
言語処理学会第30回年次大会(NLP2024)参加報告

こんにちは。ZENKIGENの栗原です。現在、データサイエンスチームにおいて、自然言語処理周りの研究開発に携わっています。
今回は、2024年3月11日(月)~3月15日(金)に神戸国際会議場で開催された、言語処理学会第30回年次大会(NLP2024)に参加してきたので、その参加報告をいたします。
ZENKIGENは、録画選考システム『harutaka EF(エントリーファインダー)』や面接解析システム『harutaka IA(インタビューアセスメント)』などを展開し、人のコミュニケーションの分析に力を入れています。
そういった中で参加したNLP2024において、私が特に気になった発表を中心にまとめていきたいと思います。
全体所感
今回参加して最も印象的だったのは、やはり大規模言語モデル(LLM)に関連する発表の多さです。
NLP2024のプログラムを見ると、チュートリアルの「作って学ぶ日本語大規模言語モデル」(大変勉強になりました。)から始まり、"LLM"というワードが入ったセクションが7つ(NLP2023 はゼロ)、"LLM"もしくは"大規模言語モデル"とタイトルに入った発表が106件(NLP2023 は10件)でした。
大別すると、
これまでルールベースや教師あり機械学習ベースの手法が主流だったタスクやシステムに、LLMを活用する手法。
LLM構築や精度向上のためのデータ整備。
LLMの評価用データやタスクの整備。
LLMの挙動の分析。
といった形で、タイトルに言及がなくともChatGPTをはじめとするLLMを検証等に利用している発表も数多くありました。
来年の言語処理学会でもこの流れは続くのではないかと思いますが、使用モデルの変遷や産学の連携によってより社会実装が進んだ発表などが見られることを楽しみにしたいなと思います(私も頑張りたい)。
ここからは、私が特に興味を持った発表を中心に紹介したいと思います。
ZENKIGENに関連がありそうな発表(対話系)と、その他発表としていくつか挙げたいと思います。
ZENKIGENとして興味深かった発表
評価の階層性に着目した雑談対話システム評価の分析
○蔦侑磨, 吉永直樹 (東大)
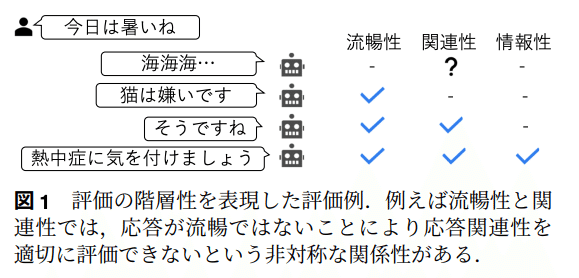
対話の評価は目的により様々な観点があり、ある観点は別の観点に依存することがある(ex. 発話の"流暢性"で評価が低いとより内容に踏み込んだ"関連性"は正しく評価できない)。
評価軸間の依存関係(階層性)を可視化と、依存関係を解消する方法の検討。
(コメント)ZENKIGENでも、面接などの対話をどのように定量評価するかで様々な観点を検討していますが、それぞれの観点がどう依存するのか、そして依存関係を解消した上で評価するのかは我々も検討していく必要があると感じ、大変興味深かったです。
ロボット対話によるインタラクティブ観光プランニング
○佐藤京也 (SB Intuitions/都立大), 大萩雅也, 山崎天, 水本智也, 吉川克正 (SB Intuitions)
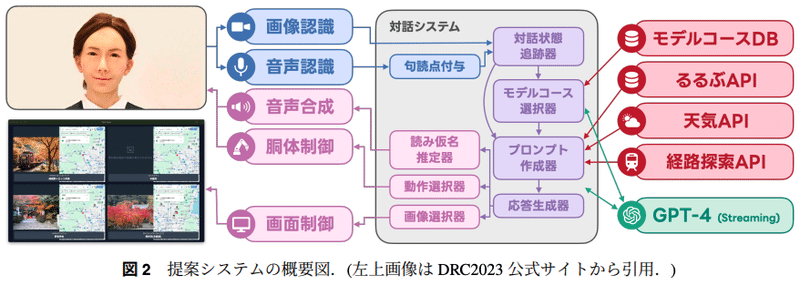
対話ロボットコンペティション2023(カウンターセールスによる観光案内タスク)の最優秀賞システム詳細の発表。
応答速度向上の方法(本発表ではStreaming APIを使用しての句読点位置でTTSに送信する方法でしたが、B9-5 音声対話における応答速度改善に向けた先読み技術の検討 のユーザー発話を予測し事前に応答を生成しておくアプローチも興味深かったです)や、フェイズ遷移方法として"[END]"という終端記号を利用する方法、音声入出力における読み間違いへの対処方法など様々な工夫が紹介されている。
(コメント)タスク指向型の対話システムの検討はZENKIGENとしても注目しており、その中で我々としても課題感を感じている応答速度向上や音声発話時の読み間違いへの対処などに対する取り組みをお聴きでき大変参考になりました。
語りに傾聴を示す応答タイミングの検出のためのテキストデータの利用
○渡邉優, 伊藤滉一朗, 松原茂樹 (名大)
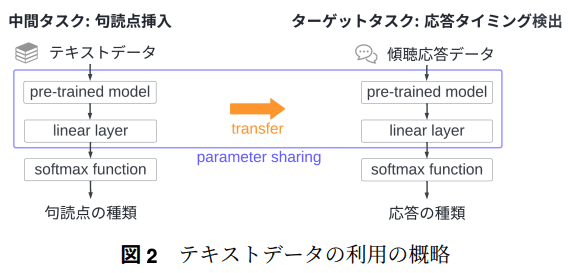
傾聴応答は適切なタイミングでされる必要があり、どのタイミングでされると良いかの検証。
傾聴応答タイミングは句読点の位置とある程度一致するという事前調査をもとに、一般的なテキストデータの句読点位置検出タスクを中間タスクとすることで、傾聴応答タイミング検出タスクの精度向上ができないかの検討。
学習データ数が少ない設定で中間タスクでの学習は有効であることを確認。
(コメント)対話システムを検討する上で、ユーザーの発話に対して人間らしく応答する上で傾聴応答はZENKIGENとしても非常に重要な要素だと考えています。今回「傾聴」に関連する発表はこれ以外にも以下のものがあり、どれも大変興味深く聴かせていただきました。
強化学習を用いた傾聴対話モデルの構築
○松本奈々, 安藤一秋 (香川大)
語りの傾聴における補完応答の生成のための話し手の発話の予測
○海野博揮 (名大), 大野誠寛 (東京電機大), 伊藤滉一朗, 松原茂樹 (名大)
その他興味深かった発表
逆学習による言語モデルの解析
○磯沼大 (エディンバラ大/東大), Ivan Titov (エディンバラ大)
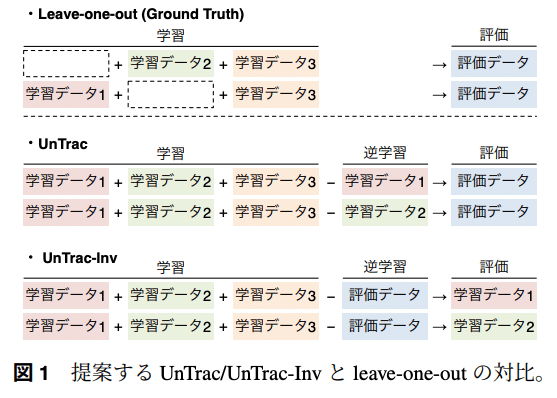
大規模言語モデルの出力に対する各学習データの影響を推定する上で、学習データの忘却方法として注目されているMachine Unlearning(逆学習)手法を応用し、既存手法と比較し低コストで効果的に推定可能な提案。
理論的に、提案手法は既存手法の一般化と見做せることも示す。
(コメント)評価データで逆学習し影響を調査したい学習データで評価するアイディアは大変興味深く、実務で活用していく上でも非常に参考になる発表でした。
制約が異なる指示で生成された文章に対する LLM 生成検出の頑健性
○小池隆斗 (東工大), 金子正弘 (MBZUAI/東工大), 岡崎直観 (東工大)
文がLLMによって生成されたものか、人間が書いたものかを検出するタスクにおいて、指示文(プロンプト)中の制約(ex. 生成文のフォーマット指定, 文長指定など)が検出器にどの程度影響を与えるのか検証。
語彙やスタイルを指定する制約下で影響(検出性能のブレ)は大きく、指示に従う能力が高いLLMほどその影響度を増幅させる。
(コメント)LLM文検出器は現在の生成AI隆盛の中で様々な面で必要となる技術で、関心を持っています。指示文中の制約に焦点を当てた研究としてとても興味深かったです。
LLMの出力結果に対する人間による評価分析とGPT-4による自動評価との比較分析
○関根聡 (理研), 小島淳嗣, 貞光九月, 北岸郁雄 (マネーフォーワード)
インストラクションデータ(ichikara-instruction)を作成するプロジェクトにおける、インストラクションデータでSFTを行ったモデルに対する出力の人間評価とGPT-4による評価の比較分析を行なった発表。
GPT-4は出力の正確性が判断できず、具体的で情報量が多い(が不正確な)出力を高い評価とする不適切な評価を行うことを確認。
(コメント)LLMの出力の評価についても関心を持っており、GPT-4で評価を行なっている研究は数多くありますが、それに対する違和感(不信感?)的なものを感じることは多く、本発表も興味深く拝見しました。また、ichikara-instructionのプロジェクト自体も大変興味深く、これ以外にも日本語のLLM関連のデータ整備やそのプロセスが共有される環境が作られていっていることが大変ありがたく、勉強させていただいています。
ここで挙げさせていただいた発表以外にも非常に多くの興味深い発表がありました。
来年の言語処理学会も非常に楽しみです。
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。
この記事が気に入ったらサポートをしてみませんか?