機械学習は結局データ次第 - pix2codeを試してみた

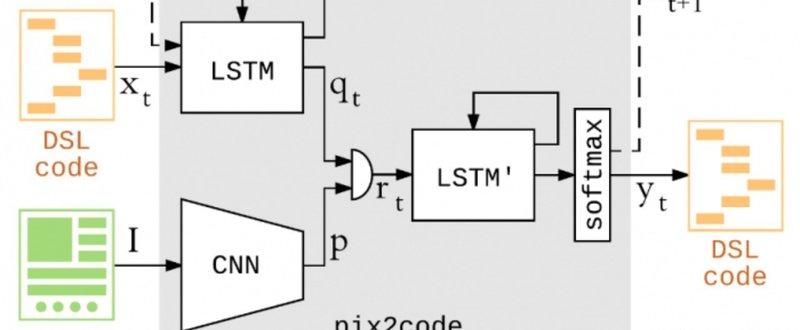
先週、pix2codeというプロジェクトがオープンソースになり話題になった。pix2codeは深層学習を用いてUIのスクリーンショットからHTMLやiOSのコードを自動生成し、開発者の時間を節約することが目的だ。コペンハーゲンに本拠を置くスタートアップUIzard Technologiesが開発している。
https://news.developer.nvidia.com/ai-turns-ui-designs-into-code/
僕はcssやhtmlを書くのがすごく嫌いだ。デザインを不条理な仕様に振り回されつつ手作業でコードしていくのが苦痛なのだ。なので、この手の自動生成系の話はいつも飛びつくのだが、心躍り、試し、そして落胆するのを繰り返してきた。人類には早すぎたのか。
さて、今回のpix2codeはどうだろう。さっそくgithubからcloneして動かしてみる。深層学習なので学習済モデルが用意されていると時間が節約できるのだが、無いようなので自分でモデルを作る。会社のGPUマシンを3時間しばいて学習が終わった。
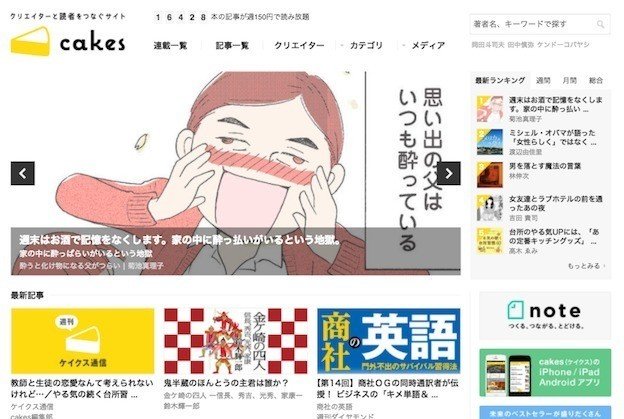
サンプルとしてcakesのトップのスクショを用意して、食わせてみたところ…
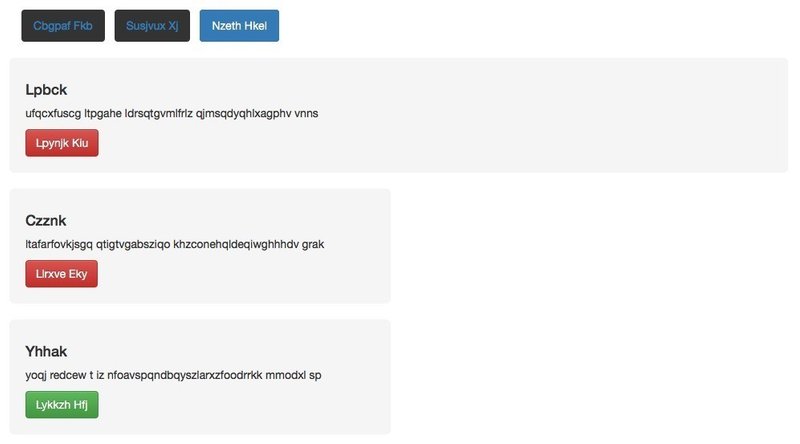
げっ、カスってもいない
それもそのはずで、学習に使ったデータセットを見ると、ごく単純化された同じテイストのデザインと、対になるbootstrapベースのコードを自動生成(水増し)して用意しただけであった。これだとこのテイストの出力しか得ることができないわけだ。

↑こういうテイストの教師データが3000枚でした
所感
pix2codeがやっているように、CNNとLSTMの組み合わせでいかにも実現できそうな題材ではあるのだけど、良質な教師データを集めるのがめちゃくちゃ大変だと思われる。特に、web(html/css)は自由度が非常に高く、同じ見た目を実現するための方法がいくつもあり毎年あたらしいコーディングスタイルが提供されている(ex: BEM, OOCSS)くらいなので、何も考えずに教師データをつくると色々な流儀が混じったぐちゃぐちゃなアウトプットが出てきて来ちゃいそうな肌感がある。
少なくとも、自然言語処理と同様に、W3Cの推奨にlintしたり、タグの大文字小文字を統一したり、定義の重複を排除したり...といったcssやhtmlの前処理が必要そうだ(すでにめんどくさい)。
そもそもだが、コンポーネントや画面設計を厳密に決めたUI設計のマスタデータがあって、そこから自動的にHTMLが生成される作りの方があるべき姿だと思う(実際sketchにそういうプラグインがいくつかある)
とはいえ、あまり更新される予定のない簡単なペライチを作りたいときは、とりまで画像からhtml/cssを吐いてくれると助かるケースは結構ありそうなので、深層学習アプローチは今後も要チェックだと思う。
こんぴゅです! 外苑前から皆様に役立つテックな話題をお届けしております。もし100円でもサポいただければ励みになります。記事もグレードアップします。何卒よろしくお願いいたします