
OpenAIの動画生成AI Sora, Gemini 1.5, etc - Generative AI 情報共有会 #14

今週、2月20日(火)にZENKIGEN社内で実施の「Generative AI最新情報共有会」でピックアップした生成AI関連の情報を共有します。
この連載の背景や方向性に関しては 第一回の記事 をご覧ください。
OpenAI、動画生成AIモデル「Sora」発表(2024/02/16)
ユーザーのプロンプトに忠実に従い、高品質の動画を生成可能(1分の長さを生成可能)な動画生成モデル「Sora」を発表。
ユーザーのプロンプトに忠実に従い、高品質な動画
OpenAIのサイト にSoraに生成させた様々な動画が共有されている。
下記Promptに対するSoraによる生成動画 : https://cdn.openai.com/sora/videos/tokyo-walk.mp4
Prompt :
“A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.”(「暖かく光るネオンとアニメーションの街の看板で埋め尽くされた東京の通りを歩くスタイリッシュな女性。黒いレザージャケットに赤いロングドレス、黒いブーツを履き、黒い財布を持っている。サングラスに赤い口紅。彼女は自信に満ち、さりげなく歩いている。通りは湿っていて反射し、色とりどりのライトの鏡のような効果を生み出している。多くの歩行者が歩いている。」)
下記Promptに対するSoraによる生成動画 : https://cdn.openai.com/sora/videos/tokyo-in-the-snow.mp4
Prompt :
“Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes.”(「雪の降る美しい東京の街が賑わっている。美しい雪景色を楽しみ、近くの屋台で買い物をする何人かの人々を追いながら、カメラは賑やかな街の通りを移動する。華やかな桜の花びらが雪の結晶と一緒に風に舞っている。」)
下記Promptに対するSoraによる生成動画 : https://cdn.openai.com/sora/videos/train-window.mp4
Prompt :
“Reflections in the window of a train traveling through the Tokyo suburbs.”(「東京郊外を走る電車の窓に映る風景。」)
Soraの弱点
現状の弱点も共有されている。
多くの実体が存在する場面で、動物や人が不自然に突然現れるたり消えたりすることがある。
Soraが生成した動画 : https://cdn.openai.com/sora/videos/puppy-cloning.mp4
↑ オオカミが不自然に発生している。
Prompt :
Five gray wolf pups frolicking and chasing each other around a remote gravel road, surrounded by grass. The pups run and leap, chasing each other, and nipping at each other, playing.(「草に囲まれた人里離れた砂利道で、5頭のハイイロオオカミの子犬がじゃれ合い、追いかけっこをしている。仔オオカミたちは走ったり跳ねたり、追いかけっこをしたり、じゃれ合ったりして遊んでいる。」)
上記例で挙げた動画内でも、赤いロングスカートの女性の動画における左奥の人混みの足の数の不自然さや、雪の降る東京の動画における手を繋いで歩く人の前の左の人が突然消えたりなど不自然さはある。
不正確な物理モデリング。
Soraが生成した動画 : https://cdn.openai.com/sora/videos/basketball-explosion.mp4
↑ バスケットボールがバスケットゴールリングをすり抜けている。
Prompt :
“Basketball through hoop then explodes.”(「バスケットボールがフープを通過し、爆発する。」)
不正確な物理的相互作用。
Soraが生成した動画 : https://cdn.openai.com/sora/videos/chair-archaeology.mp4
↑ 人が物を持つ様子の不自然さや、椅子が空中浮遊してしまう様子など。
Prompt :
“Archeologists discover a generic plastic chair in the desert, excavating and dusting it with great care.”(「考古学者が砂漠で一般的なプラスチック製の椅子を発見し、細心の注意を払って発掘し、埃を払った。」)
上記以外にも、文字の描画は苦手そう(「赤いロングスカートの女性の動画」や「雪の降る東京の動画」の看板を見るとよくわかる)など、高品質で非常に驚かされるが、課題もまだまだある様子。
安全性への対策
OpenAI Red Teamが敵対的にモデルをテスト(捏造、憎悪的、偏見などに関連するコンテンツの生成対策実施)。
動画がSoraによって生成されたかを判別する検出分類器など、誤解を招くコンテンツの検出に役立つツールを構築中。C2PA規格を利用し、OpenAIのモデルが生成したことを判別できるメタデータを埋め込む予定。
出版社や企業などがメディアの出所や関連情報を検証するためのメタデータを埋め込むことを可能にするオープンな技術標準(AIの生成物に限らない、出所や履歴を証明するための規格)。
C2PAメタデータは削除される可能性がある(今日のほとんどのSNSでは、アップロードされた画像からメタデータが削除される)。メタデータがない画像はAIで生成した画像か否か判断できない。
画像生成AI DALL·E 3のために構築した安全手法の適用。
暴力的、アダルト、憎悪的なコンテンツを生成する能力を制限。
公人の名前を含む生成リクエストを拒否する対策。
存命のアーティストのスタイルの生成リクエストを拒否する対策。
など
Soraの技術
テクニカルレポートが公開されている(詳細割愛)。
あらゆる種類のビジュアルデータを生成モデルでの大規模学習を可能にする統一的な表現に変換する手法と、Soraの能力と限界の定性評価。
モデルと実装の詳細は非公開。
[モデル]
Soraは拡散モデルであり、入力されたノイズの多いパッチ(とテキストプロンプトのような条件付け情報)が与えられると、元の「きれいな」パッチを予測するように学習される。
Soraは diffusion transformer であり、transformer(言語モデル、コンピュータビジョン、画像生成など様々な領域で成功している)のスケーリング特性を有効に活用したモデルとなっている。

[データ]
text2videoモデルの学習データ(動画とそれに紐づくテキストキャプション)として、DALL·E 3で導入したリキャプション技術を動画に適用。動画に対して高度なキャプションを生成するモデルを学習し、そのモデル利用してtext2videoモデル用の学習セットの全ての動画に対してテキストキャプションを生成。
DALL·E 3と同様、GPTを活用して、ユーザーからの短いプロンプトに対しより長く詳細なキャプションに変換し、動画生成モデルに渡す。
Soraの能力
[テキスト以外の入力に対する能力]
Soraはプロンプトとして、テキストだけでなく、画像を入力して動画にすることや、動画を入力して動画の前後を拡張したりスタイルや環境を編集することも可能。
OpenAIのテクニカルレポートの「Prompting with images and videos」に、画像の動画への変換や、動画の拡張、動画のスタイル変更、2つの動画を接続し1つの動画内に反映する、といった能力のデモが共有されている。
[3次元の一貫性]
3次元の一貫性があり、ダイナミックなカメラモーションを持つ動画を、一貫性を保ったまま生成することができる。
雪景色の中に桜が咲く東京をダイナミックなカメラモーションで映す、Soraの生成動画 : https://cdn.openai.com/tmp/s/simulation_0.mp4
[時間的一貫性」
人や動物や物体がフレームから外れてまた戻ってきた際にその存在を維持することができる。
犬が一度人の影に隠れるが再度現れた際に同じ犬として一貫性を保って存在している、Soraの生成動画 : https://cdn.openai.com/tmp/s/simulation_2.mp4
[世界とのインタラクション]
ある行動により世界がどのように影響を受けるかをシミュレートすることができる。
ハンバーガーをかじったら、ハンバーガーに噛み跡がつく、Soraの生成動画 : https://cdn.openai.com/tmp/s/simulation_5.mp4
[デジタル世界のシミュレーション]
Minecraftの世界を忠実にレンダリングできる。https://cdn.openai.com/tmp/s/simulation_7.mp4
物理的・デジタル的世界と、その中で生きる物体、動物、人間の高度な能力を持つシミュレーターの開発に向けた有望な道であることを示唆している(と述べられている)。
一方、現状はまだ多くの課題があり、例えば、ガラスが割れるような基本的な物理現象を正確にモデル化できていない。https://cdn.openai.com/tmp/s/discussion_0.mp4
Soraへのアクセス
現在は以下の一部の人々へのアクセス。
OpenAI Red Team
OpenAIのモデルに関して、攻撃者側の視点に立ってリスクを調査するチーム。
映像制作に関わる専門家(ビジュアルアーティスト、デザイナー、映画制作者)
クリエイティブな専門家にとって最も役立つようにモデルを改良するためのフィードバックを得る目的。
Google、Gemini 1.5発表(2024/02/15)
Gemini 1.5の最初のモデルとして、Gemini 1.5 Proを発表。
Gemini 1.0 Ultraと同等のパフォーマンスを発揮しながら、最大100万(1000K, 1M)トークンの長いコンテキスト長で実行可能。
1時間のビデオ、11時間のオーディオ、30,000行以上のコードベース、70万語以上の単語など、膨大な量の情報を一度に処理することが可能。研究段階だが、最大1,000万トークンのテストにも成功している。
Gemini 1.5はTransformerとMoEアーキテクチャ。与えられた入力のタイプに応じて、ニューラルネットワークの中で最も関連性の高いエキスパート経路のみを選択的に活性化するように学習。
Gemini 1.5 Proの能力
Gemini 1.5 Proの長いコンテキストを扱える能力のデモが公開されている。
[膨大なテキスト情報に対する複雑な推論]
402ページ(約330Kトークン)に及ぶアポロ11号の記録のドキュメントPDFを読み込ませ、内容についていくつかの質問をしているデモ。
応答までの時間は数十秒程度。
[モーダルを跨いだ高度な理解と推論]
44分の動画(バスター・キートンの無声映画)を入力し、「人のポケットから紙が取り出された瞬間を見つけて、タイムコードとともに、その紙に関する重要な情報を教えてください。」という質問をすると実際に動画内で人のポケットから紙が取り出される映像部分のタイムスタンプと共にその紙に書かれた内容を説明している。
また、あるシーンを手書きの絵で描いた画像を入力してそのシーンのタイムスタンプを要求すると、正しくタイムスタンプを返している。
応答までの時間は1分程度。
[長いコードブロックに対する問題解決]
100,000行を超えるコードを含むプロンプトに対し、様々な推論や、役立つ修正提案、説明を与えることができる。
応答までの時間は「実験用に最適化された環境で」60秒程度と述べられている。
Technical Report
Technical Report からいくつかの報告をピックアップ。
[Gemini 1.0ファミリーとの比較]
Text, Vidion, Audioのさまざまなベンチマークでの、Gemini 1.0ファミリーとの性能比較。
1.0 Ultraと比較し1.5 Proはトレーニングに使用する計算量が大幅に少なく、処理効率が大幅に高いにも関わらず、1.0 Ultraと同等の性能を達成しているとしている。
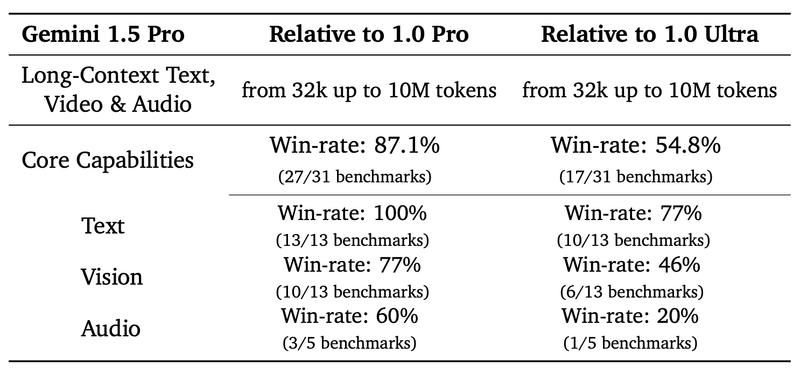
[needle-in-a-haystack評価]
長いコンテキスト長の検索性能を測る評価手法。
text:
長いドキュメント中のどこかにランダムに1文(本レポートでは、”The special magic {city} number is: {number}" )を挿入し、モデルにその1文を見つけられるか(本レポートでは、 “Here is the magic number:” と尋ねて正しく数字を当てられるか)を評価する。
以下が、Gemini 1.5 ProとGPT-4 Turboの比較。
GPT-4 Turboは128Kまでしか検索できないが、Gemini 1.5Proは1Mまでで99.7%の成功率。10Mまででも99.2%の成功率。
緑色のセル : モデルがmagic numberの検索に成功したことを示す。灰色のセル : APIエラー。赤色のセル : モデルの応答にmagic numberが含まれていなかったことを示す。
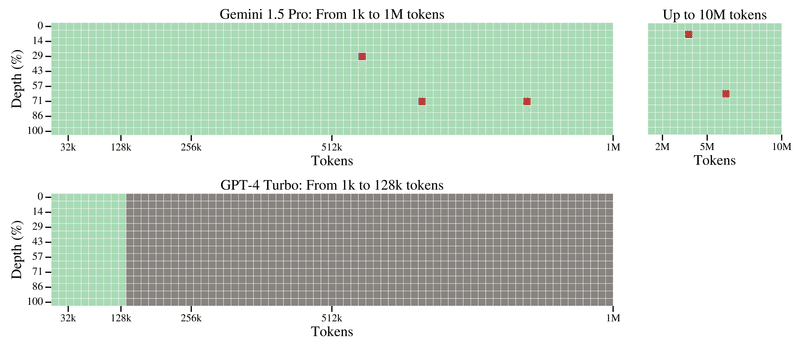
video:
以下のように、長い動画内の1フレーム(1秒間)にテキストを挿入(本レポートでは、”The secret word is "needle””)し、モデルにそのテキストを見つけられるか(本レポートでは、”What is the secret word?” と質問して答えられるか)を評価する。

以下が、Gemini 1.5 ProとGPT-4Vの比較。
GPT-4 Turboは最初の3分までしか検索できないが、Gemini 1.5Proは1時間動画内全てで適切に検索できている。追加の実験で、3時間まで検索できた。
緑色のセル : モデルが検索に成功したことを示す。灰色のセル : APIエラー。赤色のセル : モデルが検索に失敗したことを示す(図ではなし)。
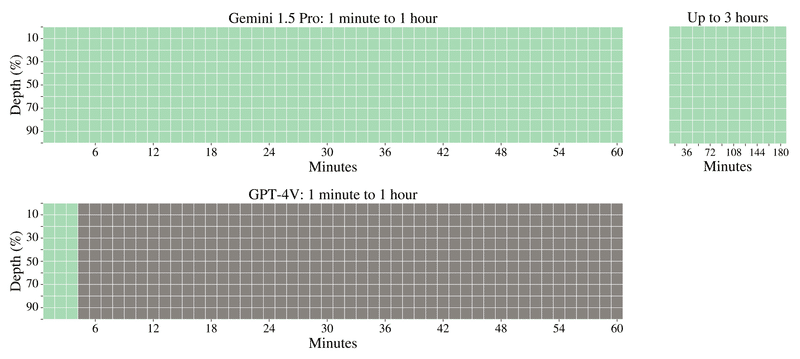
audio:
長い音声の中に1発話(本レポートでは、”The secret word is "needle””)を音声のどこかに挿入し、モデルにその発話を見つけられるか(本レポートでは、”What is the secret word?” と質問して答えられるか)を評価する。
以下が、Gemini 1.5 ProとWhisper + GPT-4 Turboの比較。
Whisper + GPT-4 Turboは94.5%の精度。Gemini 1.5 Proは11時間の音声内に対し100%適切に検索できている。追加の実験で、22時間まで100%検索できた。
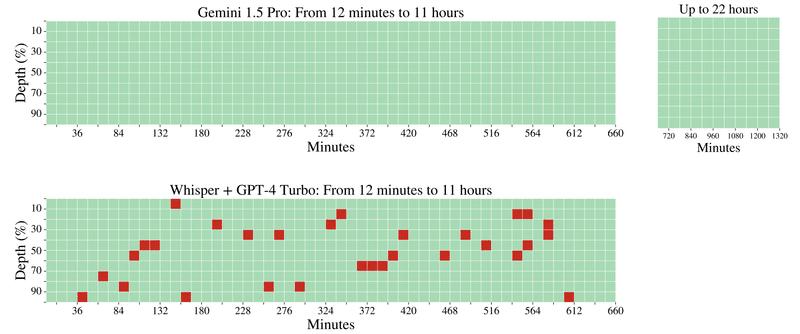
緑色のセル : モデルが検索に成功したことを示す。灰色のセル : APIエラー。赤色のセル : モデルが検索に失敗したことを示す(図ではなし)。
また、既存モデルはGemini 1.5 Proのように音声をそのまま処理できないため、Whisper + GPT-4 Turbo(Whisperで30秒ごとに書き起こしをし、GPT-4 Turboに入力、発話を検索させる)との比較という形をとっている。
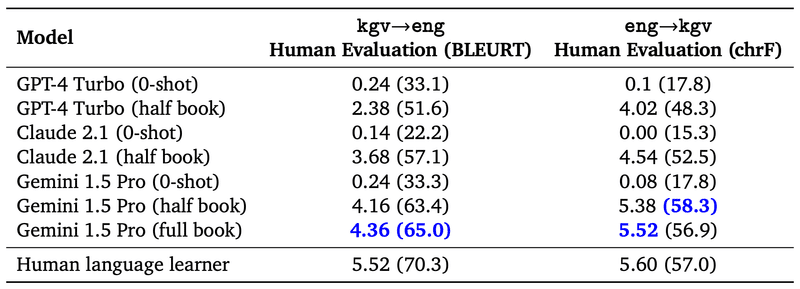
[In-Context学習能力 : 1冊の本から新しい言語の翻訳能力を獲得]
カラマン語という世界に話者が200人未満の言語(Web上にほとんど存在しない)に対し、その文法(500ページ)、対訳単語リスト(2000項目)、並列文集合(400対)からなる言語学文書のみを用いてカラマン語の能力をどの程度獲得できるか評価。
以下が、評価結果。
0-shot(カラマン語のマニュアルを事前に何も見ていない設定)では、GPT-4 Turbo, Claude 2.1, Gemini 1.5 Pro全てほぼ精度が出ておらず事前には能力を獲得していない。
half book(カラマン語のマニュアルを半分読み込ませた設定。GPT-4 TurboとCalude 2.1はコンテキストサイズ的にマニュアル全文を読み込ませることができないため)の設定で、Gemini 1.5 Proが最も翻訳精度が高い。
Gemini 1.5 Proはさらに全文(full book)を読み込ませることでさらに精度が向上。
[長いコンテキストの音声認識精度]

Gemini 1.5 Proへのアクセス
限定プレビューをAI StudioとVertex AIを通じて開発者と企業に提供。
標準的な128,000トークンコンテキストウィンドウを持つ1.5 Proは準備が整い次第リリース予定。
100万トークンまでスケールアップする価格階層を導入予定。
(関連)Gemini Ultra 1.0モデルにアクセスできるGemini Advancedを発表(2024/02/08)
Gemini Ultraは以前共有会で紹介した、Geminiの最も高性能(当時)なモデル。様々なベンチマークでGPT-4を上回る性能を報告していた。
現在は英語のみ日本からも利用可能。
Google Oneの有料プランの提供機能として(2TBのストレージなど既存のGoogle Oneの有料プランの特典に加えて)提供。月額19.99ドル。
スマートフォンからの利用も可能に。
様々な日本語LLM
Deepreneur、ChatGPT-3.5を上回る日本語LLM「blue-lizard」発表(2024/02/13)
松尾研発のAIスタートアップDeepreneurが、Llama 2-7Bをベースとして、Wikipediaや書籍等の日本語の学習データを用いて追加事前学習と独自データによるファインチューニングを実施したモデル「blue-lizard」を公開。
7BモデルでChatGPT-3.5を上回る性能。
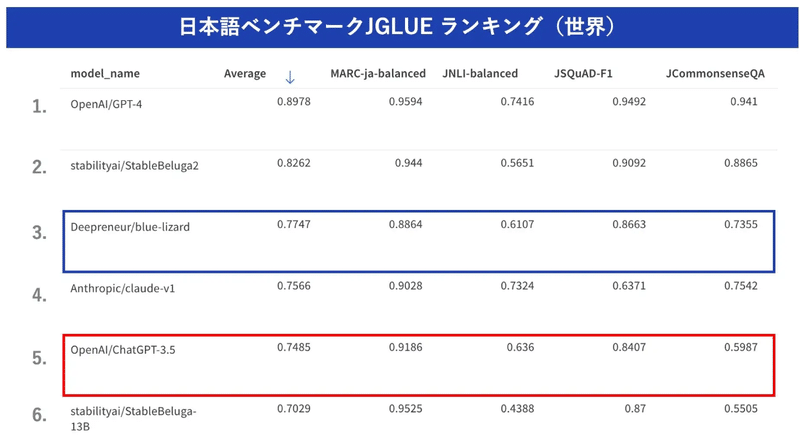
ライセンスは、LLAMA 2 Community License に準拠しており、Acceptable Use Policy に従う限りにおいては、研究および商業目的での利用が可能。
「blue-lizard」とその開発で得たノウハウ・知見を活用し、各社独自のLLMの構築のサービスを開始。
リコー、日本語精度が高い130億パラメータの大規模言語モデル(LLM)を開発(2024/01/31)
リコーは、Llama 2-13Bをベースに、企業ごとのカスタマイズを容易に行える13BパラメータのLLMを開発。
「AWS™ LLM開発支援プログラム」を活用した成果。
公開されている日本語LLMのうち13Bパラメータかつトークナイザを日本語適応している事前学習モデルとのベンチマーク(llm-jp-eval)比較で、2024年1月4日現在で最も優れた結果を確認。
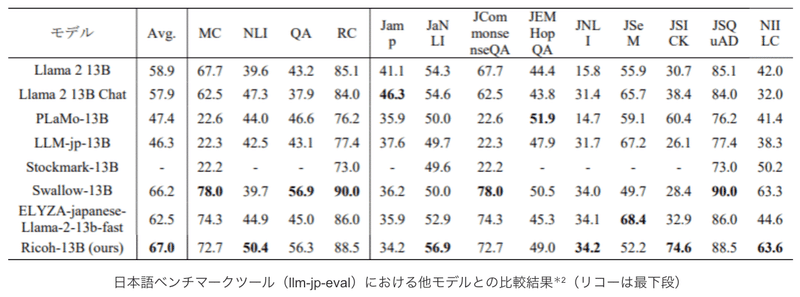
学習上の工夫を実施(詳細は不明。NLP2024にて論文発表予定とのこと)。
学習に利用するコーパスの選定
誤記や重複の修正などのデータクレンジング
学習データの順序や割合を最適化するカリキュラム学習
2024年春から、カスタムLLMをクラウド環境でお客様へ提供開始。
学習能力が高い本LLMに企業独自の情報や知識を取り入れることで、お客様ごとの業種・業務に合わせた高精度なAIモデル(カスタムLLM)を、短期間で容易に構築することが可能になるとのこと。
カラクリ、700億パラメーターLLM「KARAKURI LM」を一般公開(2024/01/31)
カスタマーサポートDXを推進するカラクリは、Llama 2-70Bをベースにし、日本語の語彙を追加して日本語と多言語コーパスを混ぜて追加の事前学習を行なったLLM「KARAKURI LM」を公開。
また、公開されている会話データセットと独自で開発した非公開の会話データセットを混ぜてファインチューニングしたモデル「KARAKURI LM Chat」を公開。
「AWS™ LLM開発支援プログラム」を活用した成果。
KARAKURI LM Chatは、MT-Bench-jpベンチマークで日本語オープンモデルの中で最高性能を記録。
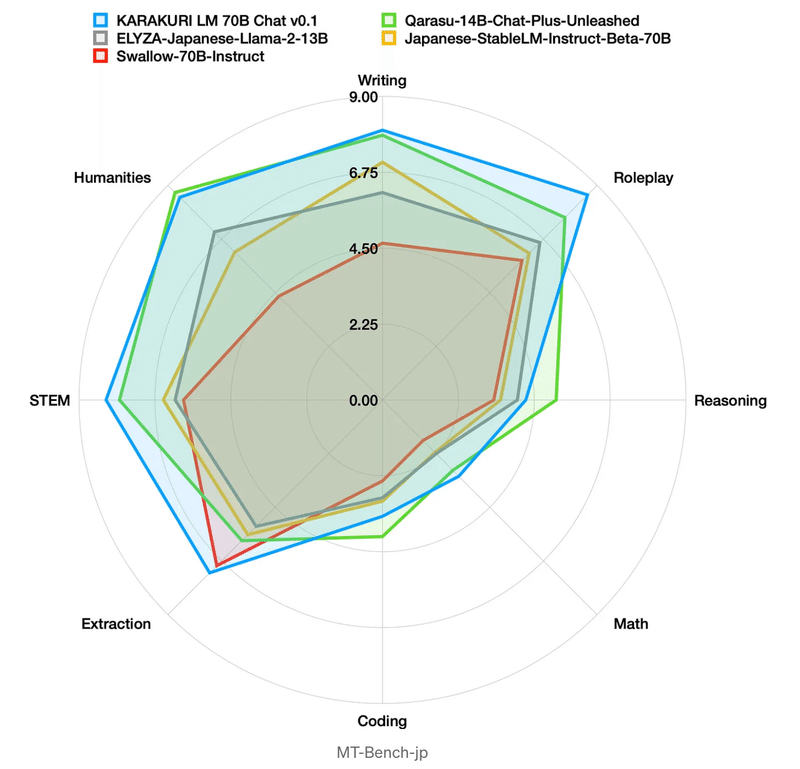
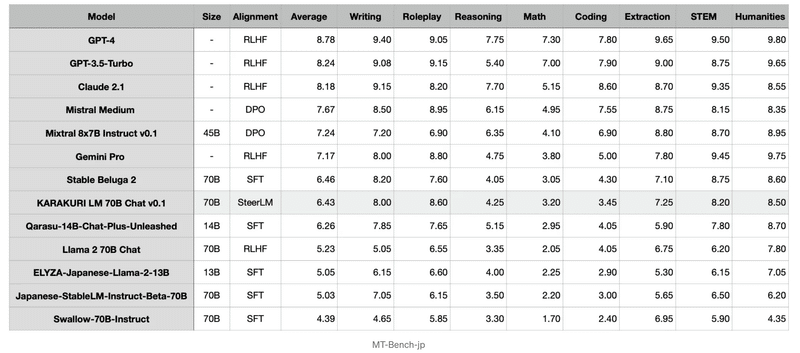
工夫
継続事前学習
公開されているmC4やRedPajamaといったコーパスに加え、独自に収集した日本語コーパスを使用(16Bトークン)。
追加する語彙には、常用漢字以外のマイナーな漢字や絵文字などが含まれないようにフィルタリング。
ファンチューニング
訓練データとして、OASST2と独自に構築した会話データセットを使用(約36Mトークン。日本語は2.5%。)。
独自に構築したデータセットは約1000件の会話。
日本語のトークン数が少ないため、破滅的忘却を防ぐために、継続学習のアプローチを採用。
継続事前学習の際に用意したデータセットの中からまだ学習させていないものを使用し、事前学習タスクも同時に解かせるマルチタスク学習を実施。
ファインチューニングには、SFTやRLHFではなく、SteerLMを使用。
教師あり学習の枠組みで学習できるため、強化学習よりも実装が容易で学習が安定。
SteerLMの属性予測モデルにはSwallow 13Bを使用し、OASST2とHelpSteerを学習させた。
この記事が気に入ったらサポートをしてみませんか?