榊の字形について

「榊」という文字は、同じ文字なのに使うソフトウェアによって「木示申」と「木ネ申」のどちらも表示されることがあります。それはなぜなのか、どちらかを明示する方法はあるのかを調べました。
まとめ
・榊の字形には「木示申」と「木ネ申」がある。
・JIS の標準が「木ネ申」から「木示申」に変化したため、使うフォントによって字形が異なる。
・Unicode では、榊 (U+698A) の字形は使用言語によって異なる。日本語では「木示申」、中国語では「木ネ申」
・Unicode では、「木示申」と「木ネ申」は異体字 (IVS) によっても明示できる。
「木ネ申」を明示的に表示させるには、
<span lang="zh">榊</span>
U+698A U+E0100
U+698A U+E0102
のいずれかでできる。ただし、結局は使用するフォントに依存する。
はじめに
あるツイートがきっかけで、榊の特定の字形を表示する方法を調べてみました。調べていくにつれ、文字の標準化に対するいろいろな歴史的経緯が分かって面白かったです。間違っていたり言葉足らずなところがありましたら、教えてください。
「結局は異体字なんじゃないかな」とは思って調べていましたが、それ以外にもいろいろあったのは勉強になりました。
きっかけ
この時点では「へー、榊って示の方もあるんだ。フォントによって違うとはどういうことなんだろう?」という程度の理解でした。
フォントによる字形の違い

「榊」は Unicode のコードポイントでは U+698A です。このコードポイントがどのように見えるかは、使用するフォントによって異なります。一般的にはどのフォントを使っても、文字の構造は変わらないはずです。しかし、榊の場合は、フォントによって明らかに構造が異なります。これはどうしてなのでしょうか?
JIS 規格による「榊」の例示字形の変更
日本語の文字をコンピューター上でどのようにやりとりするかを取り決めは、JIS 規格として標準化されています。規格の中では、それぞれの文字がどのような形として表示されるべきかも、例示字形として示されています。
「榊」の例示字形は、JIS X 0213:2004 と呼ばれる JIS 規格から、これまでの「木ネ申」から「木示申」に変更されました。この変更は、国語審議会の「表外漢字字体表」に合わせるためだそうです。

上から3番目・左から1番目が「榊」
例示字形が変更されたことにより、それ以降に作成されたフォントでは、榊を「木示申」と表示するようになったのでしょう。これまでとの互換性のために、あえて「木ネ申」のままにしているフォントもあるかもしれません。
参考: https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q1224417132
例えば Adobe のフォントでは、StdN や Pr6N のように、名前に N が付いていると JIS X 0213:2004 の字形に対応しているフォントです。(@kotarok さんに教えてもらいました)
参考: https://fontnavi.jp/zakkuri/303-adobe-japan1.aspx
JIS 規格と「榊」等の字形の変更については、「神と神、榊󠄀と榊 常用漢字表拡大のインパクト」でとても詳しく背景が紹介されています。 (@tushuhei さんに教えてもらいました)
Unicode ではどうなのか
JIS 規格だけではなく、Unicode の例示字形も確認します。Unicode の例示字形は使用する言語 (ロケール) ごとに違います。
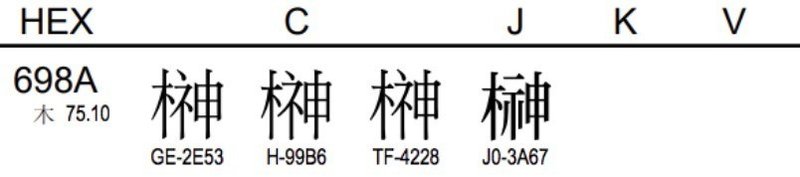
Unicode の CJK Unified Ideographs から抜粋 (178 ページ目)
コードポイント U+698A (榊) の例示字形は、中国語 (簡体字・香港と台湾の繁体字) では「木ネ申」、日本語では「木示申」、韓国語とベトナム語では該当なしとなっています。日本語に対しては JIS X 0213:2004 と同じ字形です。
Unicode では U+698A (榊) というコードポイントは、中国語として解釈する場合は「木ネ申」を表示して、日本語として解釈する場合は「木示申」を表示するということのようです。
Unicode の例示字形も Unicode 8.0 以前までは、日本語も「木ネ申」でした。JIS 規格に合わせるために「木示申」に変更されました。
余談
Unicode の例示字形に関連して、筆者は以前、波ダッシュ記号「〜 (U+301C)」の例示字形を変更する提案をしたことがあります。Unicode 8.0 から変更されました。
https://internet.watch.impress.co.jp/docs/special/691658.html
使用する言語による字形の明示
HTML の場合、次のように書けば使用する言語 (ロケール) を指定できます。
<span lang="zh">榊</span>
<span lang="ja">榊</span>
ja が日本語、zh が中国語を指定しています。macOS + Chrome + Noto font の組み合わせでは、次のように期待通りの結果で表示されました。ただし、前述の通り、使用するフォントなどによっては違う表示結果になります。

左: lang="zh" 右: lang="ja"
Wikitionary では、この手法で「木示申」と「木ネ申」を書き分けていました。

余談
いわゆる「中華フォント」と呼ばれている問題も、主にこの使用言語の設定が原因です。中国語などが日本語よりも優先する設定になっているために、「直」や「刃」などが日本語とは違う字形になります。
異体字セレクターによる明示
Unicode では、異体字セレクターという手法によっても、文字の表記の違いを明示することができます。この手法で明示する方が、技術的には、今回の意図には沿っているでしょう。
榊に対しては、IVS (Ideographic Variation Sequence) という手法で、「木示申」と「木ネ申」を書き分けることができます。具体的には「基底文字のコードポイント」の後に「異体字セレクターのコードポイント」を続けて指定します。絵文字のスキントーンと同じ指定方法です。
具体的には、次のようにして書き分けます。
・ U+698A U+E0100 : 「木ネ申」
・ U+698A U+E0101 : 「木示申」
HTML の場合、次のように書けば、異体字セレクターのコードポイントをエスケープ文字として表記できます。もちろん、他の文字と同様にエスケープしないでも書けます。
榊󠄀
macOS + Chrome + Noto font の組み合わせでは、次のように期待通りの結果で表示されました。

異体字セレクターの重複
実は、榊 (U+698A) には 4 通りの異体字セレクターがあります。異体字セレクターの情報は、Unicode のデータベースから参照できます。
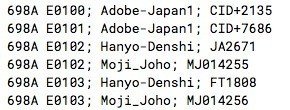
それぞれの字形も pdf ファイルから参照できます。
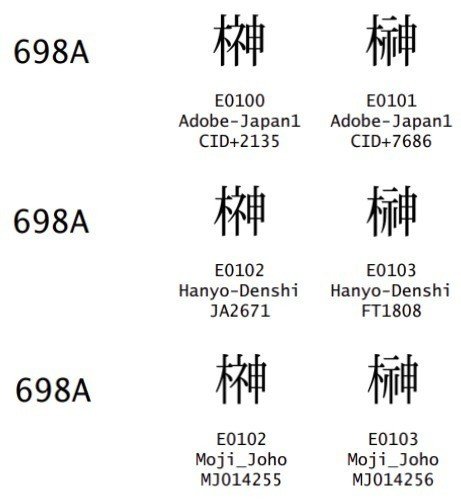
見比べてみると、 U+E0100 と U+E0102、U+E0101 と U+E0103 はまったく同じように見えます。その経緯は「日本の文字とUnicode 第6回 続続・漢字とUnicode」によると、「別々の団体からの重複した提案を、Unicode が重複したまま採択したから」だそうです。どうしてそうなったのかも興味はありますが、今回は追っていません。
異体字セレクターと対応フォント
さて、では U+E0100 と U+E0102 のどちらを使っても同じ表示結果になるのでしょうか。理論上ではその通りなのですが、実際の答えは残念ながら「環境による」です。現実はつらいですね。
使用するフォントが対応しているかによって、表示結果が変わります。次の例では、Noto Sans フォントは U+E0102 に対応していなくて、IPAmg明朝フォントは U+E0100 に対応していないことが分かります。(行間も調整せずに、それぞれのフォントのままにしました)


Noto フォントや IPA フォントは、守備範囲の広いフォントというのが筆者の個人的な認識です。そのどちらもが、U+E0100 と U+E0102 の両方には対応していないとなると、はたして両方に対応しているフォントは、現時点で存在するのでしょうか。個人的には、どちらか一方の記法に集約してもらえる方がありがたいですけれど。
この状況を踏まえると、なぜ Wikitionary が異体字セレクターではなく、使用する言語で表示字形を変更したのかが想像できます。中国語の字形を表示できる環境の方が、異体字セレクターを期待通り表示できる環境より多いとの判断なのでしょう。妥当な判断だと思いました。
CJK 互換漢字
Unicode には CJK 互換漢字という領域があります。この領域は、Unicode 以外の文字コードとの互換性のために用意されています。
この領域には、例えば JIS X 0213 用の互換漢字として「神 (U+FA19)」や「福 (U+FA1B)」などが含まれています。「神 (U+795E)」および「福 (U+798F)」と区別するためです。
神 (U+FA19) 神 (U+795E)
福 (U+FA1B) 福 (U+798F)
ですので、榊に対応する互換漢字もあるのかなと調べたのですが、ありませんでした。互換漢字がないことは、Unicode.org の Unihan data からも確認できます。
神: https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=795E
榊: https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=698A
神の方には Variants という項目に U+FA19 への参照がありますが、榊の方には Variants という項目自体がありません。

この理由は、「神」は JIS X 0213 で「神」とは別の文字として新しく文字コードが割り当てられたのに対して、「榊」は例示字形の変更だけで、新しい文字コードが増えたわけではないからなのでしょう。
また、CJK互換漢字として登録されていたとしても、Unicode の正規化によって基底文字との区別がなくなってしまいます。使用目的よっては、結局は IVS の方が使いやすいこともあります。
参考:
・Wikipedia: CJK互換漢字#日本語処理における問題点
・日本の文字とUnicode 第5回 続・漢字とUnicode
まとめ
最初のまとめと同じ内容です。
・榊の字形には「木示申」と「木ネ申」がある。
・JIS の標準が「木ネ申」から「木示申」に変化したため、使うフォントによって字形が異なる。
・Unicode では、榊 (U+698A) の字形は使用言語によって異なる。日本語では「木示申」、中国語では「木ネ申」
・Unicode では、「木示申」と「木ネ申」は異体字 (IVS) によっても明示できる。
「木ネ申」を明示的に表示させるには、
<span lang="zh">榊</span>
U+698A U+E0100
U+698A U+E0102
のいずれかでできる。ただし、結局は使用するフォントに依存する。
おわりに
「結局は異体字なんじゃないかな」という当初の予想は、外れてはいませんでしたが、なぜこれが異体字になったのか、そもそも異体字を表示できる環境はあるのかという点では、いろいろと勉強になりました。間違っていたり言葉足らずなところがありましたら、教えてください。
一般公開前に、次の方々からフィードバックをいただきました。ありがとうございます。@call_cc @kotarok @miuraken @tushuhei @ymotongpoo
参考 URL
https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q1224417132
https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q1421546559
https://fontnavi.jp/zakkuri/303-adobe-japan1.aspx
http://kanji.zinbun.kyoto-u.ac.jp/~yasuoka/publications/2008-03-21.pdf
https://www.taishukan.co.jp/kokugo/webkoku/series003_04.html
https://www.taishukan.co.jp/kokugo/webkoku/series003_05.html
https://www.taishukan.co.jp/kokugo/webkoku/series003_06.html
https://ja.wikipedia.org/wiki/CJK統合漢字
https://ja.wikipedia.org/wiki/JIS_X_0213
https://ja.wiktionary.org/wiki/榊
https://www.unicode.org/charts/PDF/U4E00.pdf (榊: U+698A)
https://unicode.org/ivd/data/2017-12-12/IVD_Charts_Adobe-Japan1.pdf
https://unicode.org/ivd/data/2017-12-12/IVD_Charts_Moji_Joho.pdf
https://www.unicode.org/charts/PDF/UF900.pdf 神 (U+FA19)
http://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=698A
http://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=795E
この記事が気に入ったらサポートをしてみませんか?