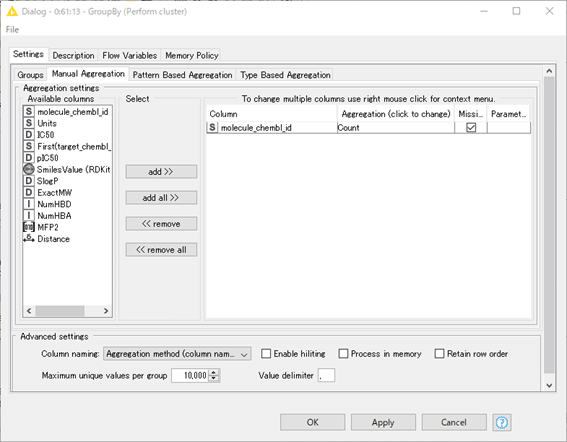
化合物にとって一意のIDであるmolecule_chembl_idの数を数えれば化合物数がわかります。
結果:
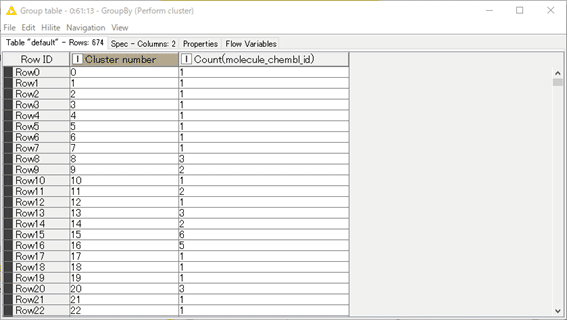
674個のクラスターへ分類されています。しかし一見してわかる通り、Cluster number 0~7, 10, 12, …と化合物数が1つだけのシングルトンがかなりありますね。
次回になりますが分布をみます。
今回は最大のクラスターを抽出します。
【メタノード ”Select largest cluster”】
わざわざメタノードにしてありますが、中身は2つのノードです。
【Sorter】
化合物数で降順に並べ替えます。
設定:
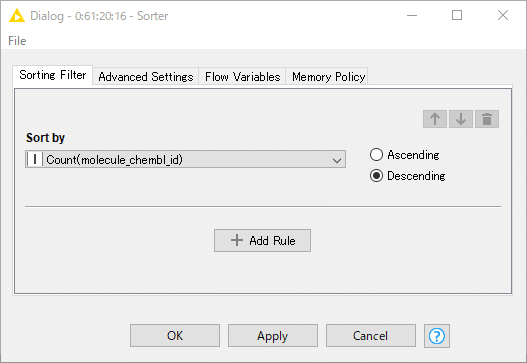
結果:
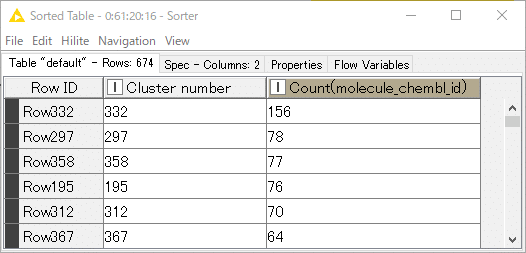
クラスターのIDが”332”のクラスターが最多の156化合物で構成されています。
【Row Filter】
日本語化されたディスクリプションより
ノードでは、特定の基準に従って行をフィルタリングできます。特定の範囲(行番号による)、特定の行IDを持つ行、および選択可能な列(属性)内の特定の値を持つ行を含めることも除外することもできます。
今回は一番上の1行だけに絞ります。
設定:
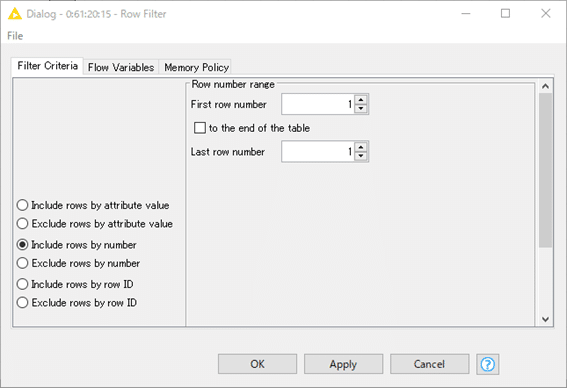
結果:
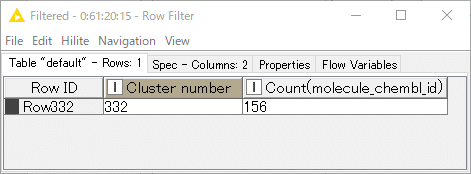
見ての通りです。
この後Cluster number“332”をキーにデータ抽出処理をします。
【Joiner】
Joinerも何度か利用してますね。
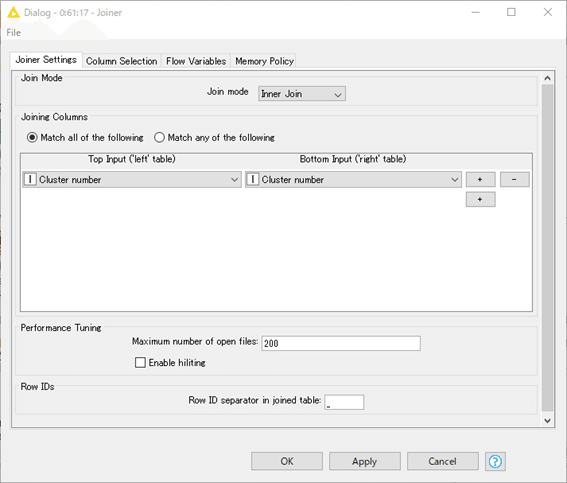
設定:
Inner JoinでCluster number“332”のデータを集めてきます。
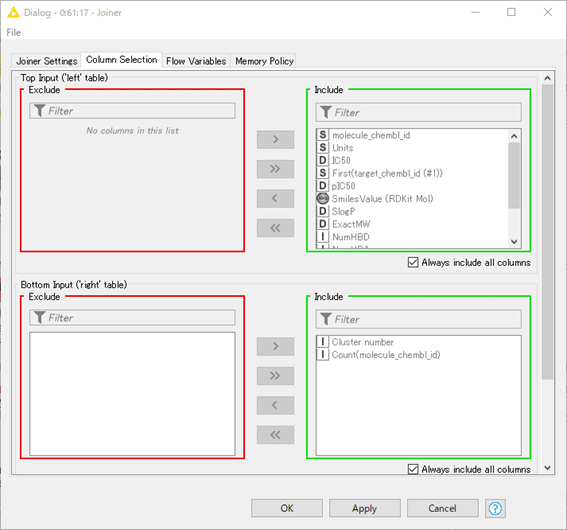
すべてのカラムを取ってくる設定になっています。
直後にColumn Filterでカラムを絞っているので、ここでまとめて処理してもよさそうに思います。
結果:
Cluster number“332”の156化合物の全データが取れました。
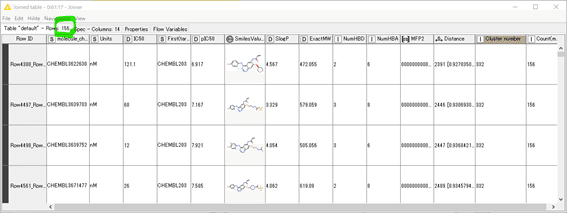
【Column Filter】
頻出ノードですね。
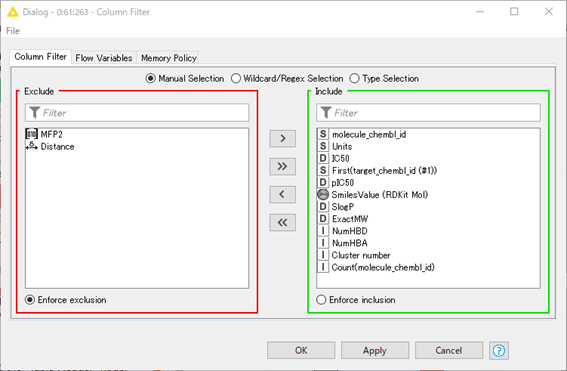
設定:
フィンガープリントと距離ベクトルを除いています。
結果は省略させていただきます。
ここで出力された156化合物のデータは、W6でMCS解析に用いられます。詳しくはその時にまた。
【CSV Writer】
頻出ノードなのでまっきーさんの記事の再掲で以下略とします。
今回は以上です。次はStep2.1の下部を扱います。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。