scikit-learnを使って外国語文章判定と分布図の作成

どうもおはこんばんにちは。マタキチです。
えっと、えっとですね。もうきてます。秋冬の雰囲気。あと少ししたら息が白くなりますね。私ごとではありますが、コーヒーが好きなのです。ホットのやつです。湯気でメガネが曇るあれです。それがですね、冬になるとより美味しいのです。香りが強くなって。おすすめのお店は「Fuglen Tokyo」(関連サイト:haletto [ URL:https://haletto.jp/201902_fuglen-tokyo/ ])です。ここのコーヒーは苦味が苦手という方でも美味しく飲めるコーヒーだと思います。そんな濃くはないので。香りがすごくよくて、フルーティな香りが楽しめます。ただ店内とお客さん方と立地がしゃれおつすぎるので、私はテイクアウトしてすぐにお店から離れます。そんなお店です。何店舗かあるみたないのでぜひ。そんな今日この頃です。
pythonでスクレイピングと機械学習とその周辺を勉強してるので記述します。間違い等ありましたらご指摘いただけたら嬉しいです。
どのように判定していくか
外国語テキストを読ませて何語か判定してもらいましょう。しかし生のテキストデータを学習に読み込ませることはできません。何を特徴量とするのか。調べてみると言語というのはそれぞれ言語ごとに特定のアルファベットの出現率があるようです。日本語に触れているとわからないポイントですね。この出現率を特徴量として判定していきたいと思います。
サンプルデータはWikipeidaから英語(en)、フランス語(fr)、インドネシア語(id)、タガログ語(tl)を用意しました。それぞれテキストファイルにしてlangディレクトリ下に配置しています。学習用データ20件、テスト用データ8件としています。少ないデータですがお試し程度に。
言語判定プログラム
それではコードを書いていきましょう。今回はscikit-learnを使用して、svmアルゴリズムで予測してみましょう。
from sklearn import svm, metrics
import glob, os.path, re, json
def check_freq(fname):
name = os.path.basename(fname)
lang = re.match(r'^[a-z]{2,}', name).group()
with open(fname, "r", encoding="utf-8") as f:
text = f.read()
#小文字に変換
text = text.lower()
count = [0 for n in range(0, 26)]
#組み込み関数を使って文字をUnicode コードポイントを表す整数に変換
code_a = ord("a")
code_b = ord("z")
for ch in text:
n = ord(ch)
if code_a <= n <= code_b:
count[n - code_a] += 1
#正規化している(出現率に変換している)
total = sum(count)
freq = list(map(lambda n: n / total, count))
return (freq, lang)
#ファイル処理
def load_files(path):
freqs = []
labels = []
file_list = glob.glob(path)
for fname in file_list:
r = check_freq(fname)
freqs.append(r[0])
labels.append(r[1])
return {"freqs":freqs, "labels":labels}
data = load_files("./lang/train/*.txt")
test = load_files("./lang/test/*.txt")
#今回はグラフ化もしてみたいのでJSON形式で保存
with open("./lang/freq.json", "w", encoding="utf-8") as f:
json.dump([data, test], f)
#学習、予測、結果出力
clf = svm.SVC()
clf.fit(data["freqs"], data["labels"])
predict = clf.predict(test["freqs"])
ac_score = metrics.accuracy_score(test["labels"], predict)
cl_report = metrics.classification_report(test["labels"], predict)
print("正解率:", ac_score)
print("レポート")
print(cl_report)コードの解説
それではscikit-learnを使用して言語判定プログラムを作成していきます。まずはscikit-learnをインポートします。
from sklearn import svm, metrics
import glob, os.path, re, json次に、テキストを読んで出現頻度を調べるコードです。ファイル名の先頭2文字がどの言語のファイルか表しているのでそれを利用してテキストファイルを開いて小文字に変換します。
def check_freq(fname):
name = os.path.basename(fname)
lang = re.match(r'^[a-z]{2,}', name).group()
with open(fname, "r", encoding="utf-8") as f:
text = f.read()
#小文字に変換
text = text.lower()
次にアルファベットごとの出現回数を調べるコードになります。aからzを一文字ずつ取り出して文字コードに直します。そしてアルファベットを数えるリストを一文字ずつカウントアップしていきます。ちなみにアクセント記号のついた文字は無視しています。また、途中アルファベットの出現回数を文字数のトータルで割って出現率に直しています。なぜ出現率にするかというと文字数がデータごとに異なるからです。このようにデータを一定の規則に基づいて変形し利用しやすくすることを「正規化する」といいます。
count = [0 for n in range(0, 26)]
code_a = ord("a")
code_b = ord("z")
for cha in text:
n = ord("cha")
if code_a <= n <= code_z:
count[n - code_a] += 1
#正規化している(出現率に変換している)
total = sum(count)
freq = list(map(lambda n: n / total, count))
return (freq, lang)次にファイルの処理をします。globモジュールを使って引数に指定したパターンと同じパターンのファイルパス名を取得してリストにまとめましょう。また今回はこの後グラフにしたいので、その時のためにJSON形式で保存します。
def load_files(path):
freqs = []
labels = []
file_list = glob.glob(path)
for fname in file_list:
r = check_freq(fname)
freq.append(r[0])
labels.append(r[1])
return {"freqs":freqs, "labels":labels}
data = load_files("./lang/train/*.txt")
test = load_files("./lang/test/*.txt")
with open("./lang/freq.json", "w", encoding="utf-8") as f:
json.dump([data, test], f)これでファイル処理とJSON形式での保存が完了しました。ここからは処理したdata[freqs]とdata[labels]を使って学習して、test[freqs]を予測してみます。
clf = svm.SVC()
clf.fit(data["freqs"], data["labels"])
predict = clf.predict(test["freqs"])
ac_score = metrics.accuracy_score(test["labels"], predict)
cl_report = metrics.classification_report(test["labels"], predict)
print("正解率:", ac_score)
print("レポート")
print(cl_report)以上でコードはできました。コンソールから実行してみましょう。実行結果がこちらです。

結果は正解率0.875です。データ量の割にはいい結果ですね。この結果から、最初に仮説?をたてた言語ごとに出現率に特徴があることもわかります。
分布図を作成してみよう
この結果をグラフにすることで、分布図が作成できるのではないか(データ量が少ないことはさておき)ということでグラフ化してみます。matplotlibとpandas、numpyを使用してグラフ化します。今回は棒グラフでいきます。
import matplotlib.pyplot as plt
import pandas as pd
import json
#先ほど作った出現率のJSON形式ファイルを読み込みます
with open("./lang/freq.json", "r", encoding="utf-8") as f:
freq = json.load(f)
#言語ごとに集計していきます
lang_dic = {}
for i, lbl in enumerate(freq[0]["labels"]):
fq = freq[0]["freqs"][i]
if not (lbl in lang_dic):
lang_dic[lbl] = fq
continue
for idx, v in enumerate(fq):
lang_dic[lbl][idx] = (lang_dic[lbl][idx] + v) / 2
#pandasのDataFrameにデータを入れます
asclist = [[chr(n) for n in range(97, 97+26)]]
df = pd.DataFrame(lang_dic, index=asclist)
#プロットしてグラフ化
plt.style.use('ggplot')
df.plot(kind="bar", subplots=True, ylim=(0,0.15))
plt.savefig("lang-plot.png")コードが書けたので実行します。結果がこちら。
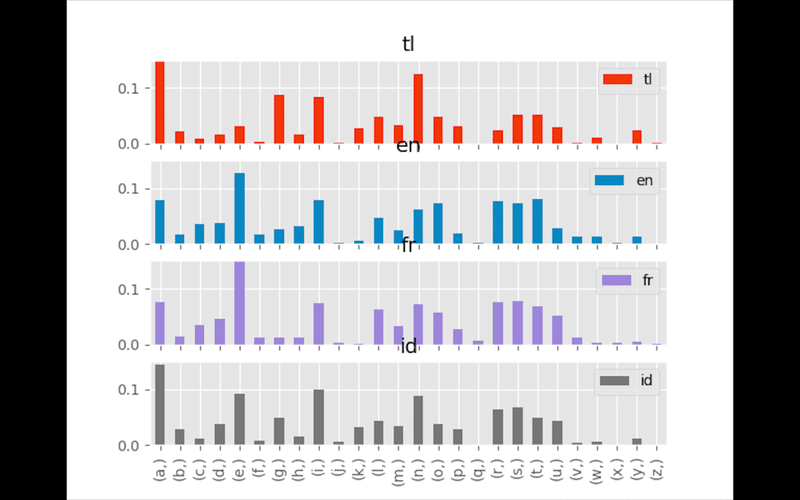
おお!!分布グラフになってる。ちょっと見にくいかもしれないけども。これを見ると、英語とフランス語はアルファベットの出現率としては似ているんですね。ただフランス語は「f、g、h」が真っ平らだけど英語はそんなことはない。タガログ語は「g」めっちゃ使うんだなー。とか色々思いながら見ています。グラフとかデータ見るの好きです。笑
まとめ
今回はデータ量が少ないながらもいい結果でしたね。scikit-learnを使って言語判断をしてみました。データ増やしたらもっと精度上がるだろうしグラフの違いが顕著になりそうですね。グラフも棒グラフだけじゃないんだろうなー。勉強しよっと。以上ですー。
この記事が気に入ったらサポートをしてみませんか?