image-to-video紹介 ~Animate Anyone~

噂の一貫性のある動画生成が可能という手法、Animate Anyone。
Demoを見る限りかなり可能性を感じる精度ですが、コードがまだ未公開なのでまた公開された別記事で書こう(水増し)
なるべく手を動かすアドカレにしたかったけど、こういうのもあり。
それはそうと、こういう時のデモが大体版権絵なのは何故なんだろ
ファンアートらしいけど、公式じゃないからフェアユースってこと?
Animate Anyoneとは?
手法自体が話題性の高いものだったので、↓のような詳細に解説されてる記事もあるのでそちらを読む方がボリュームはありそうだけど、
理解のために解説を試みる。
概要
任意のキャラクターの静止画像をリアルタイムの動画に変換する手法の提案
一貫性のあるキャラクターの外観を保持できる
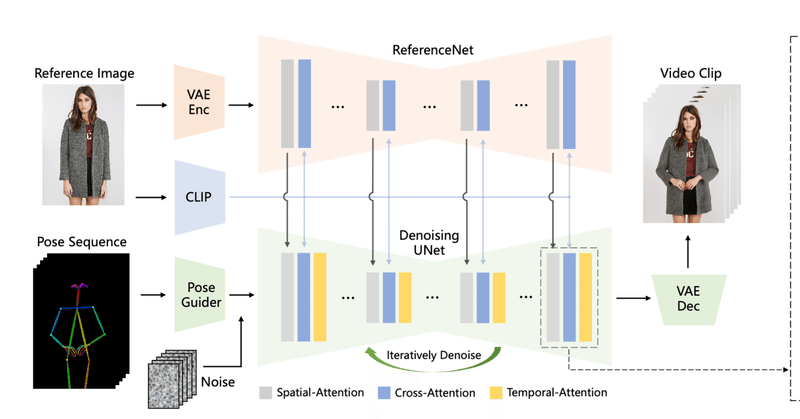
「ReferenceNet」と呼ばれるネットワークを提案し参照画像から詳細な特徴を抽出し、動画生成含める。
「Pose Guider」という軽量のモジュールを使用して、キャラクターの動きを制御するらしい?
モデル構造

ContorollNetっぽい構造
Denoising UNetと大体同じ構造だけど、temporal layer(時系列層?)を含まないそう。
spatial-Attention層でReferenceNetとDenoising Unetを結合
画像特徴量のネットワークと、ポーズの時間変化の特徴量を分けて扱ってるイメージ?
Pose Guiderは、4つの畳み込み層を使用してポーズ画像を、ノイズ潜在表現と同じ解像度に合わせるために使用するらしい。
データセット
研究チームはインターネットから収集した2〜10秒の長さの5,000のキャラクタービデオクリップを使用
ビデオクリップからは、DWPoseとOpenPoseを使用して、キャラクターのポーズシーケンスが抽出され、ポーズスケルトン画像としてレンダリング
4つのNVIDIA A100 GPUを使用して学習
精度評価
提案された手法は、UBCファッションビデオデータセットとTikTokデータセットの両方で主にSSIM、PSNR、LPIPS、FVDを用いて評価
↓ChatGPTにそれぞれの評価項目について聞いた結果SSIM (Structural Similarity Index Measure):
画像の構造的な類似性を測定するために用いられる指標です。
画像の明るさ、コントラスト、構造の3つの要素を比較して、一致度を数値化します。
PSNR (Peak Signal-to-Noise Ratio):
画像の品質を測定するための指標で、特に圧縮画像の評価に用いられます。
オリジナル画像と比較したときの誤差の大きさをデシベル(dB)単位で表します。
LPIPS (Learned Perceptual Image Patch Similarity):
画像の知覚的な類似性を測定するための指標で、ディープラーニングを用いて訓練されます。
画像のパッチレベルでの知覚的な差異を評価します。
FVD (Fréchet Video Distance):
動画の品質を測定するために開発された指標です。
動画の特徴を抽出し、それらの特徴の分布間の距離を計算します。


既存の制御手法と比べても良いスコアらしい

総括
時間変化方面を扱いやすくしたContorollNet的な印象で、モデルの仕組み自体はそこまで間違ってないけどデータセットが結構独特かも
評価もTikTok使ったらしいし、コードが公開されても動かせるかどうか怪しいところがあるな…
今一つ評価のところが読み足りなくて、Tiktok動画を再現するようなことができたって理解でいいのかな?だとしたら学習データにないような動きをさせると破綻するかもしれんのか。
あとは「キャラクター」がどこまで含まれてるか…
この記事が気に入ったらサポートをしてみませんか?