
Photo by
06reiroku
データリテラシーの初歩の初歩③

③データから情報を抽出する
今回は、今までより少しデータの見方を深掘りしたいと思います。
突然ですが、以下に3つの時刻表があります。(最近、時刻表自体を見る機会が少なくなりましたが。。。)




これらの時刻表を比較して、特徴を述べてみてください。
感覚的なものではなく、定量的に比較するにはどうしますか。
こんなふうにしてみると、比べるヒントが得られるでしょうか。
上の時刻表のままでも同じように見えますが、このように見ると、例えば、Aはあまり時間帯によって本数が変わらないことや、BとCでは夜のピーク時間帯が少しずれていて、Bの方では20時台が一番多く、Cでは18時台が一番多いことが分かります。Cは24時台の電車がないことを考えると、Cは全体的に少し早めに人の移動が起こる駅と言えるかもしれません。
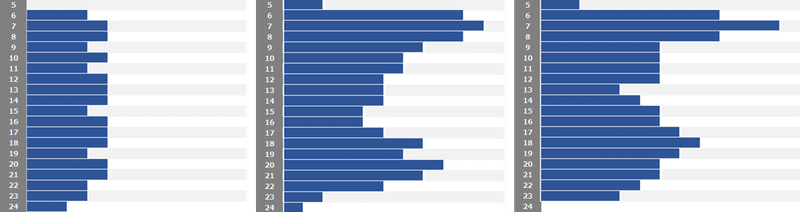
これはあくまでも一つの例ですが、こういった統計的なデータにすると、比較がしやすくなりますね。時刻表を見るだけで『なんとなく』分かることですが、数字にするとより明確になります。
・BとCは似ているように見えたけど、電車の本数としては7本違うだけだな
・AとCは倍近い差があるんだな
・最大の本数はAとCでは3倍の差があるな。全体の本数よりも大きいな
こういった気づきは、時刻表を眺めて比較するだけで得られたでしょうか。

仕事をしていると、データ(リスト)をそのままリストとして出してきて、全体の状況は〇〇です、と報告してくる人がいます。データ(リスト)のままではなかなか理解が進みません。理解するにはデータから『情報』を抽出しないといけません。これができるかどうか、それがデータリテラシーにつながるんじゃないでしょうか。
この記事が気に入ったらサポートをしてみませんか?