PythonでExcelファイルの結合

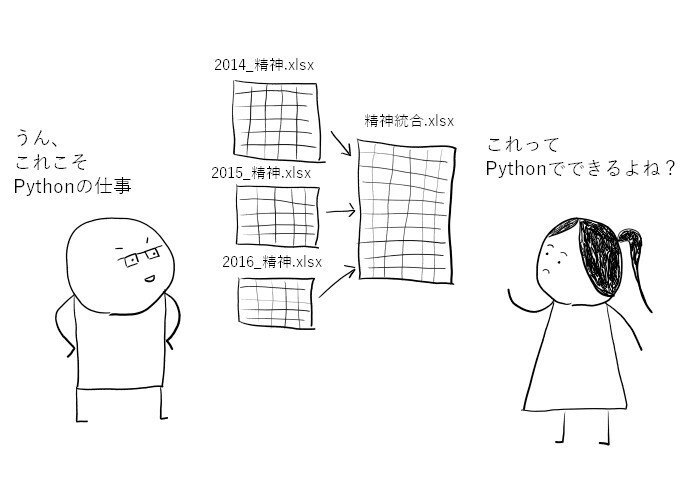
大量のExcelファイルをとりあえず縦結合したい、ということがあります。
これも手作業だと大変ですよね。
今回の仕様は、以下のとおりです。
形式の同じ大量のExcelファイルが1つのフォルダに入っている。
これらのExcelファイルの"外来シート"を1つのシートに縦につなげる
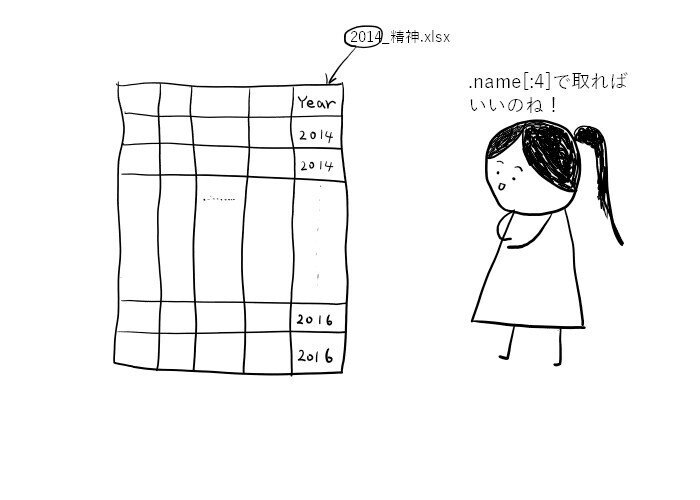
どのファイル由来かがわかるようにファイル名の先頭4文字(2014_精神.xlsxの場合"2014")を取り出し新しい列として加える。
こちらがプログラムの全容です。
import pandas as pd
from pathlib import Path
# Excelファイルが保存されているディレクトリ
excel_files_directory = r'C:XXXXXXXXXXXXXXX'
# 同一名のシートを縦に結合するためのデータフレームを初期化
combined_df = pd.DataFrame()
# ディレクトリ内のExcelファイルを取得
for excel_file_path in Path(excel_files_directory).glob('*_精神.xlsx'):
# Excelファイルを読み込む
excel_df = pd.read_excel(excel_file_path, sheet_name='外来')
# ファイル由来の情報を持つ新しい列を追加
excel_df['Year'] = excel_file_path.name[:4]
# データフレームを縦に結合
combined_df = pd.concat([combined_df, excel_df], axis=0, ignore_index=True)
# 結合したデータフレームを新しいExcelファイルに保存
combined_excel_path = r'C:\XXXXXXXXXX\精神統合.xlsx'
combined_df.to_excel(combined_excel_path, index=False)
print(f'同一名のシートを縦に結合し、新しいExcelファイルに保存しました: {combined_excel_path}')前回紹介したpathlibを駆使しています。
フォルダ内にある特定のexcelファイルを取り出すのは
Path(excel_files_directory).glob('*_精神.xlsx')だけで済みます。
osライブラリを使うより圧倒的に簡単です。
ファイル名"2014_精神.xlsx"から"2014"を取り出すのも、.nameを使えば一発ですね。
感覚的に1時間以上の手作業が発生しそうな仕事は、Pythonで楽できないかを考える価値があると思います。

この記事が気に入ったらサポートをしてみませんか?