
怪しいデータを見逃すな!


データの仕事をしていると、時々
「このデータ怪しいんじゃない?」
という場面に遭遇します。
あまりにも似たデータがあるような場合です。
例えば、Day3とDay4のデータは完全に一致しています。
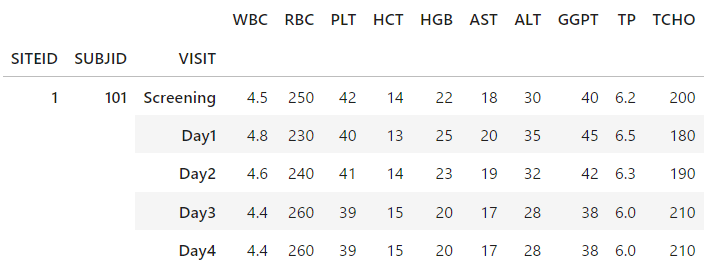
本当に一緒なのか、入力間違いなのか、あるいはわざとなのか・・・
こういうデータは検出して確認したいものです。
文字列の類似性をみる

文字列の一致性をみるには、ゲシュタルトパターンマッチングという方法を使います。面倒な数式は置いておいて、Pythonのライブラリを利用させてもらいましょう。
SequenceMatcherを使って文字列の類似性を見てみます。類似度は百分率で現されます。
import difflib
str1="今日は暑いですね。お体に気を付けてお過ごしください。"
str2="今日は暑いですね。お体に気を付けてお過ごしください。"
matcher = difflib.SequenceMatcher(None, str1, str2)
similarity_ratio = matcher.ratio()
print(f"{similarity_ratio:.2%}")当然ですが、同じ文字列の場合は、100%となります。
str1="今日は暑いですね。お体に気を付けてお過ごしください。"
str2="今日はお暑いですね。お体に気を付けてお過ごしください。"この場合は、98.11%となりました。
str1="今日は暑いですね。お体に気を付けてお過ごしください。"
str2="お体に気を付けてお過ごしください。今日は暑いですね。"文を入れ替えると65.38%と一気に下がりますね。順番が大事なようです。
いざ実践!
方法としては、行データをすべて結合させて一文として、すべての行を総当たりさせて類似性を見ていきます。
import pandas as pd
lb=pd.read_excel("lb.xlsx",sheet_name="LBdata")
lb.set_index(["SITEID","SUBJID", "VISIT"],inplace=True)
# DataFrameの行数
num_rows = len(lb)
# 行の組み合わせを比較
for i in range(num_rows):
for j in range(i + 1, num_rows):
# 行ごとに文字列の類似性を計算
row_i = lb.iloc[i, 0:].astype(str).str.cat(sep=' ')
row_j = lb.iloc[j, 0:].astype(str).str.cat(sep=' ')
print(lb.index[i],row_i)
print(lb.index[j],row_j)lb.iloc[i, 0:].astype(str).str.cat(sep=' ')のように、スペース区切りですべての変数を結合させます。
こんな感じで、1行目とそれ以外の行、2行目とそれ以外の行・・・というように、総当たりできるように準備します。

そして
matcher = difflib.SequenceMatcher(None, row_i, row_j)
で文字列の比較をして、類似性の割合をratio()で取得します。
このプログラムでは類似性が90%以上のものを出力しています。
import pandas as pd
import difflib
def find_similar_rows(df):
# DataFrameの行数
num_rows = len(df)
# 行の組み合わせを比較
for i in range(num_rows):
for j in range(i + 1, num_rows):
# 行ごとに文字列の類似性を計算
row_i = df.iloc[i, 0:].astype(str).str.cat(sep=' ')
row_j = df.iloc[j, 0:].astype(str).str.cat(sep=' ')
matcher = difflib.SequenceMatcher(None, row_i, row_j)
similarity_ratio = matcher.ratio()
# 類似性が一定の閾値以上の場合は表示
if similarity_ratio > 0.9: # 適切な閾値を選択してください
print(f"{df.index[i]} と {df.index[j]} は類似しています。類似性: {similarity_ratio:.2%}")
# 類似性を検出して表示
find_similar_rows(lb)結果はこのようになりました。(1, 101, 'Day3') と (1, 101, 'Day4')は完全一致していますね。このデータは本当に正しいのかどうか確認する必要があります。
(4, 104, 'Day2') と (4, 104, 'Day4') や(5, 105, 'Day1') と (5, 105, 'Day4')みたいな例も少し怪しいですね。Dayのみが違っていて、偶然にここまで数値が似通ることがあるのかどうか、常識に照らして考える必要がありそうです。
(1, 101, 'Day3') と (1, 101, 'Day4') は類似しています。類似性: 100.00%
(1, 101, 'Day3') と (4, 104, 'Day3') は類似しています。類似性: 91.84%
(1, 101, 'Day4') と (4, 104, 'Day3') は類似しています。類似性: 91.84%
(2, 102, 'Day3') と (5, 105, 'Day1') は類似しています。類似性: 91.84%
(4, 104, 'Day2') と (4, 104, 'Day2') は類似しています。類似性: 95.92%
(5, 105, 'Day1') と (5, 105, 'Day1') は類似しています。類似性: 95.92%

まとめ
完全一致の場合は、レコード重複がないかというチェックで検出ができます。しかし、index番号が違っていたり、完全一致していない場合などは、レコード重複だけで怪しいデータを見つけることはできません。
こういった場合に、文字列の類似性のチェックは有効です。
この記事が気に入ったらサポートをしてみませんか?