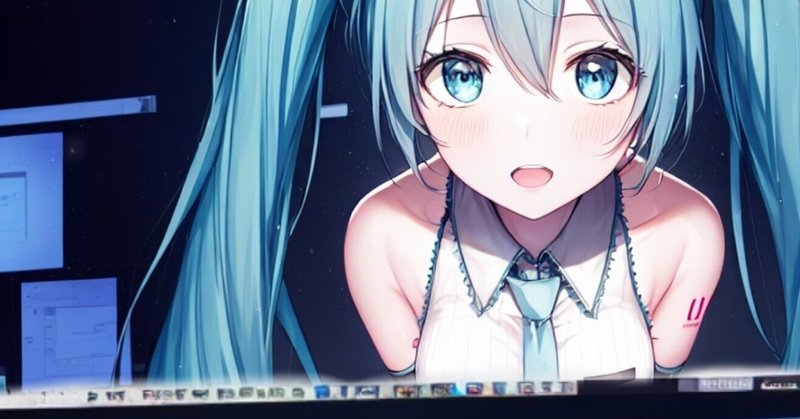
LCM-LoRAをcpuを使ってリアルタイム AIイラスト

自分のaituberの配信で使う為にCPUでLCM-loraを使うコードを書いたので共有します。
import cv2
import numpy as np
import pygetwindow as gw
import pyautogui
import torch
from diffusers import AutoPipelineForImage2Image, LCMScheduler
# 事前学習されたモデルの設定
lcm_lora_id = "latent-consistency/lcm-lora-sdv1-5"
# diffusersパイプラインの初期化(torch.float32を使用)
pipe = AutoPipelineForImage2Image.from_pretrained(
"852wa/SDHK", use_safetensors=True
).to("cpu") # CUDAからCPUに変更
# LORAウェイトのロード
pipe.load_lora_weights(lcm_lora_id)
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# セーフティチェッカーの設定
if pipe.safety_checker is not None:
pipe.safety_checker = lambda images, **kwargs: (images, [False])
# 画像生成用のプロンプト
prompt = "1girl, black hair, school uniform, 8k"
# 画像を表示するウィンドウの作成
cv2.namedWindow("Active Window Capture", cv2.WINDOW_NORMAL)
while True:
# アクティブなウィンドウを取得
active_window = gw.getActiveWindow()
if active_window:
# アクティブなウィンドウの位置とサイズを取得
x, y, width, height = active_window.left, active_window.top, active_window.width, active_window.height
# 指定された領域のスクリーンショットを取得
screenshot = pyautogui.screenshot(region=(x, y, width, height))
img_np = np.array(screenshot)
img = cv2.cvtColor(img_np, cv2.COLOR_BGR2RGB)
# 画像生成器の初期化(torch.float32を使用)
generator = torch.Generator("cpu").manual_seed(2500)
# diffusersを使用して画像生成(torch.float32を使用)
img = pipe(
prompt=prompt,
image=img,
num_inference_steps=8,
guidance_scale=1,
generator=generator
).images[0]
# PILイメージをnumpy配列に変換し、OpenCV形式に変更
img = np.array(img)
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
# キャプチャした画像をウィンドウに表示
cv2.imshow("Active Window Capture", img)
# 'a'キーでループを終了
if cv2.waitKey(1) & 0xFF == ord('a'):
break
# ウィンドウを閉じる
cv2.destroyAllWindows()因みに遅すぎて配信では使えそうに無かったです。
この記事が気に入ったらサポートをしてみませんか?