
生成AI、ファンデーションモデルを理解し、AI実装社会の適用例を考える

ChatGPT4やStable Diffusionとともに作業をするスタイルが当たり前になって数ヶ月ほど。賢いアシスタントを手に入れた喜びがある反面、ジェネレーティブAIとChatGPTの関係、よく耳にするファウンデーションモデル(基礎モデル)と個別のアプリケーションであるChatGPTの関係などがいまいち掴みきれてなかった。そして優秀なアシスタントがたまに嘘をつくのは何故なのか?
我が古巣IBMのIBM Research シニア・マネージャーのケイト・スール氏のYouTube(2023年3月)が基礎理解を深めるのに役立ったので日本語版と自分が学べたポイントをメモとして当noteに残していきます。彼女がカメラを前に、ニコニコしながら鏡文字で要点を伝えていくパフォーマンスも見応えありの8分動画の日本語ダイジェスト+スタンフォードの2021年論文を交えてお届けしていきます。
■IBM ResearchによるAI生成モデルの説明
まずIBM Researchのケイト・スール氏はChatGPTなどに代表されるAI = 大規模言語モデル(LLM Large Language Model) は、「ファンデーションモデル(基礎モデル)」と呼ばれるモデルの一部である、と語ります。このファンデーションモデルをベースにして、言語系のLLM、ビジョン系、コード系、環境系、化学系などのモデルが派生しています。
この「ファンデーションモデル」という言葉は、スタンフォード大学のチームが、AIの分野が新しいパラダイムに移行していることを示すために作った言葉である、とケイト・スール氏は語ります。
なぜスタンフォードがそれまでのAIアプリケーションと差別化するためにファンデーションモデルという概念を打ち立て進めていくことになったのか?

以前は、AIアプリケーションはトレーニングによって構築されていました。各AIモデルは、タスクに特化したデータで訓練され、非常に特殊なタスクを実行するようになっていました。ですが、同じユースケースやアプリケーションをすべて駆動できる基礎的な能力だけを集約するファンデーションモデルをつかうと、いくつものタスクに転用することができます。つまり、従来のAIで以前から想定していたのとまったく同じアプリケーションを、同じモデルでいくらでも追加的に駆動できるのです。
■AIが実装された社会のヒント
つまり「ファンデーションモデル」があれば、様々なAIアプリケーションを作っていくことが可能。スタンフォード大学のCenter for Research on Foundation Models (CRFM)が2021年に発表した「On the Opportunities and Risks of Foundation Models」論文のなかにわかりやすい図解があるので以下に紹介していきます。図の左側にある膨大なデータ(テキスト、イメージ、音声スピーチ、構造データ、3Dシグナル etc )をトレーニングしてファンデーションモデルを作り上げると、その後は右側のアプリケーション、タスクに応用していけるようなイメージをわかりやすく伝えてくれています。
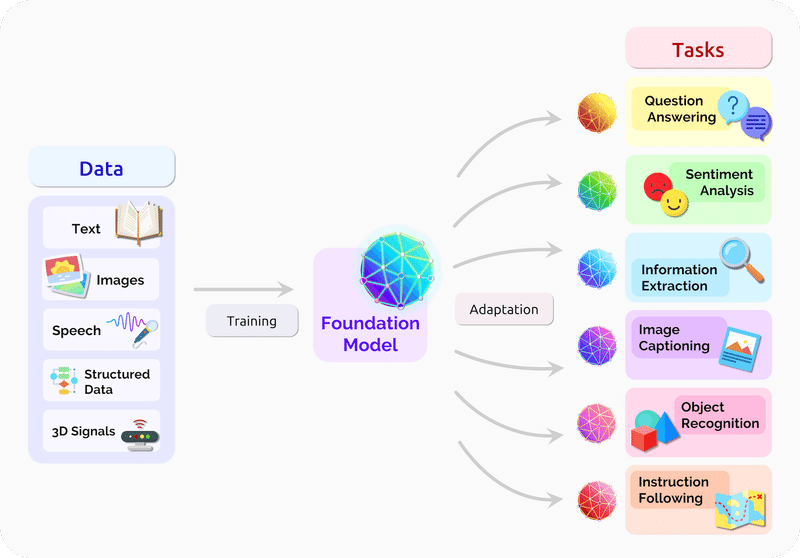
このスタンフォードの論文は214ページあるのでなかなか読み解くのに根気が必要となりそうですが、ファンデーションモデルを活用した医療、ロボット、教育など図解もしてあるので今後のビジネスヒント(どのような日本のデータを取得すれば、今後のAI時代のビジネスに活かしていけるのか?)を得るために図だけを眺めてても参考になります。AIが実装された社会がどうなるのか?考えるヒントにもなりそうです。

データソースとして病院や、薬局、保険などのデータを活用することにより、ケアマネージャーによる診断や患者の質問に答えるサービスを作ることも可能になりそうです。そして、レントゲン写真や遺伝子データなどからパーソナライズされた医療を受けたり、新薬発見に結びつく可能性もありそう。
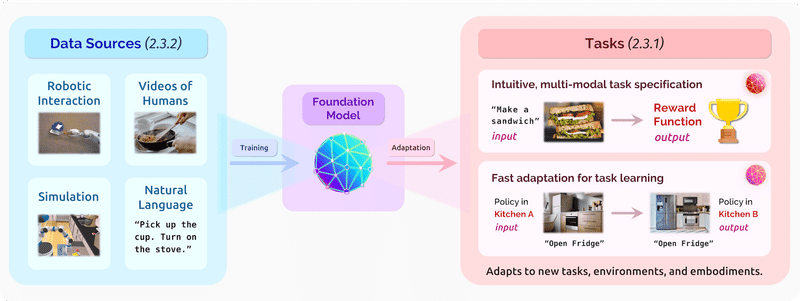
データソースとしてロボットインターフェイスや、シミュレーションだけではなく、人間の動作ビデオや自然言語データをファンデーションモデルに入力し、タスクと達成報酬を与えることにより人間の動作に近い操作を自然言語で提供してくれるようになりそうです。
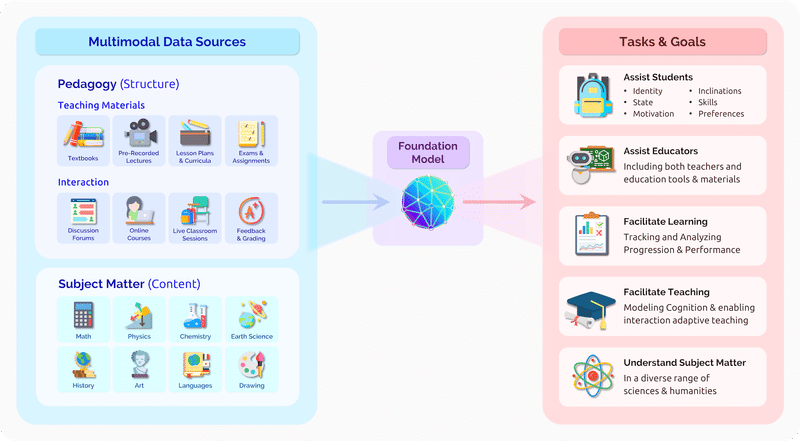
教科書、授業アーカイブ、成績表、そして数学、物理、美術などのそれぞれのデータをファンデーションモデルに入れることにより、新たな教育向けのサービスも作れそう。
■ファンデーションモデルの利点と欠点
さて、IBM Researchのケイト・スール氏のビデオに戻りましょう。ファンデーションモデルが存在することにより、様々なAI応用ビジネスが生まれてくる可能性を感じるが、ケイト・スール氏はファンデーションモデルの利点と欠点も述べています。
ファンデーションモデルの最大の利点は性能です。
非常に多くのデータを扱ってきているので、ファウンデーションモデルを活用したタスクを作る際に、どんな小さなタスクに適用した場合でも、わずか数点のデータ(少量データ)でモデルを劇的に向上させることができます。
ファンデーションモデルの2つ目の利点は、生産性の向上です。プロンプトやチューニングによって、タスクに特化したモデルを作るために必要なラベルデータは、ゼロから始めるよりもはるかに少なくて済みます。
私がこのファンデーションモデルで感動するのは、膨大な量の非構造化データと、教師無し方式で鍛え上げているところ。以前のAIであればAI向けのデータを用意し、教師データ(機械学習)をすることにより作り上げていたのが、そのような準備も不要になるという。その感動部分は以前書いたnoteエントリーにも掲載しているので参考までに再掲します。
利点がある一方で、欠点もある、とIBM Researchケイト・スール氏は語ります。
ファンデーションモデルの欠点の一つ目は、計算コストです。
このファンデーションモデルは多くのデータを必要とするために、トレーニングに非常にコストがかかります。そのため、中小企業が独自にファンデーションモデルを構築することは困難です。また、巨大なサイズになると、数十億円のコストがかかります。ファンデーションモデルをホストして推論を実行するためだけに、一度に複数のGPUが必要になることもあり、従来のアプローチよりもコストがかかるのが欠点の一つ目です。
2つ目の欠点は、信頼性です。構造化されていない膨大データは基本的にインターネットからかき集めた言語データから学習されます。
例え人間のアノテーター(画像・動画・音声・テキストなどの対象データにラベル付けを行い、教師データを作成する人)がいたとしても、すべてのデータポイントをレビューすることは不可能です。つまり、データ一つひとつに目を通し、それが偏っていないか、ヘイトスピーチや有害な情報を含んでいないかどうかを確認することはできません。
これは、データが何であるかを実際に知っていると仮定した場合の話です。多くのオープンソースモデルでは、正確なデータセットが何であるかさえわからないことがあります。
出典元がわからないデータセットを元にしているので、導かれる言葉に危険性を伴うことが、信頼性の問題につながるとケイト・スール氏は語り、ビジネス分野でITを支えているIBMは企業導入の際に安心してモデルのイノベーションに取り組んでいるといいます。確かに私がアイディエーションの相棒として使う分にはChatGPTは問題ないですが、契約書などのドキュメントを生成する際に嘘があると恐ろしいことになります。ファンデーションを作るには膨大な費用がかかるのでITジャイアントや、日本だとソフトバンクのような企業に頼ることになりますが、信頼できるデータセットを使ってもらいたいと思います・・・(と、同時にどのデータセットが信頼できるのか?もまた議論の種にはなりそうですね。)
■ファンデーションモデル活用アプリケーション事例
ケイト・スール氏の動画はその後、LLM言語モデル以外にもファンデーションモデルを活用した別事例も紹介しています。
・DALL-E 2:テキストデータからカスタム画像を生成するビジョンモデル
・Copilot:オーサリング中にコードが完成可能
また、IBMもファンデーションモデルを作っているようです。IBM Watson にも言語モデルやビジョンモデルが組み込まれていたり、以下のようなモデルも提供しているようです。
・Maximo Visual Inspection:IBMのビジョンモデル
・Ansible:IBMのコードモデル(Red Hatと動いているProject Wisdom)
・molformer:分子研究やさまざまな治療薬を促進
・気象変動モデル:気候研究を向上させるために地理空間データを用いた地球科学財団のモデルを構築
■何故嘘をつくのか?
ケイト・スール氏はYouTubeのなかで、ファンデーションモデルから作られたLLMは与えられた単語をもとに、文の最後の単語を予測するモデルを作る振る舞いをすると語ります。
事前に見た単語に基づいて次の単語を予測し、生成することができるのです。そのため、ファンデーションモデルは「ジェネレーティブAI」と呼ばれるAIの分野の一部となっています。文の中の次の単語という新しいものを生成しているからです。
ChatGPT4になり、3.5よりも圧倒的に賢くなってはいるが、私が驚いたのは相変わらず嘘をあたかも本当かのように続けていくことです。実際に私が遭遇したケースは、ある英語の文章をChatGPT4に読み込ませて要約をしてもらっていたときのこと。要約テキストが途中で途切れてしまったので「続けて下さい」とプロンプト入力しました。要約は完了したのですが、遊び心で「続けて下さい」を再度入力したところ、英語の本文には書かれていないことを要約として語りだしました。私がある程度英語の文献の内容を把握できていたので間違いに気が付きましたが、「続けてください」というコマンドを受けて推論で続けてしまうよりも「もう続きはありません」と潔く断ることを学んでもらいたいと思った瞬間です。優秀なアシスタントはまだ断ることを学びきれてないようです(知らないデータに対しては知りません、とは言えるようにはなってますが)。
便利なアシスタントGPT4も特性を知ることにより扱い方がわかってきます。今回はIBMのデータとスタンフォードのデータを元にnoteの記載しましたが、今後は別企業(メタ、グーグル)のアプローチもまた紹介していければと思います。進化が激しいAIですが、その構造も理解しながら活用していくことにより、ツールに振り回されずに人間らしく居続けられそうです。
この記事が気に入ったらサポートをしてみませんか?