
StarCoderというGithub Copilotに似た155億パラメータの言語モデルの使い方(コード付き)

HuggingfaceとServiceNowが開発したStarCoderを紹介していきます。このモデルは、80以上のプログラミング言語でトレーニングされて155億パラメータを持つ大規模言語モデルです。1兆トークンでトレーニングされております。コンテキストウィンドウが8192トークンです。
今回は、Google Colabでの実装方法とVisual Studio Codeでの実装方法を紹介していきます。
Google Colabでの実装方法は、ファイルのダウンロードなどに時間がかかるので、お勧めはVisual Studio Codeで実装して試してみるのが面白いです。
Google Colabでのstarcoderの使い方
Google Colabでのstarcoderの使い方は、Huggingfaceのページにあるコードを少し修正して使います。Google Colabを使うときは、GPUプレミアムのA100を使う必要があります。GPU標準V100だとクラッシュしてしまいました。
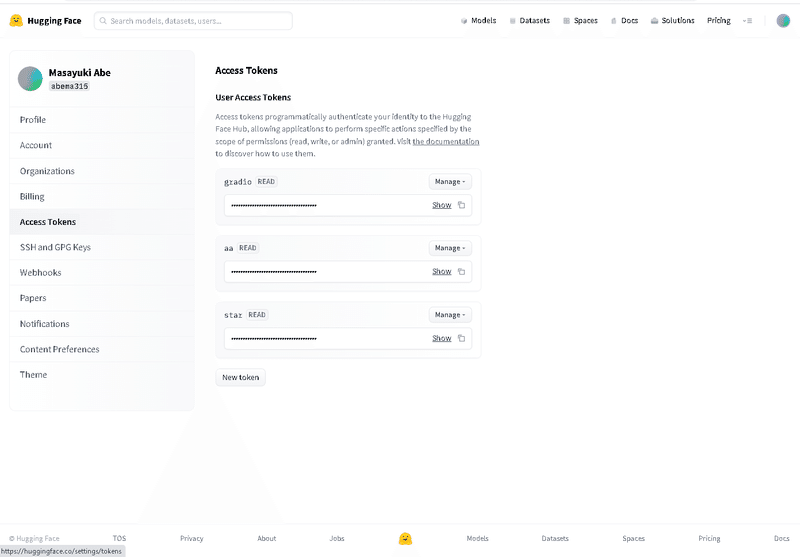
最初に、事前準備として、Huggingfaceのアクセストークンを取得しておきます。
次に、コードです。
!pip install -q transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "bigcode/starcoder"
device = "cuda" # for GPU usage or "cpu" for CPU usage
!pip install huggingface_hub --upgrade
from huggingface_hub import login
login()上記を実行すると、Huggingfaceのアクセストークンを入力する画面が出力されますので、先ほど取得したHuggingfaceのアクセストークンを入力します。
次に、下記コードを実行します。
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint, trust_remote_code=True).to(device)
inputs = tokenizer.encode("def print_hello_world():", return_tensors="pt").to(device)
outputs = model.generate(inputs)
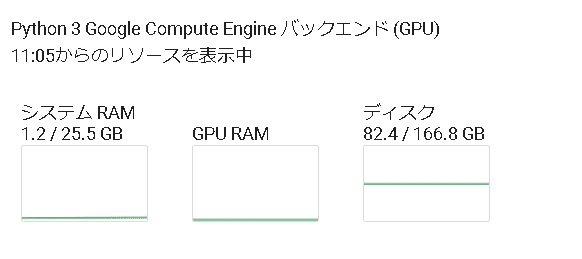
print(tokenizer.decode(outputs[0]))実行結果は、下記のRAMでしたが、システムクラッシュしてしまいましたのでうまくいきませんでした。GPUプレミアムが必要かと思います。
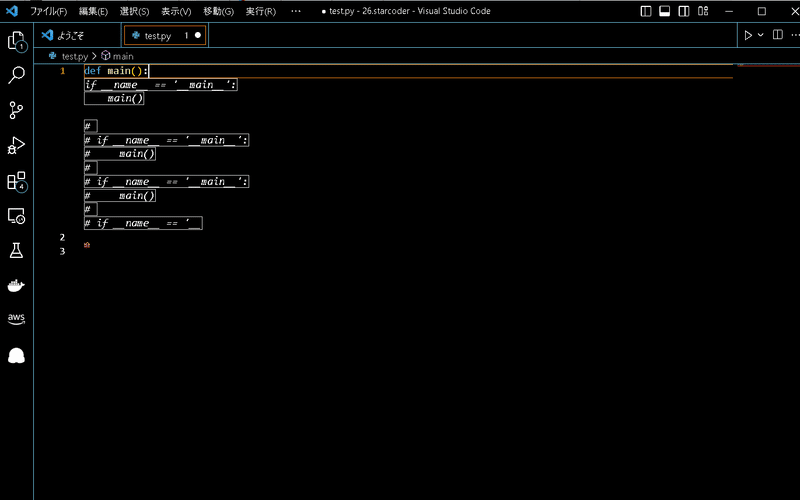
Visual Studio CodeでのStarCodeの使い方
Visual Studio Codeで使用するには、拡張機能として利用します。
下記のページを参考にインストールしていきます。
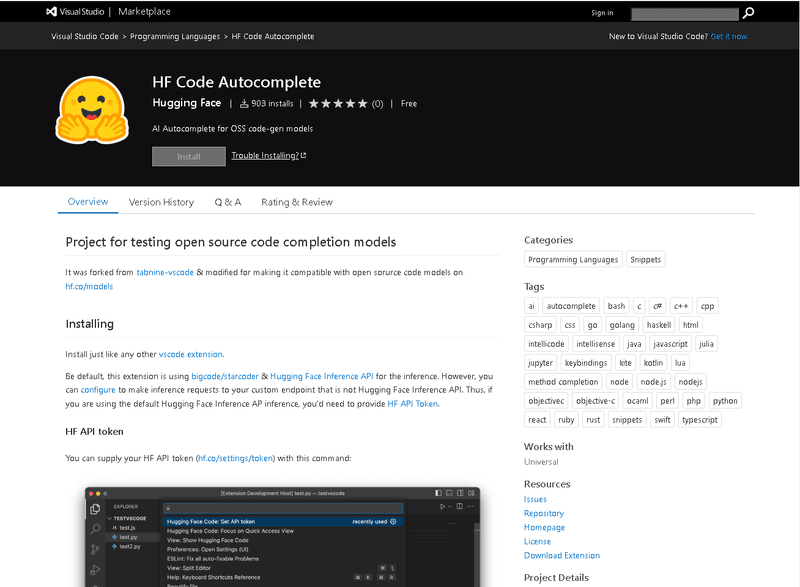
Visual Studio Codeが開きます。
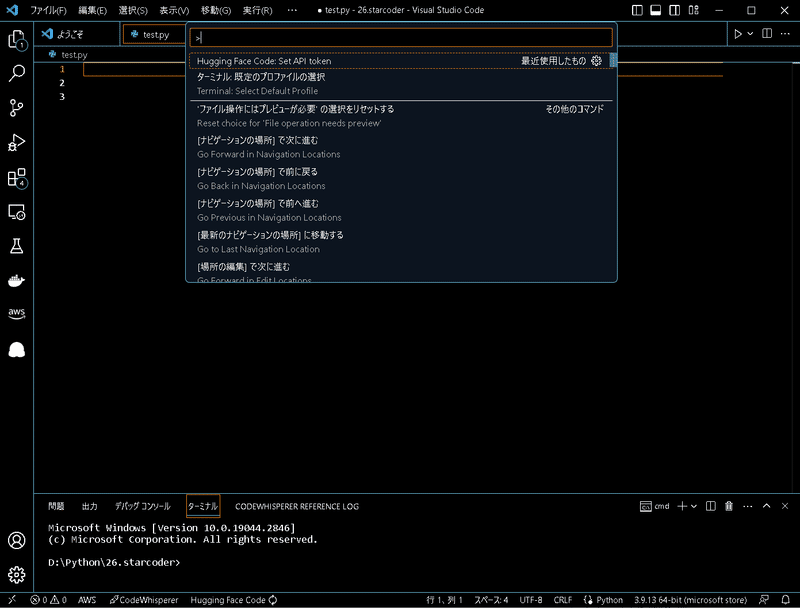

本記事が良かったら、フォローをしていただけると幸いです。
この記事が気に入ったらサポートをしてみませんか?