
AI革命の源流:Transformerモデルの誕生秘話

2024年3月18日、NVIDIAは今年の開発者会議を開催し、テーマはAIでした。出展者は200社以上、講演は20回以上ありました。黄仁勋が自ら登壇した講演も多くはビジネスの相互賞賛でしたが、中には内容の濃い議論が行われたものもありました。それは黄仁勋と7人の対談です。
NVIDIA開発者会議
この7人とは、Transformerモデルの論文の8人の著者のうちの7人です。このモデルは当時、論文の形で発表され、「Attention is All You Need」というタイトルでした。これは「集中力だけが必要」という意味ではなく、「自己注意機構だけが必要」と訳されるべきです。
もし今日のすべての人工知能に最も近い共通の祖先がいるとすれば、それはこの論文です。黄仁勋がこの論文の全8人の著者のうち7人を招いて対談を行ったのは、非常に目を引くものでした。
以前、Googleの衰退について言及した際にも触れましたが、Transformerモデルの8人の著者は今や全員がGoogleを去っています。Googleがこれほど重要なアイデアを生み出したにも関わらず、人材を留めることができなかったのです。これら8人の著者はそれぞれどこへ行ったのでしょうか?
Transformerの誕生
13年前の2011年10月29日、AppleはiPhone 4Sで驚くべき効果のSiriを発表しました。当時、多くの人がSNSで自分とSiriのチャット記録を披露していました。当時、Appleのカスタマーサービス部門が何百人ものインド人を雇ってSiriを演じ、ユーザーの質問に答えているという画像が流布していました。
Googleは当時、Siriの機能に衝撃を受けました。彼らはSiriが検索エンジンのトラフィックを奪うことを心配しました。というのも、そのトラフィックはGoogleの主要な広告収入源だったからです。そこで2012年、Googleはユーザーと直接対話できるモジュールを開発するためのチームを組織し、生成された回答を通じてユーザーが見たいページにジャンプするようにしました。
もちろん、後になってみれば、Google検索のトラフィックはSiriに奪われることはなく、その特定の研究チームも実用的な製品を開発することはありませんでしたが、今日のすべての大規模言語モデルの共通の祖先を生み出しました。
Googleの挑戦と失敗
Googleは最初、再帰的ニューラルネットワーク(RNN)を使用してこの対話ツールを構築しました。その年、60歳を超える老辛顿が2人の弟子、イリヤとアレックスを率いてスタンフォード大学の画像認識コンテストImageNetに参加しました。彼らが開発したRNNアルゴリズムは優勝し、エラー率は前年比15%減少しました。それまでのこのコンテストでは、毎年の優勝者は前年比1%-2%の進歩しか見せていませんでした。
2年間の努力の末、GoogleはRNNアルゴリズムが短い文しか処理できず、数文前に言及された内容を処理すると非常に悪い結果になることを発見しました。もちろん、この時点でGoogleはすでに、SiriがGoogle検索エンジンとトラフィックを奪い合うことはないと確信していました。
2014年になると、チームの一員であるヤコブ・ウスコレイト(Jokob Uszkoreit)、つまり論文の第4著者、以後「老四」と呼びますが、他の著者も同様に「老何何」と呼びます。老四は「自己注意機構」を提案しました。これは、各単語とその文中のすべての要素との関連度を計算するモデルです。当時、彼のこの革新的なアイデアは誰からも評価されず、彼の父親でさえ反対していました。もちろん、彼の父親は普通の老人ではなく、ドイツの有名な計算言語学者でした。
後に、老四はGoogleの3人の同僚を説得して、少しのリソースを獲得し、老八(Illia Polosukhin、イリヤ・ポロスキン、OpenAIのイリヤではありません)と一緒に自己注意機構を使って小さなモデルを訓練しました。
老四は2010年に修士課程に在籍していた時にGoogleでインターンをしており、当時は翻訳チームにいました。しかし、家族経営の企業を継ぐ予定だったため、博士課程を半ばで中退しました。結局、家族経営の企業を継ぐことはなく、彼は再びGoogleに戻りました。彼がGoogleに戻った時、ちょうどAppleのSiriが発表され、Googleは防衛線を構築する必要がありました。
老八と老四はGoogleに入社した時期が近く、同じチームにいました。二人は昼食をとりながら、最近の開発プロセスがうまくいかないことについて話し合っていました。老四は自己注意機構を老八に熱心に勧め、老八がそれを理解した後、最終的には老大(Ashish Vaswani、アシッシュ・ヴァスワニ)を説得しました。最初はこの3人で自己注意機構に取り組みました。
3人とも80年代生まれで、アニメの影響を受けていました。彼らは自己注意機構のモデルに「Transformer」という響きの良い名前を付けることにしました。この名前には「モデルが受け取った情報を変える」という意味もありますし、「トランスフォーマー」という有名なアニメの意味もあります。
半年後、インドの小哥は彼の師妹をチームに引き入れました。それが老三(Niki Parmar)です。
老五はイギリス出身で、2009年にバーミンガム大学で修士号を取得しましたが、卒業後半年間は仕事が見つからず、生活保護金を頼りに生活していました。2012年にYouTubeチームに加わり、その後Google研究院に転入しました。老五が初めてTransformerという名前を聞いたのは、批判と非難の中でした。当時、Transformerモデルがベイズアルゴリズムなどに比べてどれほど劣っているかという話がありました。しかし、彼が自分で調べたところ、Transformerは悪くないと感じ、チームに加わりました。
老六(Aidan N. Gomez)は8人の著者の中で最も若いですが、彼はトロント大学の辛顿研究室出身で、神経ネットワークの祖師爷から直接伝授されたと言えます。彼は大学生の時からGoogleに様々な研究アイデアを提供していました。Google Brainの研究員である(Łukasz Kaiser)、つまり論文の老七は、老六のアイデアが非常に面白いと感じ、Googleでのインターンに招待しました。老六は喜んでGoogleでのインターンを始めましたが、実際には老七が当初募集していたのは博士課程の学生であり、彼はその時点で大学3年生でした。もちろん、老六はこのことを早くから知っていましたが、彼が重視したのは能力であり、学歴は二の次でした。
老二(Noam Shazeer、ノーム・シェイザー)は最後に加わった人物です。老二は8人の中で最も経験豊富で、2000年にGoogleがまだ200人しかいない時に入社しました。2017年、彼は廊下を歩いているときに、老七と老大が激しい議論をしているのを耳にしました。議論の内容は職務上の問題ではなく、自己注意機構についてでした。その横で老三が興味津々に見ていました。老二も興味を持って近づき、彼らの話が有望だと感じたため、老七は老二が副社長級の人物であることを気にせず、彼をチームに引き入れました。老二は地位が高いにも関わらず、その論文のコードのほとんどは彼が一人で整理し、打ち込んだものです。
彼らの目標は、2017年の神経情報処理システム会議(NeurIPS)で成果を発表することでした。そのため、8人は2017年2月から毎日14時間以上働き、2ヶ月以上連続で残業し、論文の締め切り5分前に内容とテストを提出しました。
この論文の最初の草稿では、老二の名前が最初にありました。一つには彼がGoogleでの地位が高いため、もう一つはほとんどのコードが彼の手によるものだったからです。
しかし、老二はこれに同意せず、時間的にも、アイデア的にも、彼が加わった時点が遅すぎると考えました。そこで、みんなで再度著者の順番を決め、今日の論文の順番が決まりました。私はこの論文のスクリーンショットを下に貼り付けましたので、興味があればご覧ください。各著者の名前の後に「*」が付いていることに気づくでしょう。これは、著者の順番が完全にランダムであり、どのような順序にも基づいていないことを意味しています。
Transformerモデルの原理
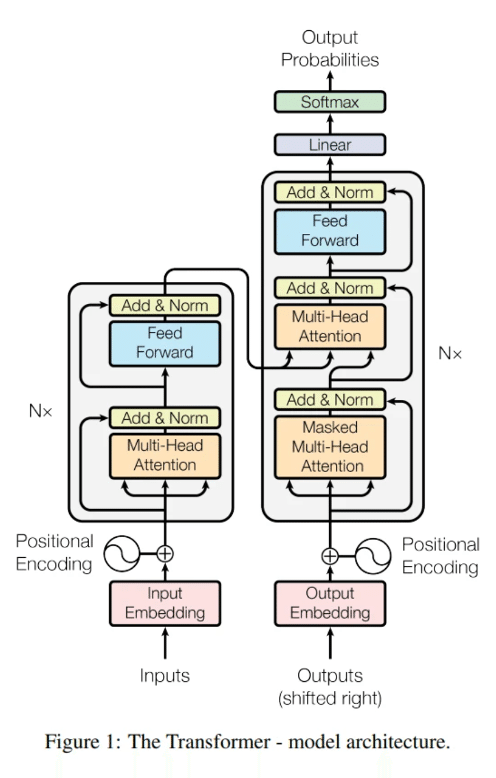
この論文には2つのバージョンのモデルが添付されています:後のNeurIPSチャレンジで、65Mの基本版はすでにすべての競合他社を超えており、213Mのアップグレード版はチャレンジの記録を破りました。
論文のタイトルも興味深いものでした。最初は老五が提案した「All You Need Is Love」を使う予定でした。老五はイギリス出身で、「All You Need Is Love」はイギリスのバンド、ビートルズの有名な曲です。しかし、後になってみんなは、こんなロマンチックな名前を挑戦に使うと誤解を招く可能性があると感じ、最終的に「Attention is All You Need」というタイトルに変更しました。
以上が、この創世論文が生まれた小さな物語です。
しかし、話はまだ終わっていません。老二(Noam Shazeer)はGoogleでの地位が比較的高く、Transformerの開発に深く関わり、その価値を理解していたため、2017年5月にGoogleの上層部にメールを送り、現在の検索エンジンのロジックを放棄し、Transformerモデルを使用して巨大なニューラルネットワークを訓練し、検索機能を再構築することを提案しました。
この提案は、当時のGoogleの高層部はもちろん、Transformerモデルチームの他のメンバーでさえも、信じられないと感じました。このような反応は当然のことで、Googleのすべての利益、すべてのハードウェアとソフトウェアは、従来のPageRankアルゴリズムに基づいて構築されており、これをTransformerに変更することは、Googleを再構築することを意味します。このような大規模なアップグレードは、スタートアップ企業にしかできないことであり、すでに巨大企業になってしまった企業には、変更の機会がありません。
著者たちの新たな道
そして、この論文が発表された翌日、OpenAIの首席科学者イリヤ(Ilya Sutskever)はその含金量をすぐに理解し、OpenAIが当時行っていたすべての試み、DOTAゲームのロボットやAIによる機械アームの制御などをすべて停止し、すべての研究力と計算力をGPT-2のモデル開発に集中させました。その後、GPT-3やGPT-4の話が続きます。
Googleの高層部は2023年にOpenAIの台頭についてコメントし、もし当時自社が生み出したTransformerモデルを重視していれば、2019年にはGPT-3.5を作り出していたかもしれないと考えています。
そして、この8人の著者が次々と退職したことは、Googleの衰退とも重なります。2019年、最も若い老六はCoheryを設立し、この会社は企業に大規模モデルのソリューションを提供しており、現在の評価額は22億ドルです。その後、2021年から2023年にかけて、他の7人の著者も次々と退職しました。
老大と老三(Ashish VaswaniとNiki Parmar)は、Essential AIを立ち上げました。
老二(Noam Shazeer)は、Character AIを立ち上げました。
老四(Jakob Uskhoreit)は、Inceptive AIを立ち上げました。
老五(Llion Jones)は、Sakana AIを立ち上げました。
老八(Illia Polosukhin)は、ブロックチェーン会社のNear Protocolを立ち上げました。
唯一、老七(Łukasz Kaiser)は自分で起業することなく、OpenAIに加わりました。この対談で彼は一時、Q*計画について言及し、OpenAIの広報マネージャーが慌てて舞台に駆け上がり、彼が話を続けるのを止めました。
彼らの会話では、Transformerモデルの次に来るマイルストーンとなるモデルは、少ないデータから学習できるモデルであり、このモデルがTransformerを置き換えることになるとも言及されました。このモデルがどのようなアルゴリズムを使用するかは、今後数年で見ることになるでしょう。
イノベーションの本質
Transformerモデルの誕生から、私たちは何を学ぶことができるでしょうか?
1 イノベーションは、開放性と包容性から生まれます。
これら8人のうち、ドイツ、イギリス、インド、ウクライナ出身の人がいます。彼らの中には、ばかり卒業したばかりの人もいれば、修士、博士、副社長もいます。彼らが所属する会社には厳格な規則がなく、すべての新しいアイデアは食堂や廊下での偶然の出会いから生まれました。
2 イノベーションは特定のエリートからではなく、土壌から生まれます。
私たちがこの8人から視線を移すと、当時のGoogle研究院やGoogle Brainのすべての研究員たちが、実はほぼ同じ才能と力を持っていたことに気づきます。どのアルゴリズムが今日のAIを成就させるか、誰にもわかりませんでした。もしかすると、別の平行世界では、別の8人が勝ち残っていたかもしれません。
一人の人生の長さは限られており、たとえば3つの選択肢を経験することしかできませんが、全ての選択肢は1億種類あり、その中で成功するのはたった100種類だけです。成功すると巨大な成功を収めることになります。どんなに天才的なエリートであっても、人生の3つの選択で1億種類の中の100種類の成功パターンを見つけ出すことができるでしょうか?それは本当に運が良いことです。
もし1000人のエリートしかいなければ、成功の確率を少し上げるだけです。しかし、エリートを引き付け、育成する土壤があれば、時間さえあれば、ここにいる何百万人ものエリートが、1億種類の可能性の中のすべての成功パターンを探り出してくれるでしょう。
この記事が気に入ったらサポートをしてみませんか?