scikit-leanとpandasで機械学習

どうもおはこんばんにちは。マタキチです。
自分の借りている部屋は両側に住人がいるのですが・・・気まづい時ってありますよね。えっ?って、あはっ♪ってなる時・・・ありませんか?先週の夜には両側から営みの声が聞こえ、今週は喧嘩の声が聞こえ。もう生活感が5.1chサラウンド。なんならたまにハウリングして聞こえる。事前に打ち合わせたかのようなマッチング。そこらへんのマッチングアプリなんかより高確率でマッチングしてます。うーーん。なにか周期性でもあるんでしょうか。マタキチは名探偵になりたいと思います。真実はいつもひとつ。まずはアポトキシンを絶対に作ろうと、灰原さんを探そうと強く思った今日この頃。
pythonでスクレイピング、機械学習なんかを勉強しています。忘備録的な意味合いが強いのであしからず。間違いなどご指摘いただけたら幸いです。
機械学習
Pythonが流行ってるって巷で聞きましたが、それはAIやら機械学習が注目されているからという理由が強い気がします。そんな機械学習ですが、要約すると一定数のデータから規則性、特徴なんかを分析して別のデータを分類、予測することです。統計学と似ている気がしますね。数学でいうベクトルの考え方にも似ている。
機械学習の分類
機械学習と言う言葉を使う時、大きく行って次の三つに分類できます。
教師あり学習 : データと共に正解が与えられる
⇨未知のデータに対して予測を行う
教師なし学習 : 正解は与えられない
⇨未知のデータから規則性を発見する
⇨データから最適な解を見つける
強化学習 : 行動により部分的に正解が与えられる
⇨データから最適な解を見つける
これらを少し詳しく見ていきます。
教師あり学習
教師あり学習(Supervised learningって言うらしい)は事前に与えられたデータを元に学習を行う手法です。一般的にデータ入力する際に答えとなるラベル(なんのデータか)をセットで与えて学習させます。手書き文字認識プログラムなんかこれに該当します(文字画像となんの文字を表しているかの正解とをセットで学習させる)。このようにモデル構築して、未知のデータを予測するという手法になります。データのチョイスが大事になりそうですね。質と量を考えて覚えさせないと。
教師なし学習
教師なし学習(Unsupervised learningって言うらしい)は教師あり学習と違い、出力する結果に「出力するべきもの」があらかじめ決まっていないという点で上記と異なります。要するに与えられたデータを、基準なし(外的モデルなし)に自動分類します。データの本質的な構造が見えそうな気がします。手法としてはクラスター手法、主成分分析、ベクトル量子化、自己組織マップなどさまざまあります。
強化学習
強化学習(Reinforcement learningとな)があります。これは教師あり学習ににてますが違います。教師ありは完全な答えをもらいますが、強化学習はありません。エージェントと呼ばれる行動主体と環境が登場します。環境を観察してそれに基づいた行動をします。結果、環境が変わりエージェントに報酬が渡され、環境が変化します。こうやってより良い行動をしていく学習になります。
流れとしてはデータを集めて、整形して、学習(手法選択、パラメーター調整、モデル学習)させて、モデルを評価、精度を確認、成功or失敗なんて流れになります。ざっくりですが。簡単に書いてますが出だしかなり肝心な気がします。
scikit-learnとpandasをダウンロード
ここでは試しにアヤメ(世界中に150種類ほどある多年草の植物)の品種分類をしてみましょう。まずはscikit-learnとpandasのダウンロード。scikit-learnとは機械学習向けのライブラリーになります。分類器が豊富に用意されていて分類・回帰・クラスタリング・次元削除などさまざまなアルゴリズムをサポートしてくれる優秀な子です。
$ sudo pip3 install -U scikit-learn scipy matplotlib scikit-image
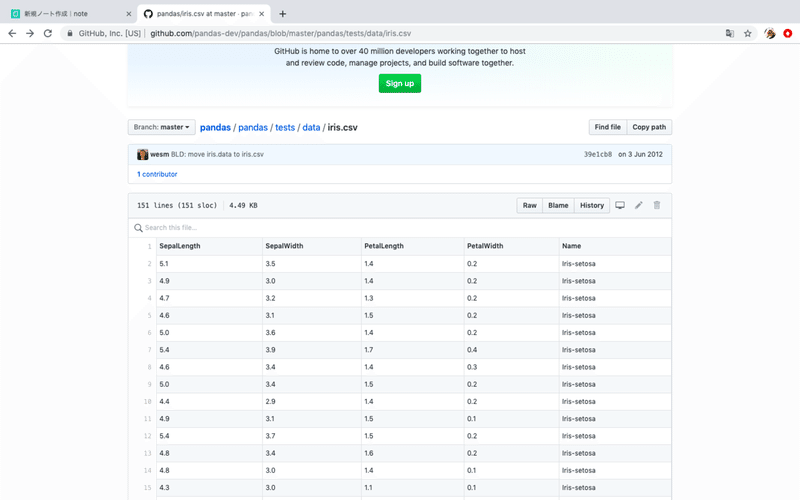
$ sudo pip3 install pandas次にアヤメのデータの入手します。Fisherのアヤメデータとして有名なアヤメの分解データがネット上で公開されています。今回さまざまなオープンソースが集約されているGitHubからダウンロードします。下記サイトからです。
#GitHub > Pandas > iris.csv
[URL] https://github.com/pandas-dev/pandas/blob/master/pandas/tests/data/iris.csv
サイトからデータのすぐ上にある[Raw]のボタンを押します。すると、素のCSV形式で表示されるので、Webブラウザーの「ファイル>名前をつけて保存」で保存します。今回は「iris.csvとして保存します」
品種分類のプログラミングを書いてみよう
さて、ダウンロードを元に品種分類プログラミングの書いてみましょう。目標はがく片と花びらの長さ・幅のデータを元に品種分類することです。データは150件ほどありますので今回は100件を学習用、50件をテスト用にしてみます。
#▽iris.py
from sklearn import svm, metrics
import random, re
#ダウンロードCSVデータを読み込む
csv = []
with open('iris.csv', 'r', encoding = 'utf-8') as f:
#一行ずつ読む
for line in f:
line = line.strip()
cols = line.split(',')
#文字列データを数値に変換
fn = lambda n : float(n) if re.match(r'^[0-9\.]+$', n) else n
cols = list(map(fn, cols))
csv.append(cols)
#先頭のヘッダー行を削除する
del csv[0]
#データをシャッフル
random.shuffle(csv)
#学習用とテスト用に分割する(2:1の比率で)
total_len = len(csv)
train_len = int(total_len * 2/3)
train_data = []
train_label = []
test_data = []
test_label = []
for i in range(total_len):
data = csv[i][0:4]
label = csv[i][4]
if i < train_len:
train_data.append(data)
train_label.append(label)
else:
test_data.append(data)
test_label.append(label)
#データを学習し、予測する
clf = svm.SVC()
clf.fit(train_data, train_label)
pre = clf.predict(test_data)
#正解率を計算する
ac_score = metrics.accuracy_score(test_label, pre)
print("正解率=", ac_score)コードはこんな感じでしょうか。実行結果がこちらです。
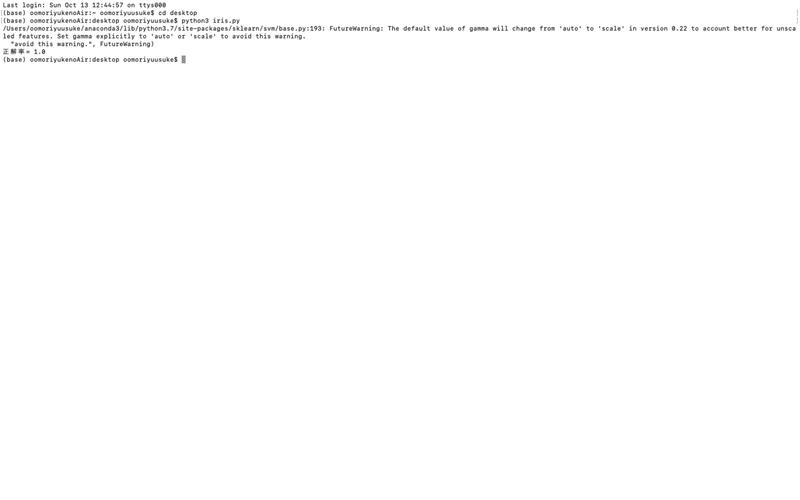
正解率が1.0と出ていますが、これはランダムで選んでいるので2回目、3回目で結果が変わってきます。しかし高い数値ですね。これは品種分類できていると思えます。余談ですが、正解率の前に出ている文面ですが、これはエラーではなく「動くけどそのコードちょっとあれだよ」って意味です。細かく言うと、「sklearnの将来のバージョンで仕様が変わるよ・・・」ということを教えてくれています。
コード解説
#ダウンロードCSVデータを読み込む
csv = []
with open('iris.csv', 'r', encoding = 'utf-8') as f:
#一行ずつ読む
for line in f:
line = line.strip()
cols = line.split(',')
#文字列データを数値に変換
fn = lambda n : float(n) if re.match(r'^[0-9\.]+$', n) else n
cols = list(map(fn, cols))
csv.append(cols)アヤメのCSVデータを読み込んで一行ずつCSVファイルを読み込んで、さらに各行をカンマで分割します。この時、各セルのデータは文字列となっており数値に変換しておく必要があります。正規表現で数値がどうか判定し数値であればfloat()を使って実数に変換する処理を施しています。先にlambda式で無名関数を定義してリストを一気に処理するmap()関数を利用して、全てリストの値を変換します。三項演算を利用しており書式は以下になります。
(値)=(Trueの値)if(条件)else(Falseの値)
#学習用とテスト用に分割する(2:1の比率で)
total_len = len(csv)
train_len = int(total_len * 2/3)
train_data = []
train_label = []
test_data = []
test_label = []
for i in range(total_len):
data = csv[i][0:4]
label = csv[i][4]
if i < train_len:
train_data.append(data)
train_label.append(label)
else:
test_data.append(data)
test_label.append(label)
#データを学習し、予測する
clf = svm.SVC()
clf.fit(train_data, train_label)
pre = clf.predict(test_data)総データ150件を学習用100件、テスト用50件と分割します。さらに、SVCアルゴリズムを使用してデータを学習、テストデータの分類を行います。
最後に分類結果を正解と照合して、正解率を求めます。その正解率をprint()して終わっています。
ちなみに訓練データとテストデータを分ける意味としては、どんなに訓練データでいい数値を出していたとしても、実際に未知のデータを使って測定させたときにうまく分類できていなかったら意味がありません。そこで、テストには未知のデータを使用し、うまく学習できているかを確認するということです。
まとめ
機械学習を使うとデータ分類が可能になる。また、未知のデータでも試してみたくなる(個人的な意見)。scikit-learnのフレームワークを使うとより簡単にかける。学習用メソッド、テスト用メソッドを書いてみても簡単になるかも。あとはグラフ化とかしてみたいなという個人的な願望です。以上ですーーーー。
この記事が気に入ったらサポートをしてみませんか?