
作曲AIコンペ弁財天でパーカー貰った

弁財天とは
弁財天とは↓です。
AIミュージックバトル!『弁財天』は「伴奏」から「アドリブメロディ」をAIで生成し「どれだけイケてるメロディか」を競うAI自動作曲コンテストです。
2023年夏秋に第2回を開催するらしいのでぜひ興味がある方は Twiter のフォローを!
Twitterアカウント → MusicxAnalytics
参加した目的
普段はよくkaggleに参加していてシビアな環境に身を置いているんですが、
弁財天は楽しく参加できそうだったのに加えて音楽も楽しめると思って参加を決めました。
また最近はChatGPTやStableDiffusionなど生成系のAIも流行っており、その辺りの技術キャッチアップをするモチベーションにしたかったのもあります。
あとはStarterKitを解説する勉強会も開いており、自分でも作曲AI作れそうだな!という実感を持てたのも大きかったです。(運営の方、勉強会の開催ありがとうございました!!)
あとは最近Jazzn周りの音楽理論を勉強していたので、そういうのも使えるかなっと。
実際には全く使うことはなかったですが。
本当は裏コードに変換してあれやこれやとやりたかったけどそこまで知識が体系化できていなかったです…
Jazzの勉強はこの辺りを
今回取ったアプローチ
いくつか選択肢があったと思います。
StarterKitを改造して自分好みの作曲モデルを作る
Magentaなどの学習済みモデルを活用する
ゴリゴリのルールベースで頑張る
自分としては生成する仕組みを深く理解したかったので1のStarterKitを改造していくことにしました。
結果的にコンペで設定されている様々な制約を守りながら、自分が好きな作曲AIを作れることになったのでいい選択だったかと思ってます。
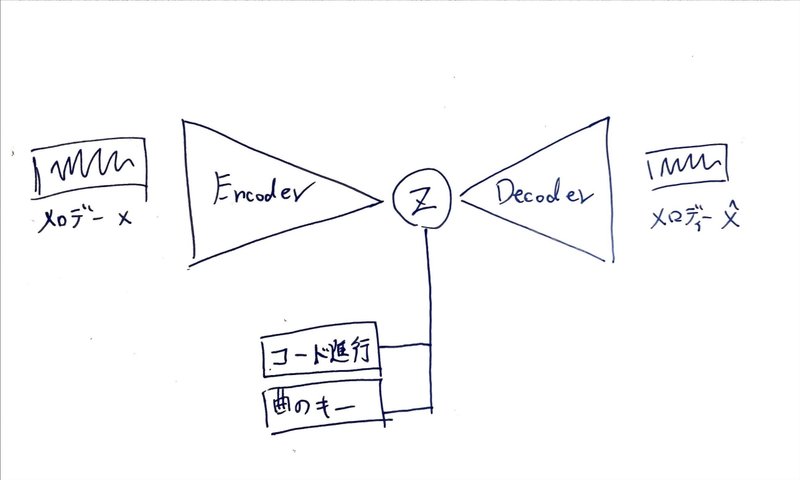
作曲モデルの概要
詳細はGithubに
コンペの制約上、コード進行と曲のキー(C major, A minor)からメロディを生成する必要がありました。
上記のような制約はConditionとして与えるのが良いだろうと考えたのでCVAE(Conditional Variational Auto Encoder)を採用しました。
VAEの詳細については長くなるのでここでは割愛します。
図にすると↓
やりたかったこと
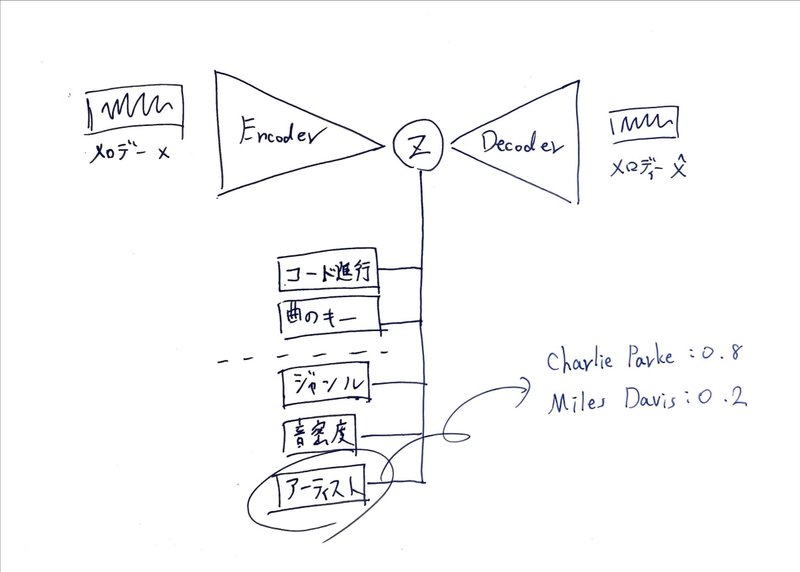
ここからは最もやりたかったができなかったことなのですが、
Conditionにさまざまな制約を与えたかったです。
具体的には
アーティスト
ジャンル
1小説内における音の密度
これができるとコンペ当日にお題を聞いてから、「ジャズっぽく」「アーティストAとアーティストBを混ぜた感じで」「ゆっくりのテンポだから長めの音で休符多めで」とかやりたかった訳です。
以下はイメージ図
最終的には上記を実現するためのデータを集める時間がないと判断したため断念しました。
根本的な欠陥
色々とやりたいこともあったのですが、そもそも解決しないといけなかったことがあります
1. 楽譜通りに学習できていない
1小節を16分割してメロディを作ってるのでそれよりも細かい音を表現でない
少し論文を読んだところMusicTransformerなどはmidi入力を学習データの前提にしているっぽく、音符の種類、ベロシティ、前回の音からの経過時間、などを特徴量にしてる。(たぶん)
MusicTransformerに比べると今回実装したCVAEの特徴量は荒い粒度で学習しているため、三連符などを表現することができない。
2. 他のパートを完全に無視している
与えてる条件がコード進行のみなので他のパートのことをする術がない。
ここでドラムの決めがあるからメロディを合わせよう、伴奏が盛り上がっているからメロディは控えめにしよう、など学習データとなったアーティストが表現していてもそれをモデルが学習できていない。
ここはやろうと思ったが、MusicXMLの仕様が難解すぎてやるならmidiデータの学習データを探して諸々実装し直さないといけなくなったため時間の関係で諦めた。
Elith賞でパーカー貰った
残念ながら1回戦で負けてしまった(凸凹にされた)のですが、スポンサー賞であるElith賞で良質なパーカーを貰いました。

こちらが株式会社Elithさんのサイト
おわりに
参加のモチベーションに「機械学習を使ってどうやって作曲させるのか」というのを知りたいと思っていたので目的を達することできた気持ちになってるので満足です