
売れ筋商品選定AIエージェントを作ってみた【LangGraph・ChatGPT】

こんにちは、データサイエンティストのせきとばです。
最近、生成AIエージェントにハマってます。
特に、LangChainが提供するLangGraphというAIエージェント実装に特化したライブラリに注目しています。
この記事では、LangGraphを活用し、Amazonマーケットプレイスで売れ筋の商品を特定するAIエージェントの開発過程を紹介します。
AIエージェントとは?
AIエージェントは、特定のタスクを自動で行うプログラムです。ユーザーからの入力に基づいて情報を収集・分析し、最適な解決策を提案します。この技術は、商品選定、顧客サービス、データ分析など、多岐にわたる分野で活用されています。
LangGraphとは?
LangGraphは、LangChainによって提供される、AIエージェントの構築を簡単にするためのライブラリです。複雑なAIモデルと連携しやすい設計が特徴で、開発者がより効率的にAIエージェントを開発できるようになります。
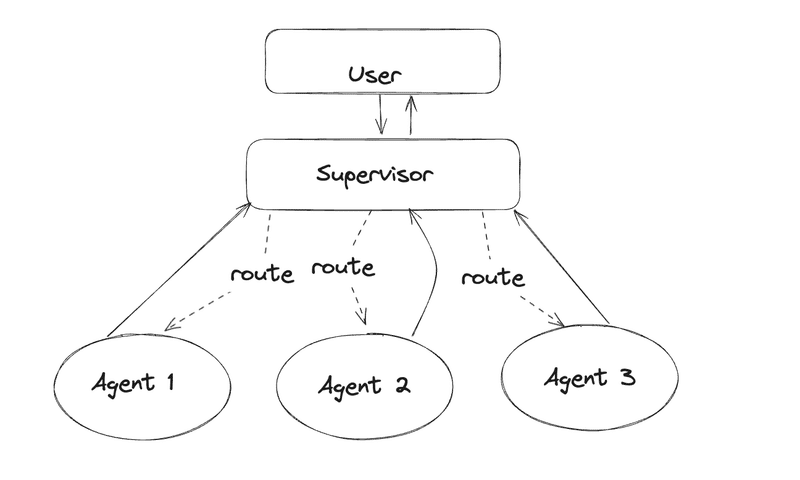
売れ筋商品特定AIの設計
このエージェントチームの目的は、Amazonのマーケットプレイスで販売するべき売れ筋の商品を特定することです。Amazonキーワード検索時のURLを入力として、WEBから商品ランキングを収集。そのデータを基に市場分析と商品販売戦略を練り、どの商品を販売するかを決定します。
専門家チームの役割
上司: チームリーダーとして全体の指揮を執り、各専門家への指示を出します。
情報収集担当: 検索ワードから商品一覧を収集します。
市場分析担当: 商品一覧から市場のトレンドや傾向を分析します。
販売戦略担当: 市場分析結果を基に、どの商品をどのように販売していくかを検討します。
早速ですが、今回はカービィのぬいぐるみについて商品選定してもらいましょう。
実装コード
以下のPythonコードは、LangGraphを使用して商品選定AIエージェントを実装する一例です。
LangGraphそのものの実装方法は公式ドキュメントが非常にわかりやすいのでご参照ください。
必要なライブラリをインポートします。OPENAI _API _KEYなどの環境変数は事前に.envファイルで設定したものを読み込みます。
# LangGraphと連携する各種ライブラリのインポート
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain.tools import tool
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.runnables import Runnable
import operator
from typing import Annotated, Sequence, TypedDict , List
from langchain_community.document_loaders import WebBaseLoader
from langgraph.graph import StateGraph, END
from dotenv import load_dotenv
load_dotenv() # .env ファイルから環境変数を読み込む使用する生成AIモデルとAmazonのURLを指定します。
OPENAI_MODEL = "gpt-4-turbo-preview"
user_input = "https://www.amazon.co.jp/s?k=%販売したい商品キーワード"上司エージェントを作ります。
def create_agent(llm: ChatOpenAI, tools: list, system_prompt: str):
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder(variable_name="messages"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
agent = create_openai_tools_agent(llm, tools, prompt)
return AgentExecutor(agent=agent, tools=tools)
def create_supervisor(llm: ChatOpenAI, agents: list[str]):
system_prompt = (
"以下のエージェントを監督しています: {agents}。"
"ユーザーの要求に応じて、各エージェントにタスクを割り当てる責任があります。"
"各エージェントは役割に応じてタスクを実行し、結果とステータスで応答します。"
"情報を確認し、次にタスクを割り当てるエージェントの名前を回答してください。"
"ユーザーの要求を満たしたと判断した場合は 'FINISH' と回答してください。"
)
options = ["FINISH"] + agents
function_def = {
"name": "supervisor",
"description": "次のエージェントを選択します。",
"parameters": {
"type": "object",
"properties": {
"next": {
"anyOf": [
{"enum": options},
],
}
},
"required": ["next"],
},
}
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder(variable_name="messages"),
(
"system",
"""
上記の会話を踏まえて、次のオプションのうちどのエージェントが次にアクトまたは終了するかを選択してください: {options}。"""
),
]
).partial(options=str(options), agents=", ".join(agents))
return (
prompt
| llm.bind_functions(functions=[function_def], function_call="supervisor")
| JsonOutputFunctionsParser()
)
RESEARCHER = "Reseacher"
ANALYZER = "Analyzer"
EXPERT = "Expert"
SUPERVISOR = "Supervisor"
agents = [RESEARCHER , ANALYZER, EXPERT]
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
next: str
情報収集担当のエージェントを実装します。
他のエージェントも同じ要領で作成します。
@tool("Scrape_the_web")
def researcher(urls: List[str]) -> str:
"""ウェブをスクレイピングし、ページの内容を返すリサーチャー"""
loader = WebBaseLoader(urls)
docs = loader.load()
print(docs)
return "\n\n".join(
[
f'<Document name="{doc.metadata.get("title", "")}">\n{doc.page_content}\n</Document>'
for doc in docs
]
)
def scraper_agent() -> Runnable:
prompt = (
"あなたはAmazonのスクレイパーです。"
)
return create_agent(llm, [researcher], prompt)
def scraper_node(state: AgentState) -> dict:
result = scraper_agent().invoke(state)
return {"messages": [HumanMessage(content=result["output"], name=RESEARCHER)]}
# 残りのエージェントも同様に定義
@tool("Market_Analyser")
def analyze(content: str) -> str:
# ...省略...
@tool("DropShipping_expert")
def expert(content: str) -> str:
# ...省略...どのように協業させるかのフローを定義します。
ここがLangGraphの肝ですね。一度エージェントを定義してしまえば、あとは柔軟に実行順序を調整することができます。
if __name__ == "__main__":
llm = ChatOpenAI(model=OPENAI_MODEL)
print("ワークフローを実行中...")
workflow = StateGraph(AgentState)
workflow.add_node(RESEARCHER, scraper_node)
workflow.add_node(ANALYZER, Analyzer_node)
workflow.add_node(EXPERT, Expert_node)
workflow.add_node(SUPERVISOR, supervisor_node)
workflow.add_edge(RESEARCHER, ANALYZER)
workflow.add_edge(ANALYZER, EXPERT)
workflow.add_edge(EXPERT, SUPERVISOR)
workflow.add_conditional_edges(
SUPERVISOR,
lambda x: x["next"],
{
RESEARCHER: RESEARCHER,
ANALYZER: ANALYZER,
EXPERT: EXPERT,
"FINISH": END
}
)
workflow.set_entry_point(SUPERVISOR)
graph = workflow.compile()
for s in graph.stream({"messages": [HumanMessage(content=user_input)]}):
if "__end__" not in s:
print(s)
print("----")実行結果
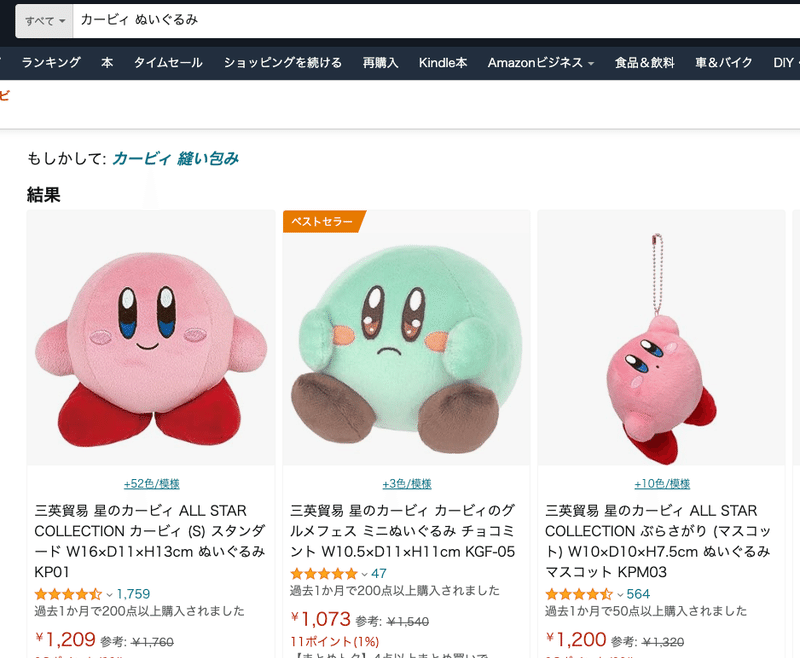
今回は「カービィのぬいぐるみ」で検索してみました。
各担当が協業して商品選定を行った結果、以下のカービィの商品が選ばれました。た、確かに売れそうですね!

この商品に辿り着くまでに、エージェント間で以下のやり取りがありました。(Streamlitで実装したスクリーンショットです)
情報収集担当

市場分析担当

販売戦略担当

上司

今回は上司の一発OKとなりましたが、タスクの進行状況によっては柔軟に再度指示を行ったりなど、LangGraphは柔軟に組むことができます。
このプロジェクトを通じて、LangGraphの柔軟性とAIエージェントの開発におけるその強力な機能を実装できました。今回は基本的なフローを実装しましたが、入力情報やプロンプト、協業フローをさらに改善することで、より深い分析が可能になりそうです。
この記事が気に入ったらサポートをしてみませんか?