
BardがGeminiになりました。

Googleは、BardとGeminiという2つのAIブランドを持っていました。GoogleからBardがGeminiになりましたというメールが来ましたので、アクセスしてみます。

こちらからアクセスします。


色々なところを試していきます。
Geminiで利用するデータは、デフォルトでは人間のレビューアーに見られるとのことです。但し、OpenAIと同じように機会学習のデータに取り込まれないようにする機能はあります。

Geminiの利用には、文字入力、画像、音声の3つが使えるようです。

文字入力の方から試してみます。


回答結果は、違和感なく出力されているように見えます。
それらの回答結果に対して、6つのアクションを取ることができます。
左から2つは、いいね、ダメねです。
左から3つ目は、回答を書き換えるです。

回答を書き換えるをクリックすると、5つの書き換え候補案が出てきます。試しに、カジュアルな表現にするを試してみます。


どういうふうに、カジュアルな表現を実現したかは気になりますが、AI Vtuberとかにシナリオを読ませるには最適な感じがします。
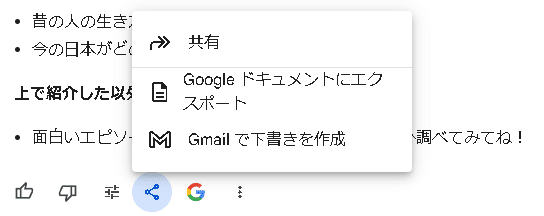
次に、左から4つ目の共有には、Googleドキュメントにエクスポートできるのと、Gmailで下書きを作成してもらうことができます。
左から5つめのGoogleマークは、出力結果の出どころを表示してくれます。


回答結果の部分をハイライト表示してくれて、ウェブから参照した情報を表示してくれています。
最後は、コピーと法的な問題を報告となります。
法的な問題を報告をクリックすると、フィードバック画面が新規に開きます。

他にも、画像について対話ができるので、ウサギの画像を例に実行してみます。



結構詳細に分析してくれています。また、最後の画像のファイル名、保存場所は違います。
この記事が気に入ったらサポートをしてみませんか?