
GoogleのオープンソースLLMのGemmaのGoogle Colabでの使い方

GoogleがオープンソースのLLMのGemmaという70億の言語モデルを出してきました。Gemminiとどのようにブランディング効果を狙っていくのかは気になるところです。
今回は、Google ColabでのGemmaの使い方を紹介します。
まずは、Hugging Faceのところで、Gemmaにアクセスするための許可を取ります。
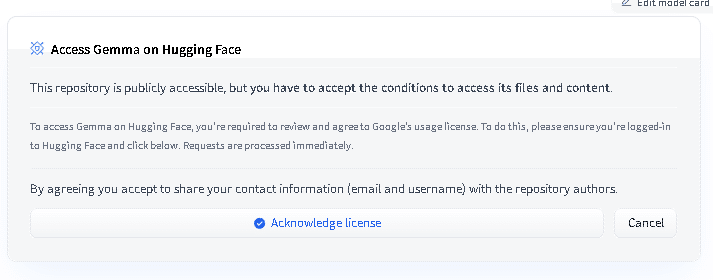
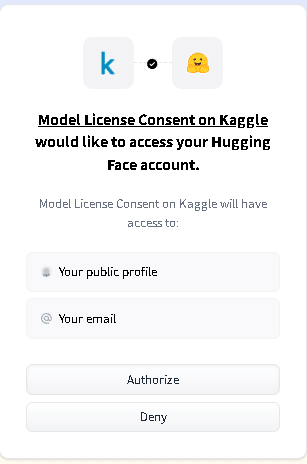
すると、Google Gemma Access Request画面が出てきますので、下に行きます。


!pip install huggingface-cli
!huggingface-cli login下記のようにToken:を入力するところが出力されますので、https://huggingface.co/settings/tokensからアクセストークンを取得して入力します。
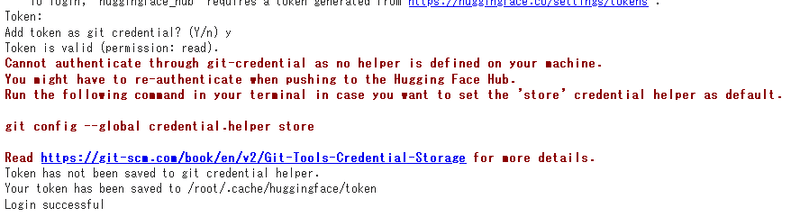
次に、以下を実行します。
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
I’m not a poet, but I’
短い文章ですね。input_textのところ変えて聞いてみます。
input_text = "What is a cherry blossom?"
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))A cherry blossom is a flower of the cherry tree. The
途中で切れてしまいますね。次は日本語が出来るか試してみます。
input_text = "日本の良いところはどこですか?"
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))I'm not sure if this is a good question,
日本語は出来ないようですね。70億パラメータの限界ということでしょうか。
input_text = "35 * 35 ="
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))<bos>35 * 35 = 1225
35 x 35
gemma-2bというのもありましたので、さらにパラメータ数の少ない場合はどうなるのかを、時間のある方は試してみるのが良いです。
この記事が気に入ったらサポートをしてみませんか?