Scrapyとseleniumでダウンロード

どうもおはこんばんにちは。マタキチです。
知っている方は知っていると思いますが先日ガンダムナラティブが期間限定で無料配信されていました。えっとですね。主人公のヨナとミシェルが罪を償うためにリタを追いかけたり、ナラティブガンダムに乗って奮闘したり、パーツ換装してかっこよくなったりと大いにガンダムしている間にね、おじさんは一つ一つ着実に年を重ねたわけです。なのにね、おじさんはねー、機体がねー、もういつになったら発進するのかと。いまだに管制塔から発進を譲渡してもらえず、カタパルトで姿勢だけは主人公並みに飛び出す体制の今日この頃です。
pythonでスクレイピングを勉強しているので記述していきます。忘備録的な意味合いが強いです。間違いありましたらご指摘いただけたら幸いです。
動的WebサイトからScrapyを使ってダウンロード
昨今のWebサイトはjavascriptで動的に生成される部分が多いです。Scrapyは優秀なライブラリーなのですが、こういったサイトではデータを取得できない場合もあります。幸いScrapyにはミドルウェアを導入できるのでseleniumを導入してこれを解決しましょうというのが今回です。ミドルウェアとは本来の意味としてはアプリとOSをつなぎとめる役割になるのかな。この場合はScrapyだけではサイトのログインとかできないけどSeleniumをミドルウェアとすることで可能になると。サイトとScrapyの中間にSeleniumが入る感じ。
ミドルウェアの設定
前回の記事(https://note.mu/matakichi32/n/n259e4d2fe478)から所定の場所にselenium_middleware.pyを作成したいと思います。
#必要なモジュールをインポート
from scrapy.http import HtmlResponse
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
#Chromeを初期化
driver = webdriver.Chrome()
#Chromeで任意のサイトを開く
def selenium_get(url):
driver.get(url)
#CSSクエリを指定して読み込みが完了するまで待機
def get_dom(query):
dom = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, query)))
return dom
#Chromeを閉じる
def selenium_close():
driver.close()
#こちらがミドルウェア本体
class ScrapyListSpiderMiddleware(object):
def process_request(self, request, spider):
driver.get(request.url)
return HtmlResponse(driver.current_url, body = driver.page_source, encoding = 'utf-8', request = request)上記のようにミドルウェアに記述をたす。まずはSeleniumでChromドライバーを初期化して、Chromeオブジェクトを取得します。次に、任意のURLを開きページロードまで待機します。次にCSSセレクターを用いてDOMを抽出します。そしてChromeを閉じると。ミドルウェア本体では、process_request()メソッドを定義して、Seleniumを用いて任意のURLを取得、また取得したHTMLをレスポンスとして返しています。
Spiderの作成
ミドルウェアを記述したら続いてSpiderを記述しましょう。
#ミドルウェアとscrapyをインポート
import scrapy, pprint
from ..middlewares import *
#ユーザ名とパスワードを指定
USER = "JS-TESTER"
PASSWORD = "ipCU12ySxI"
class GetallSppider(scrapy.Spider):
name = 'getall'
#ミドルウェアを登録
custom_setting = {
"DOWNLOAD_MIDDLEWARE":{
"scrapy_list.selenium_middleware.ScrapyListSpiderMiddleware"
}
}
#リクエスト実行前にログインする
def start_requests(self):
url = "https://uta.pw/sakusibbs/users.php?action=login"
selenium_get(url)
user = get_dom('#user')
user.send_keys(USER)
pw = get_dom('#pass')
pw.send_keys(PASSWORD)
btn = get_dom('#loginForm input[type=submit]')
btn.click()
a = get_dom('.islogin a')
mypage = a.get_attribute('href')
print("mypage=", mypage)
yield scrapy.Request(mypage, self.parse)
def parse(self, response):
#一覧の取得
alist = response.css('ul#mmlist > li a')
for a in alist:
url = a.css('::attr(href)').extract_first()
url2 = response.urljoin(url)
yield response.follow(url2, self.parse_sakuhin)
def parse_sakuhin(self, response):
#titleを取り出す
title = response.css('title::text').extract_first()
print("---", title)
src = response.css('iframe::attr(src)').extract_first
src2 = response.urljoin(str(src))
req = scrapy.Request(src2, self.parse_download)
yield req
#指定のHTMLをダウンロード
def parse_download(self, response):
title = response.meta["title"]
fname = title + ".html"
with open(fname, "wt") as f:
f.write(response.body)
#ブラウザーを閉じる
def closed(self, response):
selenium_close()コンソールからの実行結果がこちら
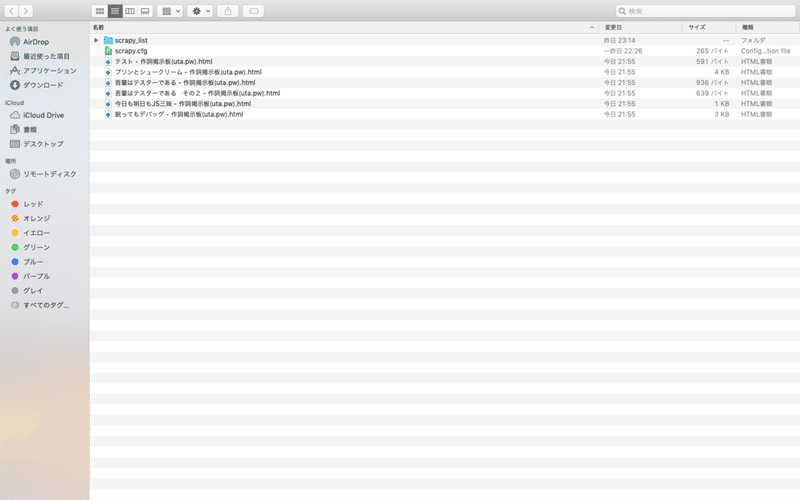
実行結果がこちらです。投稿作品がhtml形式でダウンロードされています。
コード解説
#Seleniumのミドルウェアを取り込みとscrapyをインポート
import scrapy, pprint
from ..middlewares import *
#ユーザ名とパスワードを指定
USER = "JS-TESTER"
PASSWORD = "ipCU12ySxI"
class GetallSppider(scrapy.Spider):
name = 'getall'
#ミドルウェアを登録
custom_setting = {
"DOWNLOAD_MIDDLEWARE":{
"scrapy_list.selenium_middleware.ScrapyListSpiderMiddleware"
}
}まずはSeleniumのミドルウェアを取り込んでいます。あと当然Scrapyのインポートも。次にユーザ名とパスワードを指定しています。これはみなさんの環境に合わせて指定してください。続きましてコマンド名の指定、ミドルウェアを登録しています。ミドルウェアの登録には(プロジェクトディレクトリ名).(ミドルウェアファイル名).(ミドルウェアのクラス名)と指定します。
#リクエスト実行前にログインする
def start_requests(self):
url = "https://uta.pw/sakusibbs/users.php?action=login"
selenium_get(url)
user = get_dom('#user')
user.send_keys(USER)
pw = get_dom('#pass')
pw.send_keys(PASSWORD)
btn = get_dom('#loginForm input[type=submit]')
btn.click()
a = get_dom('.islogin a')
mypage = a.get_attribute('href')
print("mypage=", mypage)
yield scrapy.Request(mypage, self.parse)続きましてリクエスト実行前にログイン処理を記述しています。url変数にはログインページのURLを格納し、selenium_get()で開きます。ユーザー名入力欄のCSSクエリを指定して入力、パスワードも同様です。そしてclick()でログインボタンをクリックします。マイページが表示されたらScrapyの出番です。マイページを指定してリクエストを実行します。
def parse_sakuhin(self, response):
#titleを取り出す
title = response.css('title::text').extract_first()
print("---", title)
src = response.css('iframe::attr(src)').extract_first
src2 = response.urljoin(str(src))
req = scrapy.Request(src2, self.parse_download)
yield req
#指定のHTMLをダウンロード
def parse_download(self, response):
title = response.meta["title"]
fname = title + ".html"
with open(fname, "wt") as f:
f.write(response.body)リクエスト結果を解析して一覧を取得します。ここでリンク先ページを読み込むように指定します。そして、実データがあるフレームを取り出しています。
最後はブラウザーを閉じています。
まとめ
なかなか理解に苦しみました。ミドルウェアを導入してプログラムを初めて書きました。はじめはget_dom()メソッドをとかはじめ定義してなかったからくそ長いのができましたが、定義したら少しスッキリしたかなと思います。まだまだ学ぶことがたくさんあるなぁ。もっと勉強しないと。
この記事が気に入ったらサポートをしてみませんか?