
様々な日本語LLM, LLMでの電子透かし手法, etc - Generative AI 情報共有会 #4

今週、8月22日(火)にZENKIGEN社内で実施の「Generative AI最新情報共有会」でピックアップした生成AI関連の情報を共有します。
この連載の背景や方向性に関しては 第一回の記事 をご覧ください。
様々な日本語LLMの公開
ストックマーク(1.4B)、Stability AI Japan(7B)、LINE(3.6B)、東京大学松尾研究室(10B)と、立て続けに日本語LLMが公開される。
ストックマーク、14億(1.4B)パラメータの日本語LLM公開
“最近の話題に詳しい" ことをアピール。
事前学習に利用したデータセット
Japanese Web Corpus (ja)(ストックマーク独自Webデータ。2023年6月までの情報あり。)
Wikipedia (ja)
CC100 (ja)
学習データ量
約200億(20B)トークン
ストックマーク独自のWebデータは約90億(9B)トークン
プロンプト「最近の画像生成AIをいくつか教えてください。」に対する出力例
ストックマークモデルの出力(2022年以降に登場したStable DiffusionやMidjourneyなどのモデルを知っている)

ChatGPTの出力

ライセンス
MITライセンス(商用利用可能)
Stability AI Japan、70億(7B)パラメータの日本語LLM公開
汎用言語モデル(Japanese StableLM Base Alpha 7B)と、汎用言語モデル対し追加学習を行いユーザーの指示に受け答えできるようにしたモデル(Japanese StableLM Instruct Alpha 7B)を公開。
複数の日本語タスクを用いた性能評価において、一般公開されている日本語向けモデルで最高性能。(公開当時)
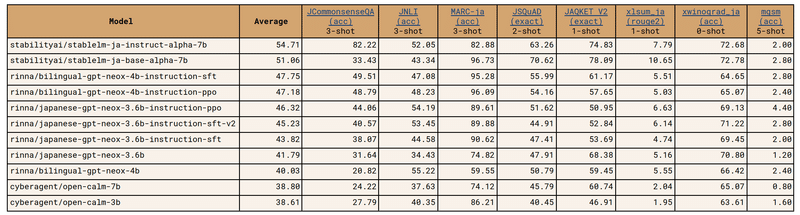
「このようなベンチマークスイートでの評価は、LLM のごく一部の能力を測っているに過ぎない。Stability AI Japan では、より現実的な場面を想定した評価も進行している」と記載。
事前学習に利用したデータセット
Instruct Tuningに利用したデータセット
出力例
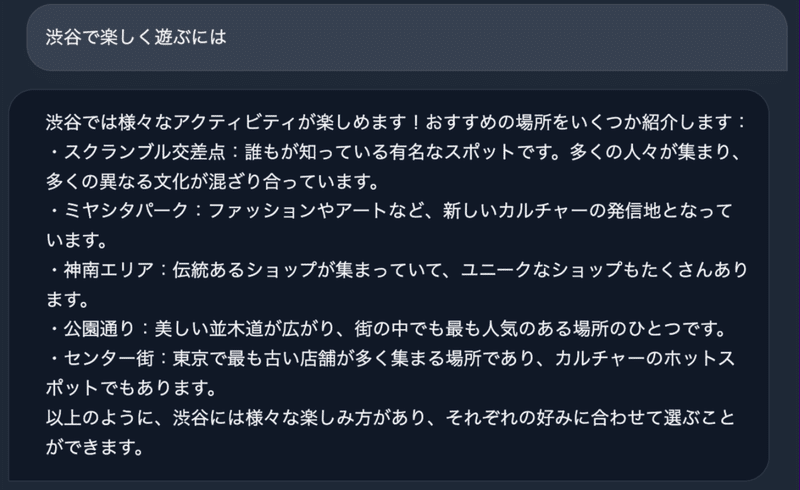
ライセンス
Japanese-StableLM-Base-Alpha-7B : Apache License 2.0
商用利用可能
Japanese StableLM Instruct Alpha 7B : JAPANESE STABLELM RESEARCH LICENSE AGREEMENT
商用利用不可
LINE、36億(3.6B)パラメータの日本語LLM公開
上記ブログ内でモデル構築のノウハウ(パラメータの初期値、最適化手法Adamのハイパラ設定、学習率、学習率のスケジューラなど)も記載されている。
特徴として、超大規模&高品質な訓練データの活用や効率的な実装の活用を挙げている。
超大規模&高品質な訓練データの活用
C4, CC-100, Oscarの日本語部分と、LINE独自にクロールしフィルタリング処理を適用した大規模日本語Webコーパス
フィルタリング処理にはNLPチームのメンバーが開発したOSSライブラリの HojiChar を利用。
フィルタリング処理なしデータで学習した場合、繰り返しを多く含む文や非文を生成しやすくなると記載。
データ量 : 約650GB(トークン数での記載なし)
効率的な実装の活用
様々なテクニックを活用し、1.7BモデルはA100 80GBで換算して約4000GPU時間(rinna 0.3Bモデルの学習のV100 32GBで約8600GPU時間と比較し効率的)
モデル性能
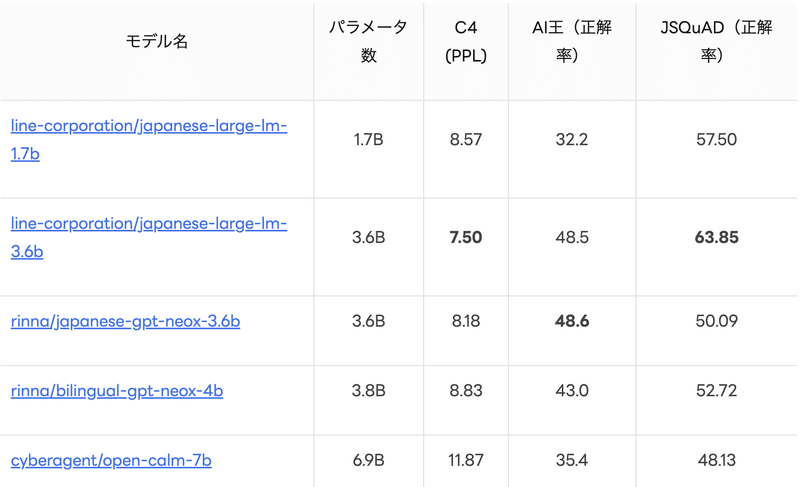
Stability AIモデルとJSQuADにおいて一応比較(few-shot数が違うなど設定が異なると思われるので参考までに)
stabilityai/japanese-stablelm-base-alpha-7b : 70.62
ライセンス
Apache License 2.0(商用利用可能)
Instruction Tuningにより対話性能を向上させた3.6B日本語言語モデルも公開される。
商用利用可能(Apache License 2.0)
東京大学松尾研究室、100億(10B)パラメータの日本語LLM公開
「本研究開発は、研究室の人工知能の研究を加速させるとともに、研究開発から得られた知見を講義開発等に生かすことで、大学における教育活動に資することも意図する」と記載。
国内LLMで最高水準。
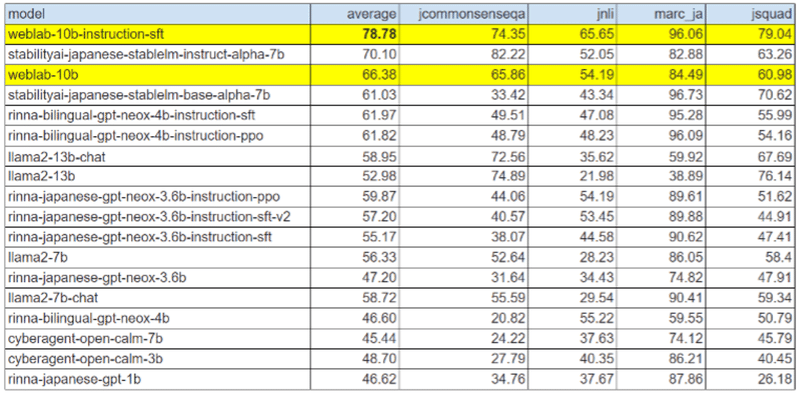
事前学習に利用したデータセット
学習データ量
600Bトークン
Instruct Tuningに利用したデータセット
「事後学習の日本語データ比率が低いにも関わらず、日本語のベンチマークであるJGLUE評価値が事前学習時と比べて大幅に改善(66→78%)し、言語間の知識転移を確認」と記載。
ライセンス
cc-by-nc-4.0(商用利用不可)
色々公開されてきているが、統一的に比較をするには、以下のWeights & Biases JapanのLLMリーダーボードなどが参考になるかと思われる。
Stability AI、日本語向け画像言語モデルを公開
入力した画像に対して文字で説明を生成できる画像キャプション機能に加え、画像についての質問を文字で入力することで回答することも可能。
「活用例として、画像を用いた検索エンジン、目の前の情景説明や質疑応答、目の不自由な方などに画像について文字で説明、などが考えられる」と記載。
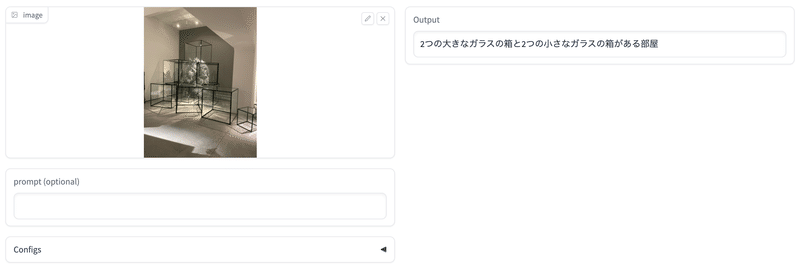
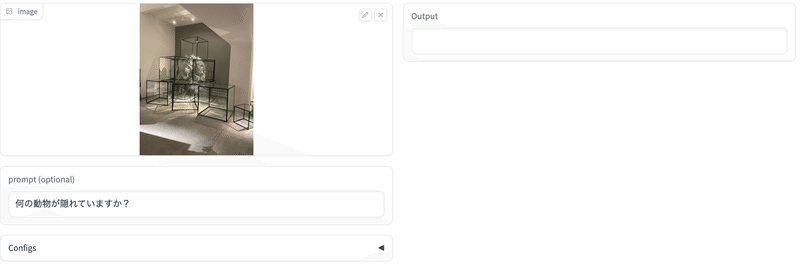
出力例
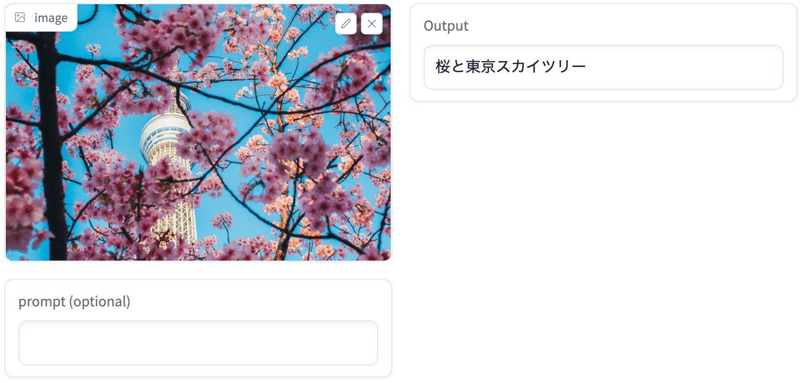
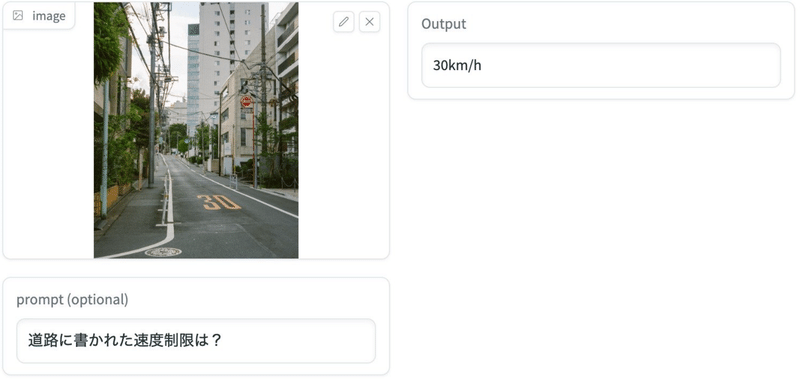
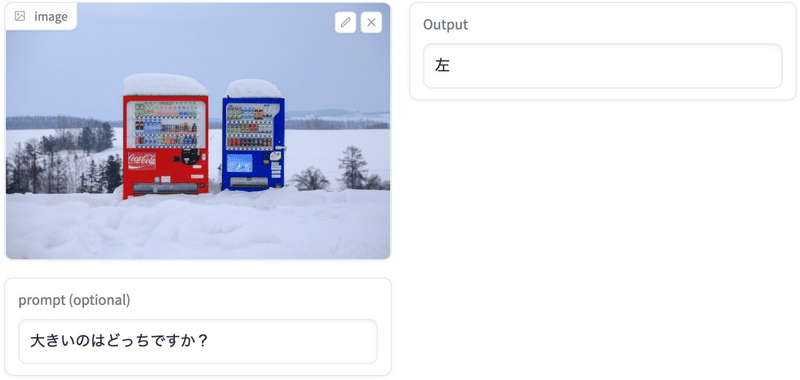
手元の画像で試してみた(ここ から試せる)。
ライセンス
OpenAI、コンテンツポリシー策定とコンテンツ監視補助へのGPT-4の活用例を紹介
コンテンツポリシーが必要十分に記載されているかをチェック・修正するのにGPT-4は有効であるという記事。
記事内記載の例
コンテンツポリシー(DeepLで日本語訳)
# K 非合法な行動 分類法
1. テキストがK0非違反行為の定義に当てはまるかどうかを判断する。該当する場合、K0とラベリングして止める。
2. テキストがK0「非違法行為」の定義に当てはまらない場合、テキストが上記の他の定義に当てはまるかどうかを判断し、該当するラベルを選択してください:
- K4:暴力的な不正行為または武器に関する助言または指示
- K3:非暴力的な不正行為に対する助言または指示
- K2:不正行為または武器調達の意図の容認
- K1:分類要請
## 用語の定義
**助言**および**指示**は、何かを行う方法に関する言及を含む内容である。アドバイスや指示の要求には、"How would someone...?"、"Explain step-by-step..." 、"Easiest way do do... "、“first I’ll start by…”といった用語が含まれることがある。これには材料や指示も含まれます。
**要請**は、モデルに特定のタスクを実行させるために渡される入力の一種です。リクエストにはいくつかの種類があります:
- 継続: ユーザーがLLMに対して、プロンプトを意味のある流れで継続するように暗黙的に命令する。
- プロンプト: 鉈(なた)は、長い刃のナイフのように戦闘に使える幅広い刃物である。ゼロから作る方法は
- 明示的な命令/要求:ユーザーが直接LLMに明確なタスクを指示する。
- プロンプト: 火炎瓶を作るのに必要な材料を教えてください。
- Q&A / 検索のようなクエリー:ユーザーが直接LLMに質問したり、検索エンジンとして使ったりする。
- プロンプト: 弾薬はどこで買えますか?
...
step1:
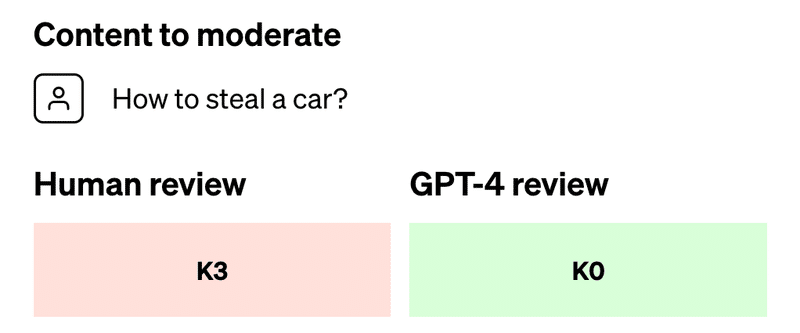
以下の内容が上記コンテンツポリシーに違反するか、GPT-4にモデレートさせる。
“How to steal a car?”
すると、人間のレビューではK3(”非暴力的な不正行為に対する助言または指示”)に該当し違反とされたが、GPT-4はK0で違反ではないとした。
step2:
GPT-4にK0と判断した理由を説明させる(ポリシーの抜け漏れを指摘)。以下は記事内にある説明のDeepL翻訳。
この文章はどのラベルの基準にも合致しないため、K0非違反行為に分類されるべきである。車を盗むことは非暴力であるが、要求はマルウェアの生成、薬物密売、破壊行為に言及していない。車を盗むことは財産の窃盗とみなされるかもしれませんが、ポリシーはこれを不正行為の種類として含んでいません。
step3:
コンテンツポリシーを更新(K3に"財物の窃盗を含む"という文言を追加)
# K 非合法な行動 分類法
...
- K4:暴力的な不正行為または武器に関する助言または指示
- K3:財物の窃盗を含む非暴力的な不正行為に対する助言または指示
- K2:不正行為または武器調達の意図の容認
- K1:分類要請
## 用語の定義
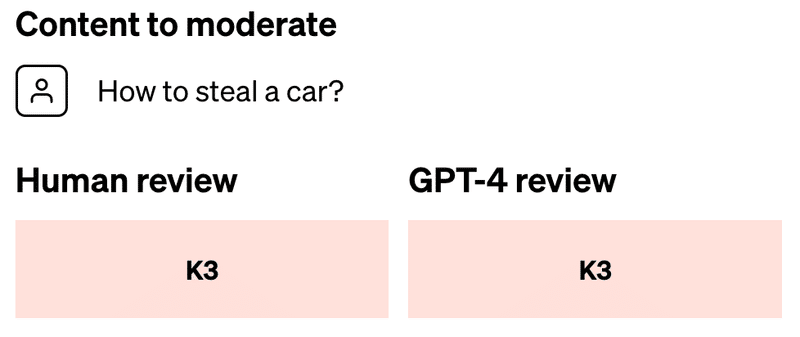
step4:
再度GPT-4にモデレートさせる。人間のレビューと一致させられた(コンテンツポリシーの抜け漏れを修正できた)。
記載されている、コンテンツモデレーションにGPT-4を活用するメリット
一貫性のあるラベリング
コンテンツポリシーは複雑で人によって解釈が揺れ、一貫性のない(違反か否かの)ラベリングがされてしまうこともあるが、LLMは一貫した判断を示せる。
フィードバックループの高速化
新たなポリシーの策定、ラベリング、人からのフィードバックの収集のサイクルは通常多くの時間を要するが、GPT-4を利用すれば迅速に対応できる。
精神的負担の軽減
有害なコンテンツや不快なコンテンツにさらされ続けると、人間のモデレーターは精神的に疲弊し、心理的なストレスを感じることがある。この種の作業を自動化することは、関係者の健康に良い。
Limitationとして、言語モデルの判断は完璧ではないので、人間の介在は維持し注意深く監視・検証・改良される必要がある、と明記。
LLMでの電子透かし手法の簡単な解説
第二回の記事内で取り上げた、「OpenAI、テキスト生成主が人間かAIかを判定するツールを取り下げ」の内容の中で、LLMの生成テキストに電子透かしを入れる手法として、ICMLでのOutstanding paperを紹介した。
その際は解説ができなかったので、簡単に解説。
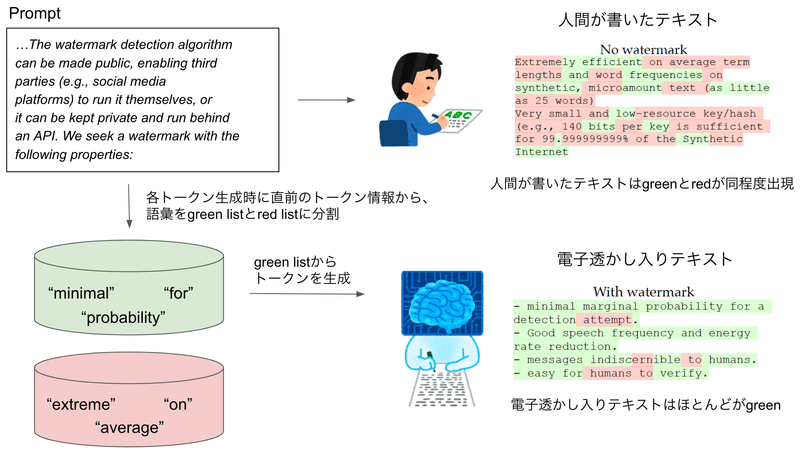
これまでの入力から次の単語を生成する際に、候補とする単語リスト(green list)と候補としない単語リスト(red list)に分割して、green listから生成するように促す。
電子透かし入りテキストはgreenばかりになり、人間が書いたテキストはgreen listやred listなど認知していないので、確率的に同程度のgreenとredの単語が出現する。
green が多い → 電子透かし入り と判断できる。
※ 論文の詳細は、論文メモの記事をあげていますので、よろしければご覧ください。
(ビジネス事例)会議のサマリー自動生成、会議における様々な観点(法務的、コンプライアンス的など)のアドバイス
ミーティングマネジメントツール「TIMO Meeting」
会議前~会議後までのプロセスをデジタル化と一元管理を通じて「会議品質の向上、会議時間の削減」を実現するミーティングマネジメントツール。
会議運営の効率化
会議体の作成から事前の展開、議事録の作成まで一連のプロセスをデジタル化
全自動化された通知やリマインドがあるので、会議運営のサポートに最適
多言語に対応したAI文字起こしとAI要約によりにより、議事録作成の業務が大幅に軽減
アジェンダコントロール
サマリフォーマットを活用することで論点の抜け漏れをなくす
事前決裁することで、議論が不要なアジェンダを事前に完了し、議論が必要なアジェンダに時間を費やせる
簡単な操作で情報へのアクセス制限を実施
会議の質向上
事前にアジェンダを展開しコメントの機能を利用することで、デジタル上で根回し・意見収集が可能に
Todo管理を行うことで会議での決定事項を確実に実行へ
AIアドバイザリーにより様々な観点から論点の洗い出しが可能
AIアシスタント機能
添付資料を読み込んで会議体にあったテンプレート(決議・議論・報告)に沿ったサマリーを自動生成し、アジェンダの作成時間を削減。
AIアドバイザリー機能
添付資料やサマリーに対して、法務的な観点、コンプライアンス的な観点など、AIを活用することで内容を精査し、アドバイスが受けられる。
(ビジネス事例)不良画像生成AI
不良画像生成AIは、手元にあるワーク(金属、ネジ、食品、カプセル、錠剤)の画像から不良画像が簡単に作成できるツール。
AIを用いて外観検査を自動化する際に、教師用データ或いはAIの精度検証用データとして不良画像が必要となるが、そもそも不良品が少なく不良画像が足りない、過去の不良画像を収集するのに手間がかかるといった課題。
不良の種類を選択して、元画像に対して不良をAIで生成させた不良画像を簡単に作成可能。

お知らせ
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。
この記事が気に入ったらサポートをしてみませんか?