
tableau戦記~俺は重複データを徹底的に無くしたい~

Tableau Data Saber に挑戦中の@N_Ryo1105 です。
この投稿を見てくださっている方は、Tableauに関して調べている方、分析活動に興味のある方が多いのではないかと思います。
私が現在挑戦しているTableau Data Saberでは、Tableau社が提供するTableauを通じ、優れたデータのビジュアル化やデータの扱い方に関するtips、データを通じた企業・組織活動の変革を促すための姿勢面でのレクチャーを多数提供していますので、興味のある方はぜひData Saberにトライしてみてください。
さて、今回は私が個人的に苦しめられ続けてきたtableauでの「重複データの扱い」について取り上げたいと思います。
重複データ。それは、データ作業に潜む悪玉細菌。
ちょっと書きすぎな気もしておりますが、これまでこいつに苦しめられたことやこいつの存在を疑う心労を考えれば生ぬるい 一回でも見つかると本当に嫌なもの という意味では、共感いただけるのではと思っています。

ローデータはExcelだから手動で消しちゃえ!という方もいらっしゃるとは思いますが、DB接続はそうも行かないですし、Excelでも10万行越えた辺りから1行消すだけでも大分重たい処理になってしまうため、円滑にTableauで処理をしたい所。
何より重要なのは、重複データは「1度出ると2度出る可能性があり、2度・2種あれば3度・3種の重複があり得る」ということ。
データを扱う者たちにとって最も恐ろしい「集計や分析結果ではなく、データそのものを疑う必要がある」という事態が発生します。安心安全なデータを土台に成り立つ活動が全て水泡に帰し、データ利活用以前に、データそのものを疑うようになってしまい、活動を停滞させることになりかねません。
処理方法を理解し、この不安をしっかり潰していきましょう。
Tableauでデータの重複を消す3つのパターン
データ接続環境やローデータ自体の環境にも寄りますが、Tableauでデータ重複の影響を消すための方法は大きく3つあります。
●Tableau Desktop/Web編集で重複影響排除
・1:LOD関数を使用する
●Tableau Prepで重複影響排除
・1:「集計」を使う
・2:PARTITION関数とROW NUMBER関数を掛け合わせる
1:LOD関数を使用する
Tableau Desktop/Web編集など、データセットとして読み込むものが確定した状態で実行可能な方法としては最もメジャーな方法になります。
まずは、当該データを読み込んでみます。

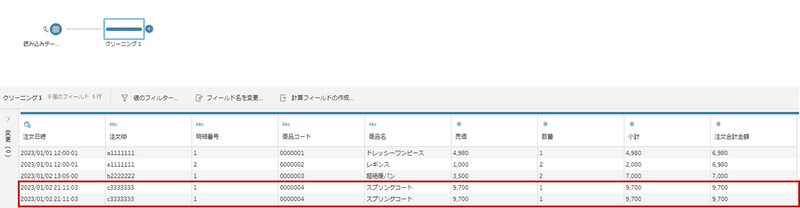
御覧のように、データは重複した状態です。

Tableauで各ディメンションを行にセットし、「カウント」を見ても「2」。
本来、注文id:c3333333は一つで、売れたスプリングコートの数量も「1」のはずですが、2行存在していることで数量が2になってしまっています。
今回は、「同日付」「同注文id」「同商品」で重複していることが分かっていること、注文idは必ず一意である(使い回されない)と仮定し、注文idと商品ごとで正しくデータが取れれば問題ないとして、以下のような式を書きましょう。

上記のように記載することで、集計の粒度(Lebel Of Detail)が指定の粒度に調整され、重複の影響を排除することが出来ます。
※fixedは指定ディメンションでの調整。その他の関数はTableauの公式ヘルプを参照してください。
今回はMAXを記載しましたが、AVG、MINなど一意の数字を取得出来る集計関数であればfixed内の集計は何でも構いません。
では、こちらで結果を見てみましょう。

無事、重複データの集計数字を「1」にすることができました。
データが重複した状態でも、重複データに対して一意のデータを取る方法が分かっていれば、重複影響を無視して集計することが出来ますね。
2:Tableau Prepで「集計」を使う
次からの2つは、Tableau Prepでローデータをいじるパターンになります。
「集計」を使う作業はTableau Desktopユーザー限定になりますが、幅広いデータに応用出来ますのでやってみましょう。
まずは、Tableau Prepでデータを読み込んでみます。
データを確認したら、⊕ボタンからメニューを開き、「Σ 集計」をクリックしましょう。
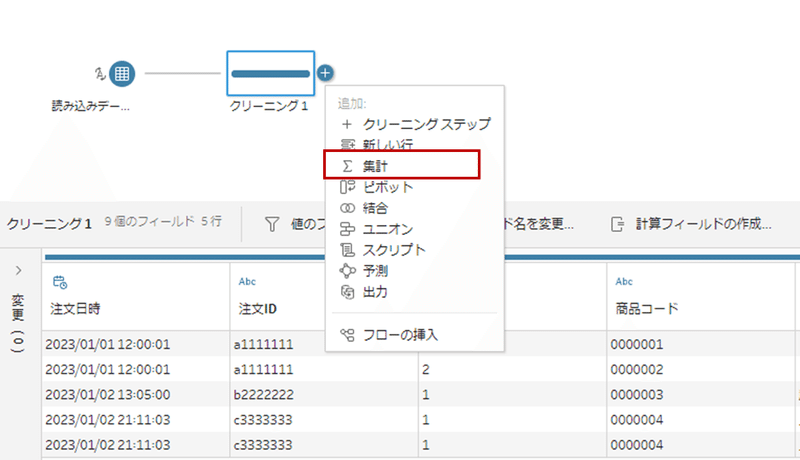
「集計」を開くと、Excelで言う所のピボットテーブルが出現します。
「グループ化されたフィールド」は値をまとめる軸になりますので、今回は値以外の項目を全て入れました。
「集計フィールド」は軸に対する値になりますので、重複影響を排除するため、各行に対する最大値を取得しています。

では、結果を見て見ましょう。

無事、データが一行になりました。ごく簡単な処理ですが、これだけで重複が削除出来るのであれば積極的に利用したいですね。
3:PARTITION関数とROW NUMBER関数を掛け合わせる
こちらもTableau Prep限定の手法ですが、アプローチとしては応用編です。
Prepの比較的新しいバージョンから追加された機能なので知らない方もいらっしゃると思いますが、知っていると非常に便利な手法なのでぜひマスターしましょう。
データをセットする所までは同じなので、まずはこの手法が何が出来るのかを見て見ましょう。

各注文データの行に対し、行番号を振ることができました。
このように指定粒度で行番号を振ることが出来れば、後は行番号が「1」のものにフィルタをすれば重複排除できますね。
この行番号の振り方は以下のような式で作成しています。
//記述式
{ PARTITION [注文ID],[商品コード]: { ORDERBY [注文日時]:ROW_NUMBER() } }
//記述の意味
//注文日時でデータを並び替えて、行番号を早い方から1って振ってね。(全く同じならどっちかを2にしてね)
//その処理を、注文ID - 商品コードごとに実行してねこの式はPrep専用の関数を3つ組み合わせて形成されています。
1つ目は { ORDERBY }という関数で、これは指定したカラムに対して昇順・降順で並び順を決めるという関数です。
2つ目は ROW_NUMBER()です。これは、{ ORDERBY: }とセットで使う関数で、{ ORDERBY :[ (カラム) ] }で指定したカラムの並び順指示に沿って、行番号を振れ という指示の関数になります。
3つ目は { PARTITION }です。これも{ ORDERBY }とセットで使う専用関数で、{ ORDERBY }とROW_NUMBERで指示した行番号を振る単位を指示しています。これにより、重複の発生粒度である「注文ID」「商品コード」ごとに行番号が振る制御ができています。
重複が発生していない行は必ず1行しかないのでROW_NUMBERが返す値は1、重複が発生すると重複したどちらかの行に「2」が付与されるので、ROW_NUMBERが返す値を「1」だけに絞れば、集計せずにデータが絞れるという寸法です。
SQLを普段から活用している方からすれば典型的なウィンドウ関数かと思いますが、ETLツールと思われがちなTableau Prepでもここまで出来るので、必要なタイミングがあればぜひ使ってみてください。
終わりに
いかがでしたでしょうか?
気が付けば3,000字を超えておりボリューミーになってしまいましたが、重複データを綺麗にクリーニングして、素敵なデータ活用ライフを楽しみましょう。
それでは次の記事でお会いしましょう!ありがとうございました!
この記事が気に入ったらサポートをしてみませんか?