
HAD:一要因分散分析について/書き残しといくつかの疑問

前回,HADを使った一要因分散分析について書いたのだが,書いておきたいと思ったことを少々残しているので,それを書いてしまって,そろそろ次の(それはそれでまた,結構やっかいな)テーマに進みたいと思う。
書き残したことは,
1:多重比較での,平均値差の標準誤差の算出について。
2:一要因分散分析での d効果量の算出について。
3:アンバランスデータでの効果量の値について。
平均値差の標準誤差
Rで多重比較をするときには,これまで単純に TukeyHSD 関数を使ってきた。この関数は,aov 関数をそのまま引数にしてしまえば多重比較をしてくれて,水準の組合せごとの平均値差とその信頼区間,修正p値を出してくれるので,簡単でありがたい。しかし,その計算がどのように行われているかはわからない。まあ,わからなくても結果が出れば論文に引用できるのでOKといえばOKなのだが。
多重比較の計算方法については,青木先生のサイトに計算式がのっている。
別のページには Ryan の方法も掲載されているが,異なるのは確率の修正方法の部分で,t値の計算式は同じである。ついでに,Rの pairwise.t.test 関数も,同じ式でt値を計算しているので,これで間違いないだろう。つまり,分散分析表に出力された誤差分散(誤差の平均平方)に,水準ごとのNの逆数の和を掛け算して,平方根をとったものが,水準間の平均値差の標準誤差であり,この値で平均値差を割るとt値が算出される。自由度は分散分析の誤差自由度を用いる。めでたくp値が計算される。
図は上がHADの出力(なぜか英語にしている…),下が自分で計算したもの。データは以前の note で言及した,森・吉田(1990, p.87)の例題である。
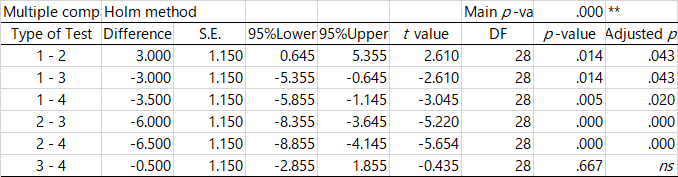
ただしここで計算されたp値がそのまま使えるのではなく,検定の多重性を考慮した修正が必要になる。そこが,Tukey の方法,Holm の方法, Bonferroni の方法で異なっているというわけである。それぞれどんな方法かは,青木先生のサイトや,清水先生のブログで説明されているので,ここでは省略する。
水準平均の標準誤差
さて,以上のことは,HADで出力されている「水準ごとの平均値」の標準誤差の算出にも(ということは,そのt検定にも)適用されるようである。水準ごとであるので,誤差分散に各水準のNの逆数をかけて平方根をとると標準誤差になる。これを使えば,信頼区間算出もt検定もできる。
ところが,HADが出している「全体平均」に関しては,どうもよくわからない。この際,私の立場を明確にしておくと,それは,【HADは常に正しい結果を出す。自分の計算結果と合わないときは,自分がどこかで間違えているのである】である。なので,計算結果が合わないとき,あるいは,なんでこんなことするの? という疑問が残る時には,理解を保留するのが原則だ。
「多重比較」や「水準ごとの平均値」の考え方を応用すれば,「全体平均」は,誤差分散に「全体Nの逆数」をかけて平方根をとればよい,と私は考えた。実際,各水準のNが等しいときには,この方法でHADの結果と一致する。ただし,各水準Nが異なる場合に,一致しない。ああ,悩ましい。
d 効果量と Hedges の補正
悩ましいことはもう一つあるので,あとでまとめて書くことにして,先に d効果量について書いておく。
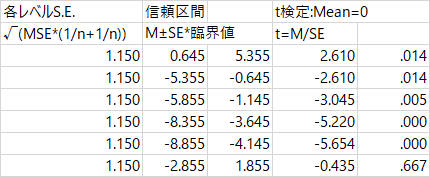
平均値差の効果量については,t検定についての note にも少し書いた。ここでも同じで,平均値差を誤差分散の平方根で割ると,ナマの効果量が出るのだが,これに Hedges の補正式を適用すると,無事にHADの出力と一致する。色を付けているところが,上述の通りの計算式を使って自分で計算したところ。統計法の教科書では,この補正式に触れておらず,平均値差を標準誤差で割った値を d(あるいは g)としているものがあるので注意が必要である。
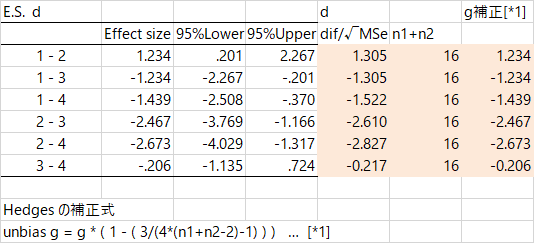
各水準Nが異なるとき
さて,ここまで書いてきた計算方法が正しいことを確かめるために(というのは実は嘘で,たぶんこうじゃないかなあ…と試してみた計算が合っているかどうか試すために,というのが最初のきっかけです。はい。),わざわざ水準ごとのNが異なるデータを使ってみた。適当に欠損値をまぜて,下の図の色を付けた部分のように,水準ごとのNがすべて異なるようにしてみた。平均値が大きく変化しないようにしてある。
では,このデータで分散分析をしたら,どうなるだろうか。同じ手順で自分で計算して,HADと同じ結果になるだろうか。
結果を書いてしまうと,多重比較の結果は完全に一致する。標準誤差を計算するときに,各水準のNを間違いなく計算に使ってやればよい。水準ごとの平均値も一致する。一致しないのは,全体平均と効果量である。
まず全体平均。

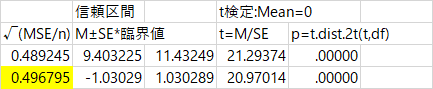
下が自分で計算した結果なのだが,標準誤差の計算は,分散分析の誤差分散に全体N(今回は26)の逆数をかけて平方根をとると,0.489になり,HADの結果と合わない。上図で黄色く網掛けした部分はHADの値と一致しているが,ここは異なる式を使っている。
1.まず,誤差分散に,各水準Nの逆数の和をかけて,平方根をとる。
2.次に,その値を水準数である(?)4で割る。
そうすると,HADが出している 0.497 と一致する。丸めの都合で違って見えるが,小数点のより小さい桁まで一致している。ここで疑問なのは,平方根をとったものを4で割るという操作である。この操作の意味がさっぱりわからない。平均なのだから4で割る,というのは変でしょう? だって標準誤差ですよ。測定値の平均ではない。Nの逆数をかけるという操作はわかるのです。標準偏差にNの逆数をかけると標準誤差になるのは(その理屈を説明しろと言われるとすぐにはできないのだが),統計学の教科書に書かれていることだ。それをなぜ4で割る?
説明がわからないということは,つまり,この方法は間違っているのだ,というのが,私の考えである。だって,【HADは常に正しい】が私の立場なのだから。
次に効果量。
さきほどと同じように計算すると,次のような値になる。
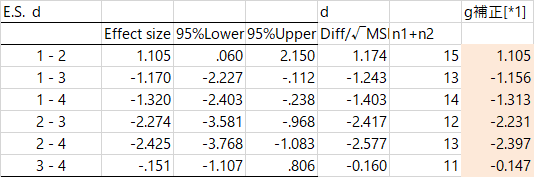
網掛けをした部分が,さきほどと同じ手順で計算した値である。最初のペア,「1-2」だけ一致しているというのも変で,あとは微妙に値が小さい。これは何なのだ?
HAD2Rも書いておこう
ということで,以上が書き残したこと&いくつかの疑問である。
最後に,いつものように,HAD みたいに出力できるRコードを書いてみようと思ったのだが,何しろ出力される情報が多いので,わたしの力量ではとんでもなく長いコードにならざるを得なかった。でも,やっていることはほとんど統計量の計算で,分散分析表などはRの関数でかなり対応できる。その部分だけ書いておくと,こんな感じ。
# 基本的な変数
av <- summary(aov(x[,1] ~ x[,2])) # 分散分析表
aw <- oneway.test(x[,1] ~ x[,2]) # Welch 分散分析
t0 <- TukeyHSD(aov(x[,1] ~ x[,2])) # 多重比較表
ho <- pairwise.t.test(x[,1], x[,2], p.adjust.method = "holm") # ホルム法修正p値
ms.e <- av[[1]]$`Mean Sq`[2] # 誤差分散
df <- as.numeric(av[[1]]$Df) # 自由度(要因,誤差)
HADが出力しない Tukey の修正p値を算出しているのは,この関数が水準のペアとその平均値差をデータフレームで返してくれるからで,それを使って標準誤差やらt検定の結果やらを書き足して,さらに pairwise.t.test で計算した Holm の修正p値を書き足して,HADみたいに(Tukey のおまけつき!)出力している,ということ。Welch の分散分析は oneway.test で検定結果が得られるのだが,平方和などはわからないようだ。あと,note では一言も触れなかったが,適合度指標も入っていない。これは今後の宿題。効果量の信頼区間もよくわからないので割愛。
というわけで,こんな感じの出力なのじゃ。
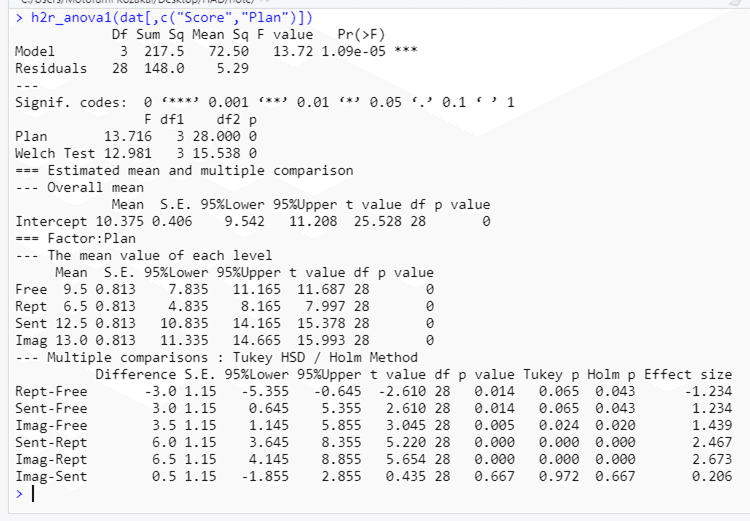
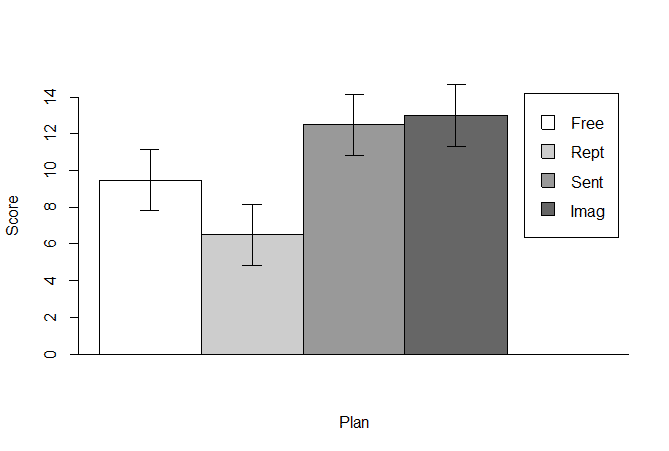
以上! 疲れたぜ。
タイトル画像はここのサイトにいつもお世話になっています。今回は「tired」で検索。か,かわいいぞ。