
マルチ画像チャットアプリを作る:GPT-4 Vision x Vercel AI SDK:実験・開発レポート

Vercel AI SDK が OpenAI Assistants & Vision API に対応したので早速実験です。今回は Vision API を使って、画像をもとにチャットするアプリの開発にトライしてみます。
Vercel AI SDK って何?については、以前のnoteで簡単に書いてます↓
まずはシンプルに作る
Next.js アプリの作成
npx create-next-app@latestモジュールのインストール
npm install ai openaiOpenAI API キーの追加
ルートディレクトリに .env.local ファイルを作成して、OPENAI_API_KEY にシークレットキーをセットします。
OPENAI_API_KEY=sk-****コードの記述
Vercel AI SDK の examples にあるコードをそのまま使って動作を確認してみます。
app/api/chat-with-vision/route.ts ファイルを新規作成して以下のコードを記述します:
import OpenAI from 'openai';
import { OpenAIStream, StreamingTextResponse } from 'ai';
// Create an OpenAI API client (that's edge friendly!)
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY || '',
});
// IMPORTANT! Set the runtime to edge
export const runtime = 'edge';
export async function POST(req: Request) {
// Extract the `prompt` from the body of the request
const { messages, data } = await req.json();
const initialMessages = messages.slice(0, -1);
const currentMessage = messages[messages.length - 1];
// Ask OpenAI for a streaming chat completion given the prompt
const response = await openai.chat.completions.create({
model: 'gpt-4-vision-preview',
stream: true,
max_tokens: 150,
messages: [
...initialMessages,
{
...currentMessage,
content: [
{ type: 'text', text: currentMessage.content },
{
type: 'image_url',
image_url: data.imageUrl,
},
],
},
],
});
// Convert the response into a friendly text-stream
const stream = OpenAIStream(response);
// Respond with the stream
return new StreamingTextResponse(stream);
}参照元:https://github.com/vercel/ai/blob/main/examples/next-openai/app/api/chat-with-vision/route.ts
app/page.tsx ファイルを以下のように書き換えます:
'use client';
import { useChat } from 'ai/react';
export default function Chat() {
const { messages, input, handleInputChange, handleSubmit } = useChat({
api: '/api/chat-with-vision',
});
return (
<div className="flex flex-col w-full max-w-md py-24 mx-auto stretch">
{messages.length > 0
? messages.map(m => (
<div key={m.id} className="whitespace-pre-wrap">
{m.role === 'user' ? 'User: ' : 'AI: '}
{m.content}
</div>
))
: null}
<form
onSubmit={e => {
handleSubmit(e, {
data: {
imageUrl:
'https://upload.wikimedia.org/wikipedia/commons/thumb/3/3c/Field_sparrow_in_CP_%2841484%29_%28cropped%29.jpg/733px-Field_sparrow_in_CP_%2841484%29_%28cropped%29.jpg',
},
});
}}
>
<input
className="fixed bottom-0 w-full max-w-md p-2 mb-8 border border-gray-300 rounded shadow-xl"
value={input}
placeholder="What does the image show..."
onChange={handleInputChange}
/>
</form>
</div>
);
}参照元:https://github.com/vercel/ai/blob/main/examples/next-openai/app/vision/page.tsx
サーバーの起動
npm run devブラウザで http://localhost:3000 にアクセスします。
動作確認
チャットエリアに「これは何ですか?」のように入力すると、スズメの写真であることの回答があるはずです。これは先ほど記述したコードを見るとわかる通り、フォームに予めスズメの画像のURLがセットされているためです。
簡単な動作確認はできましたが、これでは面白くありません。もう少し実用的にしてみましょう。
実用的なアプリにして試す
チャット画面で画像を入力する
複数の画像を入力する
入力した画像を削除する
このくらいの機能は実装して試したいところ。今はAIのおかげでサクッと実装できてしまうのでありがたいです。
機能の追加
まず画像の入力フィールドを追加する、そして入力した画像のURLをルートハンドラに渡せるようにするわけですが、ローカルの画像は Base64 エンコード形式にする必要があります(ドキュメント)。シングル画像の受け渡しとチャットがうまくいったら、次は複数の画像を配列で受け渡しできるようにしてみます。最後に入力した画像を削除するための関数を追加。
こんな感じで特に難しいことはありません。ChatGPTと会話をしながらある程度コードの生成とデバッグをしてもらって、あとは部分的に手直しするだけです。
ソースコードはこちらにあります↓
動作確認
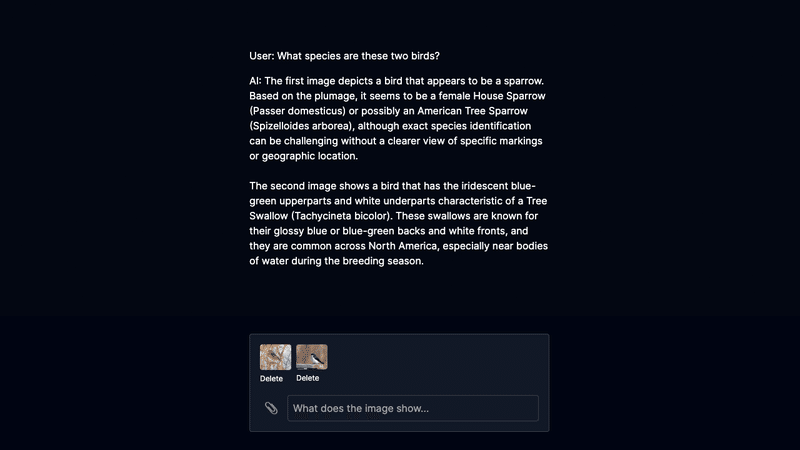
こんな感じでマルチ画像のチャットにも対応でき、完璧に機能しています。(もちろん日本語でのチャットにも対応しています。)
実験終了。
次回は Assistants API の実験・開発レポートをお届けします。
X/Twitter (@komzweb) でも投稿してますので、是非フォローしてください!
この記事が気に入ったらサポートをしてみませんか?