
Query関数を駆使して日々のちょっとしたデータ関連業務を効率化する

日々の業務の中で、ちょっとしたデータ(数百行~数千行程度)を扱って、集計したり加工したり、分析する業務ってありませんか?
今回はそんな「ちょっとしたデータ関連業務」を行う際に便利な、GoogleSpreadSheetsのQuery関数を紹介します。
この記事の前提は社内でGoogleSpreadSheetsが使えること、対象者は上記のような「ちょっとしたデータ関連業務」が発生する方です。
Query関数とは?
Query関数は、指定した範囲のデータを別のシートに出力することが出来る関数です。その名の通り、”クエリ”によって出力するデータの条件を指定できるので、物凄く便利です。特に非エンジニアの方で、SQLの学習中の方などは、このQuery関数が使えるようになる=SQLの初級レベルと同じくらいだと思うので、個人的におススメです。
Query関数を業務に取り入れるメリット
メリットは「業務効率化」です。例えば、こんな使い方ができます。
営業職:顧客アタックリストのうち、特定の条件を満たすものだけを自分用に抽出したい!
マーケ職:特定のKPIが閾値を超えた日をまとめて引っ張ってきたい!
などなど…様々な場面で使用できます。
ちなみに私はRedashと併用して使うことが多かったです。
Redashのクエリ抽出結果をローデータとして、スプレッドシートに出力(定期更新)
↓
さらにそこから、業務の目的に応じて、Quetry関数で必要なデータを抽出
↓
分析や定点観測業務に利用
このような使い方でした。もしRedashを使っている方がいたら、ぜひ併用すると便利かと思います。
Query関数の基本的な使い方
Query関数はものすごく簡単です。また、SQLを書ける方であればすぐに理解できると思います。基本的な構文は下記です。
=QUERY(データ範囲, クエリ)具体的には、データ範囲を指定した後、SELECTで抽出する列を指定し、WHEREで条件を指定します。
=QUERY(データ範囲, "SELECT 列 WHERE 条件",)実際に書いた方がわかりやすいと思うので、例を使って説明します。
例えばこのような元データがあったとします。日付ごとに記事のタイトル、PV、UU、Sessionなどが並んでいるデータです(数字はテキトーです)。
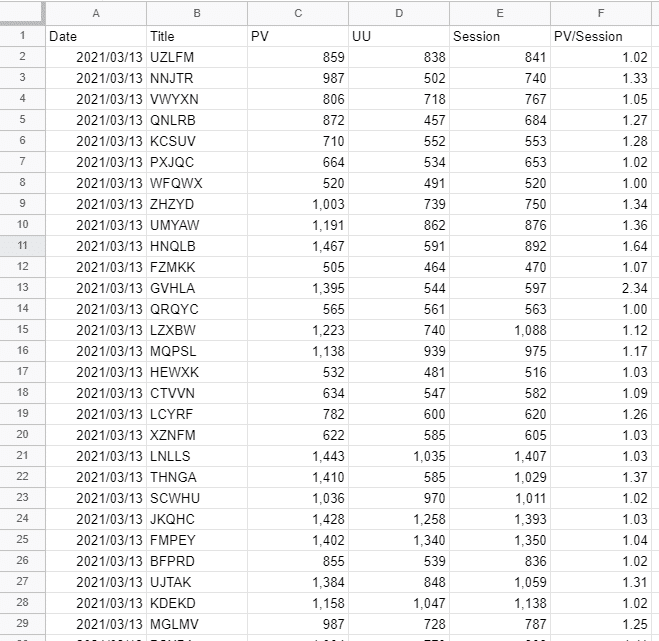
これに対して、「1日当たり、1,000PVかつ1,000UUを超えた記事・日を抽出したい!」というニーズがあったとします。その場合に書くQuery関数はこのようになります。
=QUERY('元データ'!$A$1:$F,"SELECT A, B, C, D WHERE C >= 1000 AND D >= 1000")SELECTでA(日付)・B(タイトル)・C(PV)・D(UU)の列を指定しています。複数列を抽出したい場合はこのようにカンマ(,)で区切ります。また、WHEREで「C(PV)が1,000以上」かつ「D(UU)が1,000以上」という条件にしています。
↓抽出結果
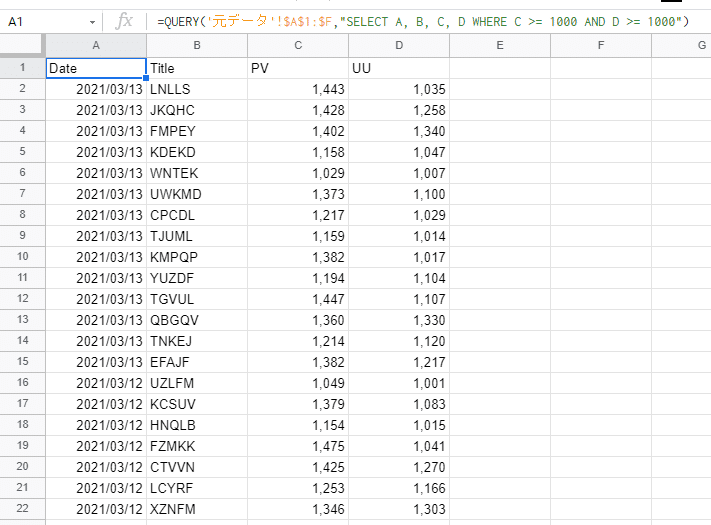
無事、ニーズ通りのデータが抽出できました。
ちなみにWHEREでは「AND」「OR」が使えます。また、SELECTを「SELECT *」にすると、全ての列が表示されます。
このようにQuery関数は欲しいデータの条件を指定して出力できるので、めちゃめちゃ便利です。また、一度関数を記入しておけば、元のデータが更新されても同じ条件でデータを出力できるので、定期的にデータを抽出・加工・分析する系の業務と非常に相性がいいです。
オプションや演算子を駆使して、Query関数を操る
Query関数には様々なオプションや演算子があり、SQLと同じようなことが出来るので、備忘も兼ねて紹介します。
ちなみに、各説明で使う元データは下記とします。
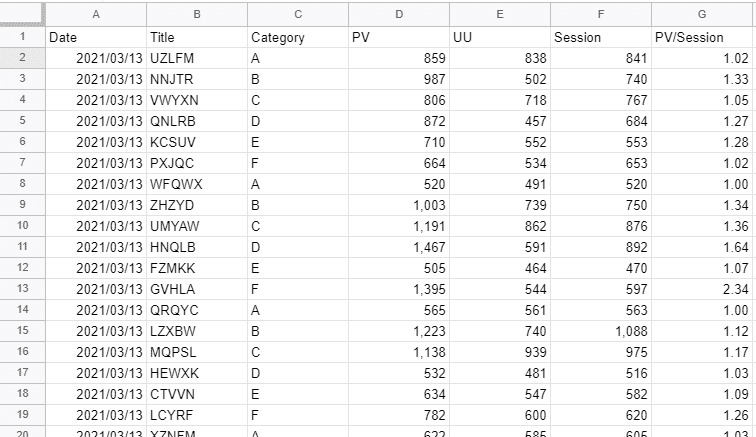
【1】GROUP BY と集計関数でグルーピングして集計
「○○ごとに△△を集計したい」というニーズがある際に便利なGROUP BYです。例えば「日付ごとにPV数の合計を集計したい」とします。
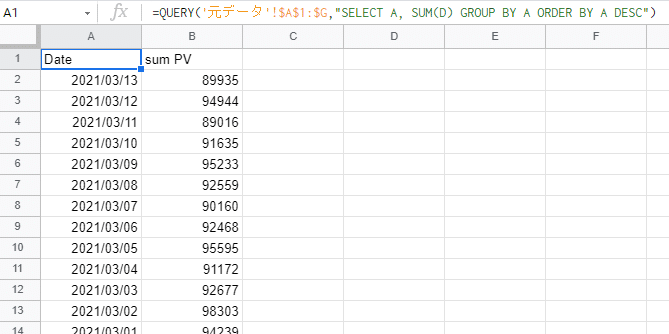
=QUERY('元データ'!$A$1:$G,"SELECT A, SUM(D) GROUP BY A")このように書けばOKです。構文にするとこんな感じですね↓
=QUERY(範囲,"select 列A, 集計関数(列D) group by 列A")↓抽出結果
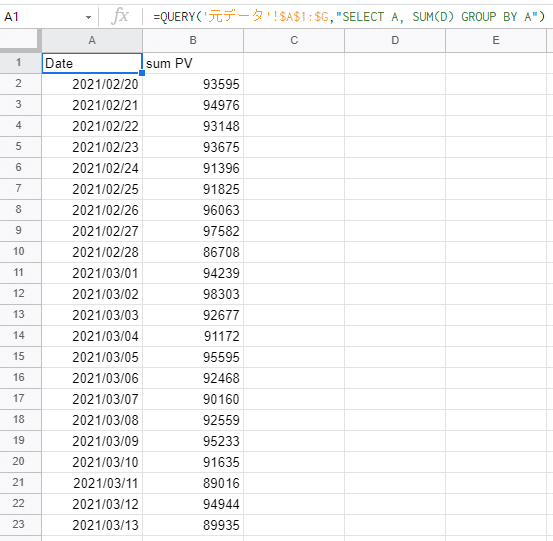
ちなみに下記の集計関数が使えます。
AVG():平均
COUNT():個数
MAX():最大値
MIN():最小値
SUM():合計
【2】ORDER BY で出力結果を並び替える
抽出した結果を昇順・降順に並び替えたい時に使えるのが「ORDER BY」です。
ORDER BY ASC:昇順
ORDER BY DESC:降順
です。先ほどの【1】で抽出した結果は昇順でしたので、それを降順に並び替えてみましょう。
=QUERY('元データ'!$A$1:$G,"SELECT A, SUM(D) GROUP BY A ORDER BY A DESC")↓抽出結果
【3】LABEL で出力する列の名称を変更する
データを出力した後に、「列の名称を変えたい」場合もあると思います。そんな時に便利なのがこの「LABEL」オプションです。構文はこうなります。
=QUERY(範囲, "SELECT 列A, 列B LABEL 列A '名称A', 列B '名称B'")↓集計関数を使っている場合はこのように書きます。
=QUERY(範囲, "SELECT 列A, 集計関数(列B) GROUP BY 列A LABEL 列A '名称A' 集計関数(列B) '名称B' ")先ほどの【2】で集計した結果の列の名称を変える場合はこう書きます。
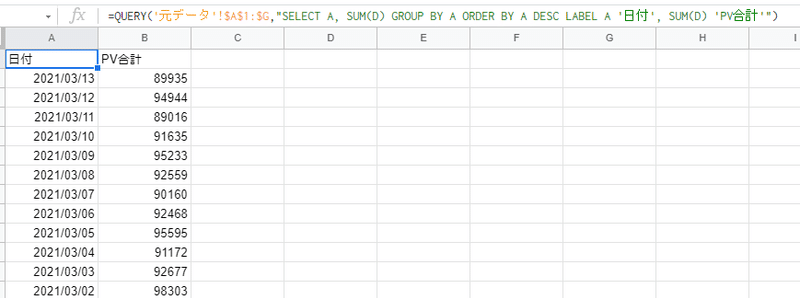
=QUERY('元データ'!$A$1:$G,"SELECT A, SUM(D) GROUP BY A ORDER BY A DESC LABEL A '日付', SUM(D) 'PV合計'")↓抽出結果
【4】PIVOTでクロス集計表を作る
抽出したデータをピボットしてクロス集計表を作りたいことってありませんか?でもいちいちピボットテーブルを挿入してたら面倒ですよね。
そこで、PIVOTを使います。こんな感じの構文になります↓
=QUERY('範囲,"SELECT <縦軸の列>, <見たい値の集計> GROUP BY <縦軸の列> PIVOT <横軸の列>")例えば元データで、日付(A列)ごと×カテゴリー(C列)ごとのPV数(D列)合計を見たい場合、こう書きます。
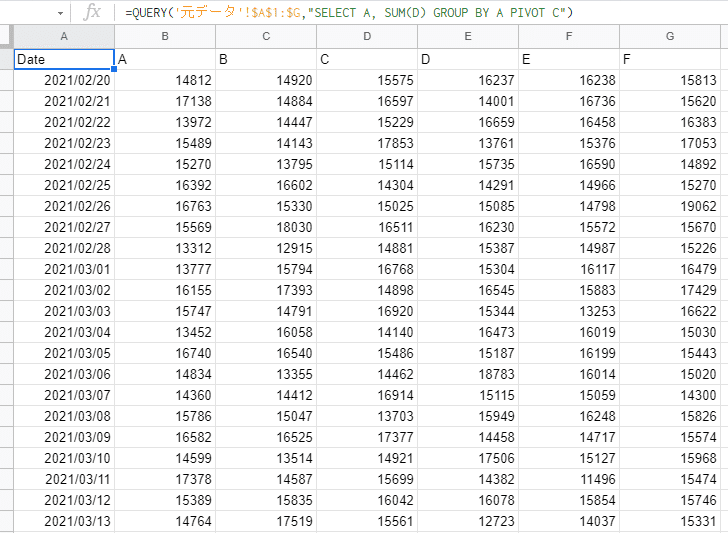
=QUERY('元データ'!$A$1:$G,"SELECT A, SUM(D) GROUP BY A PIVOT C")↓抽出結果(無事、抽出されました)
集計関数として使える下記と組み合わせることで、非常に作業が効率化されると思いますよ。
AVG():平均
COUNT():個数
MAX():最大値
MIN():最小値
SUM():合計
【5】CONTAINSを使って、特定の文字列を含む行を表示する
特定の文字列だけを含む行だけ抽出したい!という場面もたまに起こると思います。その時に便利なのがCONTAINSです。構文は下記です。
=QUERY(範囲, "WHERE 列 CONTAINS '文字列' ")例えば元データのB列(タイトル)に「A」という文字を含んだ記事のPVを日付(A列)ごとに表示したい場合はこうなります。
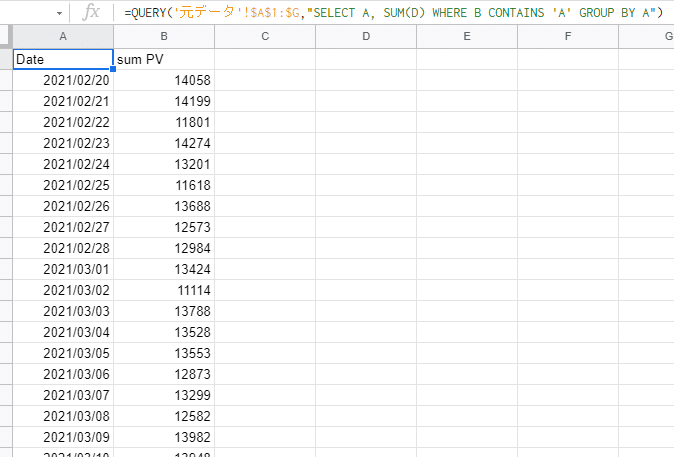
=QUERY('元データ'!$A$1:$G,"SELECT A, SUM(D) WHERE B CONTAINS 'A' GROUP BY A")↓抽出結果
CONTAINSは応用として下記の使い方も可能です。
・「AND」「OR」で複数条件を指定
=QUERY(範囲, "WHERE 列 CONTAINS '文字列A' AND 列 CONTAINS '文字列B' OR 列 CONTAINS '文字列C' ")・「NOT」で除外条件を指定
=QUERY(範囲, "WHERE NOT 列 CONTAINS '文字列' ")【6】STARTS WITH / ENDS WITH で行の先頭 or 行の後尾文字列に条件を指定する
また、STARTS WITH / ENDS WITHを使うことで、文字列の先頭や後尾に入っている文字列を指定して条件設定できます。
STARTS WITH:指定した文字列で始まる行を表示
ENDS WITH:指定した文字列で終わる行を表示
基本的な使い方はこうなります。
=QUERY(範囲, "WHERE 列 STARTS WITH '文字列' ")
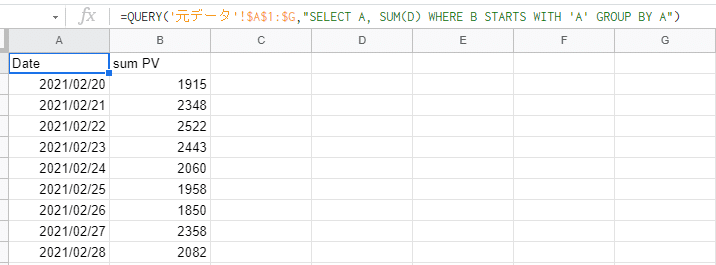
=QUERY(範囲, "WHERE 列 ENDS WITH '文字列' ")例えば元データのB列(タイトル)の先頭に「A」という文字を含んでいる記事のPVを日付(A列)ごとに表示したい場合はこうなります。
=QUERY('元データ'!$A$1:$G,"SELECT A, SUM(D) WHERE B STARTS WITH 'A' GROUP BY A")↓抽出結果
【7】LIKE で複雑な条件を指定する
CONTAINSやSTARTS WITH、ENDS WITHでは対応できない、より複雑な条件を指定したい時に便利なのがLIKE演算子です。基本的な構文はこうなります。
=QUERY(範囲,"WHERE 列 LIKE '検索文字列' ")LIKE演算子の特徴は、ワイルドカード(%, _)という特殊文字が使えることです。
%(パーセント):ゼロ文字または1文字以上を意味する
└「%文字列」:最後が"文字列"で終わる
└「文字列%」:"文字列"で始まる
└「文字列A%文字列B」:”文字列A”で始まり、”文字列B”で終わる
_(アンダースコア):何かしら1文字以上を意味する
└「____」(アンダースコアがx個):x文字
└「文字列A_文字列B」:”文字列A”で始まり、1文字挟んで”文字列B”がある
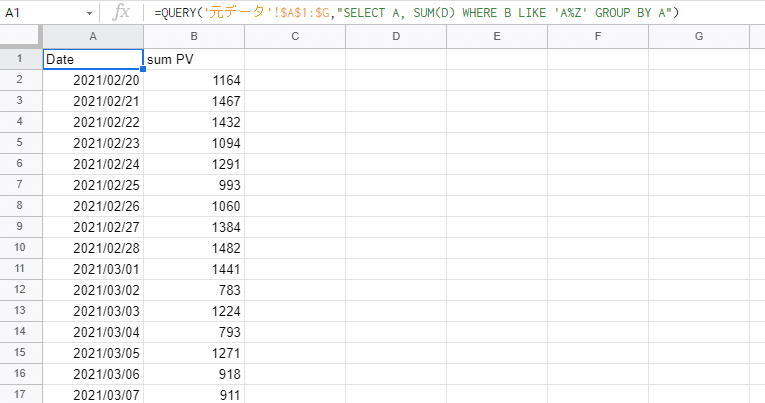
例えば元データのB列(タイトル)が「A」から始まり「Z」で終わる記事のPVを日付(A列)ごとに表示したい場合はこうなります。
=QUERY('元データ'!$A$1:$G,"SELECT A, SUM(D) WHERE B LIKE 'A%Z' GROUP BY A")↓抽出結果
他にも便利な使い方がたくさん
他にも便利な使い方がたくさんあります。例えば
・WHERE条件で日付を範囲として指定する
・IMPORTRANGE関数と組み合わせて別シートを参照する
・複数のシートや範囲を結合する
など、もはやSQLと同じような使い方が出来てしまいます。興味がある方はぜひ調べてみてください。
以上、便利なQuery関数の紹介でした。業務によると思いますが、「ちょっとしたデータの集計・加工・分析」に大いに活用できると思います。ぜひ参考にして頂ければ幸いです。
最後までお読み頂きありがとうございました。
------------------------------------
よかったらtwitterのフォローもどうぞ。
https://twitter.com/MasayukiAbe7
------------------------------------
この記事が気に入ったらサポートをしてみませんか?