embulk-filter-maskを使ったデータ分析基盤構築のお話

こんにちは。TECH::CAMPを運営する株式会社divにて、開発チームのマネージャーをしている片岡(@mato_kata)といいます。
div inc.(TECH::CAMP) Advent Calendar 2018の2日目の記事として、私が中心となって開発・運用を行っている弊社のデータ分析基盤で、安全にデータを扱うために利用したembulk-filter-maskについてご紹介します。
安全にデータを扱うとは?
「安全」といってもいろいろな視点がありますが、まずはデータ分析基盤に個人情報を含まないようにすることで、個人情報の漏洩を意識しなくても使えるようにすることを「安全」と考えました。
また、データコピー(ETL)のためにEmbulkを利用しました。そこで上記を実現するために、Embulkのプラグインであるembulk-filter-maskを利用して個人情報をマスクすることにしました。

構成
構成図にまとめると、以下のような環境になっています。
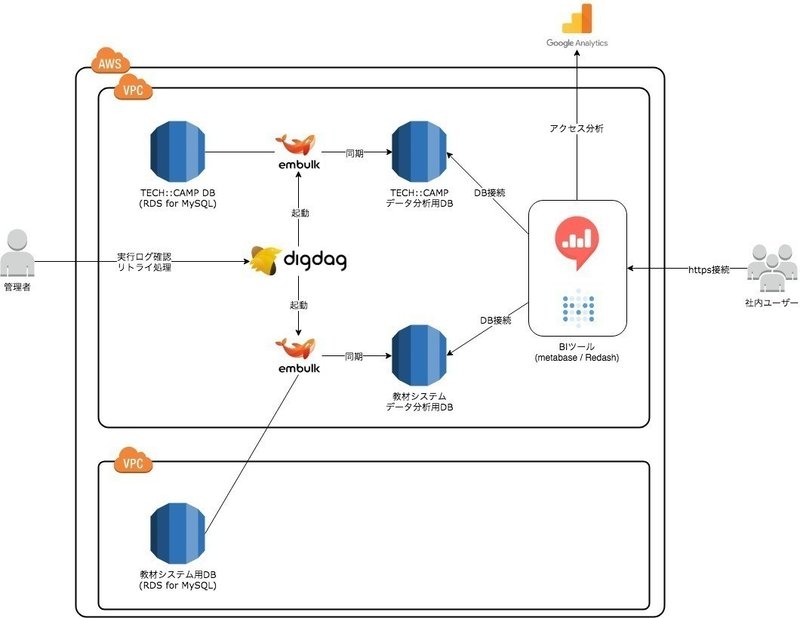
本番のデータベースから分析用データベースにコピー(=ETL)するためにEmbulkを利用し、それをワークフローエンジンdigdagを使って指定した時間にEmbulkを起動させてデータコピーを行っています。
そしてユーザがデータを見るのに使うBIツールとして、metabaseやRedashを利用しています。
データ分析用データベースは1つにしたかったのですが、本番データベースと大きく構成が変わるとサポートが難しくなり利用時のハードルが上がってしまうため、あえて本番と同様に2つに分けました。(これは今後改善予定です)
そしてデータを安全にするために、embulk-filter-maskをつかいました。
embulk-filter-maskについて
このプラグインを利用することで、データを書き込む前に指定したカラムのデータをマスクすることができます。
今回は例として、こういったカラムとデータを持ったデータベースのテーブルを分析用データベースにコピーしました。

まずembulkのインストールして動作するようにします。またコピー元・コピー先ともにMySQLのためembulk-mysql-input, embulk-mysql-outputを、そしてembulk-filter-maskをインストールします。なお、インストール方法は調べるといろいろ出てきますので割愛します。
これらを導入した後に、以下のような users.yml.liquid ファイルを作成します。
$ cat users.yml.liquid
in:
{% include 'commons/DB_include' %}
table: users
select: "*"
out:
{% include 'commons/analysisDB_include' %}
table: users
select: "*"
mode: merge
filters:
- type: mask
columns:
- { name: first_name }
- { name: first_name_kana }
- { name: email_address, type: substring, start: 5 }
- { name: phone_number, type: substring, start: 5, length: 6 }
- { name: address, type: substring, start: 4 }in:がインプットプラグインの設定、out:がアウトプットプラグインの設定です。
そしてfilters:で始まる設定がフィルタに関する設定で、今回のようにデータの加工をする場合の設定をいれます。
具体的にはname: でカラム名を、type: でマスクのタイプを、start: 何文字目からマスクするかを、length: で何文字マスクするかを指定します。なおマスクのタイプによってstartやlengthは使えないので注意しましょう。(詳細はgithubのReadmeを見てください)
また、データベース接続情報は使い回せるように、外部ファイル(以下の例では_DB_include.yml.liquidファイルと_DB_include.yml.liquidファイル)に切り出しておくと便利です。
本資料ではcommonsディレクトリ内に置いています。optionsは必要に応じて設定します。(catコマンドは中身表示のために使っているだけなので、ファイルは"#"で始まるようにしましょう)
$ cat commons/_DB_include.yml.liquid
#
type: mysql
user: (データベースユーザのアカウント名)
password: (データベースユーザのパスワード)
database: (本番データベースを指定)
host: (本番データベースのホスト名かFQDNを指定)
options: { useLegacyDatetimeCode: false, serverTimezone: UTC }
$ cat commons/_analysisDB_include.yml.liquid
#
type: mysql
user: (データベースユーザのアカウント名)
password: (データベスユーザのパスワード)
database: (分析用データベースを指定)
host: (分析用データベースのホスト名かFQDNを指定)
options: { useLegacyDatetimeCode: false, serverTimezone: UTC }なお設定ファイル内では "commons/DB_include" のように .yml.liquid は不要なのですが、commonsディレクトリ内に置くファイルの先頭は"_"で始まることと、.yml.liquid をつける必要があります。
こうした設定ファイルを作成してから、embulkを実行します。
$ embulk preview users.yml.liquidもしin: やfilter: でエラーがあったらこの時に分かります。エラーがなかったら以下を実行します。
$ embulk run users.yml.liquidこの後でデータ分析基盤にコピーしたテーブル(usersテーブル)を見ると、以下のようになっています。

このように個人情報がマスクされてコピーが行われました。
まとめ
非常に駆け足で説明となってしましましたが、いかがだったでしょうか?
データ分析基盤は非エンジニアが使いこなしてこそビジネス速度が上がり、活きるものと考えています。そこでエンジニアはエンジニアしか使えないものではなく、例えばこういった方法で多くの人が使える環境を目指すというのはいかがでしょうか?
次回は、非エンジニアの方が自走して運用できるように行ったことをご紹介したいと思います。
この記事が気に入ったらサポートをしてみませんか?