
行政の統計資料のような非構造化データをGPTで構造化データに変換する

今朝方GPT-4が発表されて、みなさん死ぬほど盛り上がってますねー。
GPT-4を使えば一発でできそうなネタではありますが、GPT-4 APIのお値段は3.5よりもお高めの設定なので、これからはどのように上手くGPTのバージョンを使い分けていくかが問われていくと思います。
というわけで今日は非構造化データを構造化データに変換する話です。
問題の背景
行政が定期的に公開している統計資料をご覧になったことはありますでしょうか。ディスる訳ではないですが、以下に示すのは私が住んでいる富士吉田市の統計資料です。
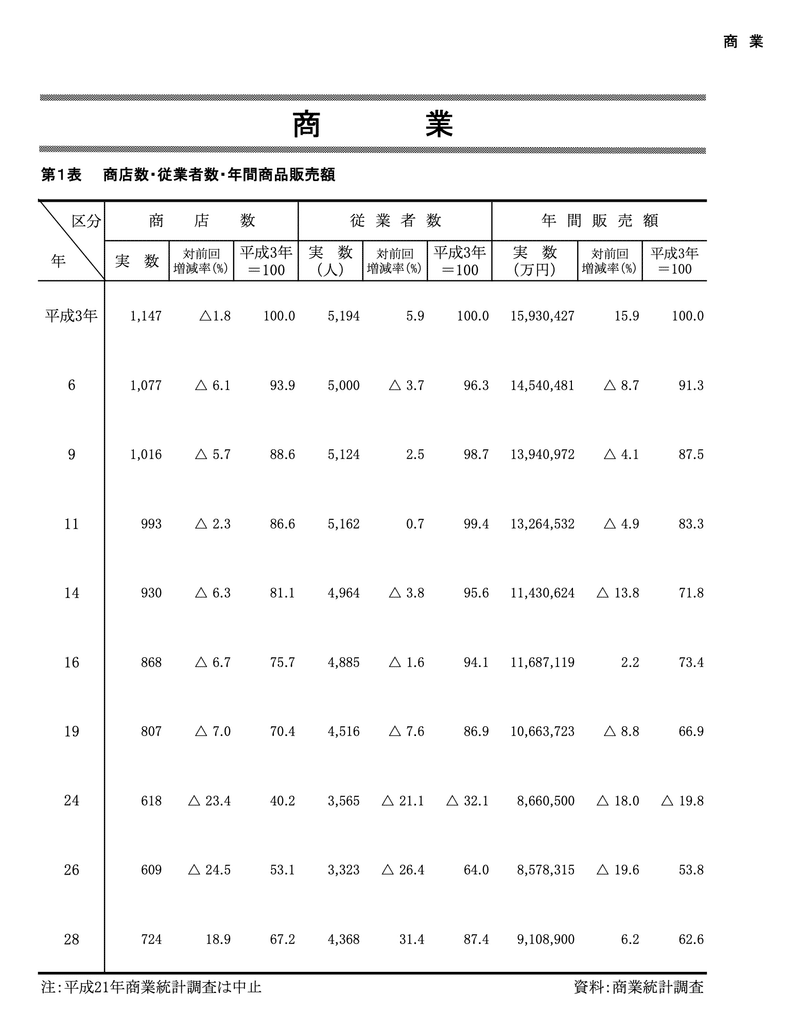
このように分かりやすい表で情報を提供してくれるのはありがたいのですが、数値データにはなっていないので分析に活用することができません。
GPTのパワーを使って、このような非構造化データを構造化データに変換できないか?というのが本日のお題になります。
コード
PDFのような非構造化データを、ある程度LLMで扱いやすい形に変換してくれるライブラリにUnstructured.ioというものがあります。
LangChainではUnstructured.ioで提供されているドキュメントローダーも透過的に扱えるようになっていまして、今回利用するPDFローダーも以下のような形で書けます。
from langchain.document_loaders import UnstructuredPDFLoader
loader = UnstructuredPDFLoader("./7syougyou_01.pdf")
data = loader.load()上記に貼り付けていたPDFは以下のようなデータに変換されます。
[Document(page_content='区分 年 実 数 対前回増減率(%) 平成3年=100 実 数 (人) 対前回増減率(%) 平成3年=100 実 数 (万円) 対前回増減率(%) 平成3年=100 平成3年 1,147 △1.8 100.0 5,194 5.9 100.0 15,930,427 15.9 100.0 6 1,077 △ 6.1 93.9 5,000 △ 3.7 96.3 14,540,481 △ 8.7 91.3 9 1,016 △ 5.7 88.6 5,124 2.5 98.7 13,940,972 △ 4.1 87.5 11 993 △ 2.3 86.6 5,162 0.7 99.4 13,264,532 △ 4.9 83.3 14 930 △ 6.3 81.1 4,964 △ 3.8 95.6 11,430,624 △ 13.8 71.8 16 868 △ 6.7 75.7 4,885 △ 1.6 94.1 11,687,119 2.2 73.4 19 807 △ 7.0 70.4 4,516 △ 7.6 86.9 10,663,723 △ 8.8 66.9 24 618 △ 23.4 40.2 3,565 △ 21.1 △ 32.1 8,660,500 △ 18.0 △ 19.8 26 609 △ 24.5 53.1 3,323 △ 26.4 64.0 8,578,315 △ 19.6 53.8 28 724 18.9 67.2 4,368 31.4 87.4 9,108,900 6.2 62.6 商 店 数 従 業 者 数 年 間 販 売 額\n\n注:平成21年商業統計調査は中止\n\n資料:商業統計調査', lookup_str='', metadata={'source': './7syougyou_01.pdf'}, lookup_index=0)]今回は潰しの効くJSON形式に変換したいと思いますので、以下のようなプロンプトでGPTに変換をお願いしたいと思います。
from langchain.llms import OpenAIChat
llm = OpenAIChat(temperature=0.0)
prompt = f'''
以下に示すデータは、市町村の統計データとして提供されているPDFをUnstructuredPDFLoaderによりテキスト化したものである。
平成3年から28年までの行をJSONデータに変換せよ。
以下は平成3年度の行をJSON化した場合の例である。
# JSON
[
(
"年": "平成3年",
"商店数": (
"実数": 1147,
"対前回増減率_%": -1.8,
"平成3年=100": 100.0
)
)
]
# データ
{data[0].page_content}
'''
print(prompt)
result = llm(prompt)
print(result)可能な限り元データに忠実に変換して欲しいので、temperatureは0.0に設定をしています。また、プロンプトを与えるとき { や } といった文字が特別な制御文字として解釈されてしまう挙動があるので、正しいJSONではないですが ( や ) といった文字に置き換えています。
すると、アッサリこんな感じで構造化データに変換してくれました。
[
{
"年": "平成3年",
"商店数": {
"実数": 1147,
"対前回増減率_%": -1.8,
"平成3年=100": 100.0
},
"従業者数": {
"実数": 5194,
"対前回増減率_%": 5.9,
"平成3年=100": 100.0
},
"年間販売額": {
"実数": 15930427,
"対前回増減率_%": 15.9,
"平成3年=100": 100.0
}
},
{
"年": "平成6年",
"商店数": {
"実数": 1077,
"対前回増減率_%": -6.1,
"平成3年=100": 93.9
},
"従業者数": {
"実数": 5000,
"対前回増減率_%": -3.7,
"平成3年=100": 96.3
},
"年間販売額": {
"実数": 14540481,
"対前回増減率_%": -8.7,
"平成3年=100": 91.3
}
},
{
"年": "平成9年",
"商店数": {
"実数": 1016,
"対前回増減率_%": -5.7,
"平成3年=100": 88.6
},
"従業者数": {
"実数": 5124,
"対前回増減率_%": 2.5,
"平成3年=100": 98.7
},
"年間販売額": {
"実数": 13940972,
"対前回増減率_%": -4.1,
"平成3年=100": 87.5
}
},
{
"年": "平成11年",
"商店数": {
"実数": 993,
"対前回増減率_%": -2.3,
"平成3年=100": 86.6
},
"従業者数": {
"実数": 5162,
"対前回増減率_%": 0.7,
"平成3年=100": 99.4
},
"年間販売額": {
"実数": 13264532,
"対前回増減率_%": -4.9,
"平成3年=100": 83.3
}
},
{
"年": "平成14年",
"商店数": {
"実数": 930,
"対前回増減率_%": -6.3,
"平成3年=100": 81.1
},
"従業者数": {
"実数": 4964,
"対前回増減率_%": -3.8,
"平成3年=100": 95.6
},
"年間販売額": {
"実数": 11430624,
"対前回増減率_%": -13.8,
"平成3年=100": 71.8
}
},
{
"年": "平成16年",
"商店数": {
"実数": 868,
"対前回増減率_%": -6.7,
"平成3年=100": 75.7
},
"従業者数": {
"実数": 4885,
"対前回増減率_%": -1.6,
"平成3年=100": 94.1
},
"年間販売額": {
"実数": 11687119,
"対前回増減率_%": 2.2,
"平成3年=100": 73.4
}
},
{
"年": "平成19年",
"商店数": {
"実数": 807,
"対前回増減率_%": -7.0,
"平成3年=100": 70.4
},
"従業者数": {
"実数": 4516,
"対前回増減率_%": -7.6,
"平成3年=100": 86.9
},
"年間販売額": {
"実数": 10663723,
"対前回増減率_%": -8.8,
"平成3年=100": 66.9
}
},
{
"年": "平成24年",
"商店数": {
"実数": 618,
"対前回増減率_%": -23.4,
"平成3年=100": 40.2
},
"従業者数": {
"実数": 3565,
"対前回増減率_%": -21.1,
"平成3年=100": -32.1
},
"年間販売額": {
"実数": 8660500,
"対前回増減率_%": -18.0,
"平成3年=100": -19.8
}
},
{
"年": "平成26年",
"商店数": {
"実数": 609,
"対前回増減率_%": -24.5,
"平成3年=100": 53.1
},
"従業者数": {
"実数": 3323,
"対前回増減率_%": -26.4,
"平成3年=100": 64.0
},
"年間販売額": {
"実数": 8578315,
"対前回増減率_%": -19.6,
"平成3年=100": 53.8
}
},
{
"年": "平成28年",
"商店数": {
"実数": 724,
"対前回増減率_%": 18.9,
"平成3年=100": 67.2
},
"従業者数": {
"実数": 4368,
"対前回増減率_%": 31.4,
"平成3年=100": 87.4
},
"年間販売額": {
"実数": 9108900,
"対前回増減率_%": 6.2,
"平成3年=100": 62.6
}
}
]結果の検証
投入したPDFと見比べてみても、驚くほど正確にデータ変換できていることが分かります。
LLMに対しては以下のようなテキストデータを渡しているのに過ぎないので、このテキストデータを構造化データに変換できるのは驚きですね。。
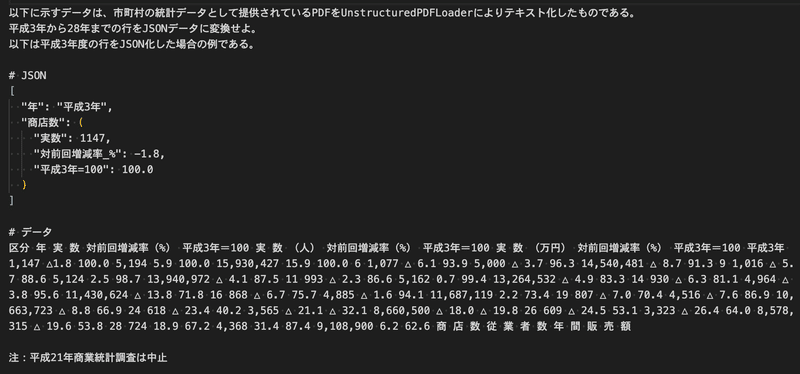
「この文字列を元に構造化データへ変換するプログラムを書け」と言われてもぶっちゃけ書けない自信があるので、GPTは本当に凄いな・・と感じています。
個人的にはこのようなデータ to データの変換用途のLLMに大きく期待感があります。もちろん構造を分析した上でプログラミングによってこの手の課題を解決することは可能ですが、今回例に挙げたようなデータでは構造分析の負荷が高く、また同じようなデータ構造が二度と出てこない(アドホックに表が作られている)可能性が高いため、構造分析のコストと見合わない可能性が高いです。
このような人的コストと比較するとLLMの利用コストは限りなく小さいので、多少精度に問題があったとしてもLLMを活用して分析する方向性は有用だと考えています。投入されるデータのデータ構造が毎回ばらついていればばらついているほど、LLMの方が有利です。
さらに行政が公開している統計資料のような非構造化データを簡単に構造化データに変換できたという結果はCivic Techを推進するための材料にもなりそうで、その点でも個人的には期待しています。
現場からは以上です。
この記事が気に入ったらサポートをしてみませんか?