ど素人のスクレイピング②

おはこんばんにちは。マタキチです。
9月から10月にかけてはもうやるよね。この時期やっちゃうよね人間って。どんなに気をつけててもやっちゃうのが人間だよね。1000回に1回は宛先を思いっきり間違えてメールしちゃうのが人間なんだよね。
先輩「マタキチくん。来週の月曜の件、先方への連絡は?」
マタ「そちらの件は先ほど資料を添付して送付しました。明日念のため電話を入れようかと考えています。」
Prrrrr.....Prrrrr....
先輩「はい。〇〇会社です。はい・・はい・・えっ・・申し訳ございません。・・・」
マタ「???」
ガチャ・・・
先輩「おい・・・思いっきり間違えてるじゃねーか!!!」
マタ「・・・はっ!!ごめんなさい!!!」
・・・・・・・・・・・先輩ほんとごめんなさい。この後メールリスト、
アドレス帳を見直した今日この頃。
pythonでスクレイピングを勉強しているので書いていこうかと思います。
忘備録的な意味合いが強いのであしからず。間違っていたり違う方法あるよなどの、ご指摘いただけると非常に嬉しです!
CSSセレクターで特定のデータを抽出
Webサイトを見ただけではHTMLの構造は理解できません。いやできるのかもしれないけどマタキチはよくわかりません。ということで手取り早く知る方法は、「開発者ツール」もしくは「検証」「ソースページ表示」のコンテキストメニューなんではないでしょうか。下の画像はmacで「shift + command + 3」にてスクリーンショットを撮った画像です。(画像:青空文庫HP 夏目漱石のページ)
ページソースを見ていくといろいろなタグが付いているのがわかります。
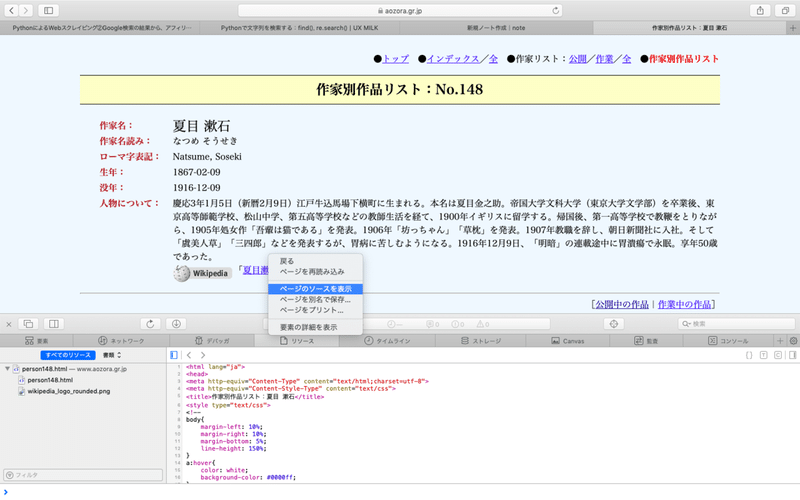
<div>タグに<p>タグ、<ul>タグ、<li>タグと盛りだくさんですね。他にも、URLが記載されている<a>タグ(href属性)だったり色々なタグがあります。そこで抽出したい要素の選択アイコンをクリックしてブラウザー内の作品リストの最初の要素をクリックします。今回は「イズムの功過」を選択しましょう。macの場合は「右クリック」「コピー」「セレクタパス」です
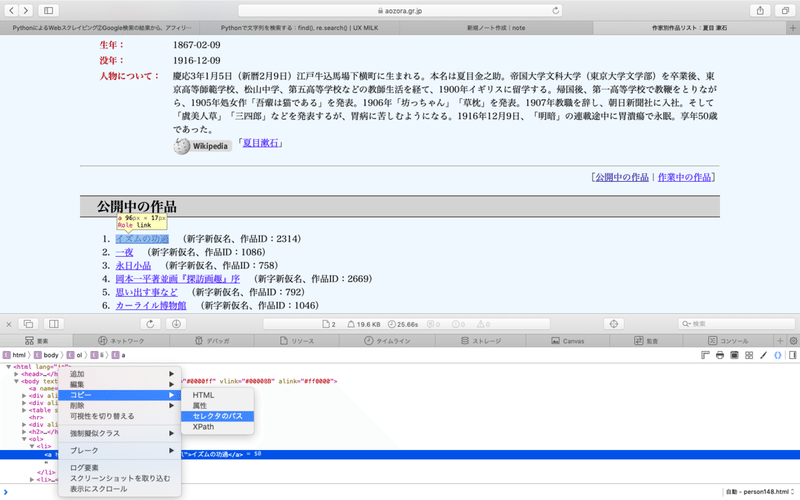
ここで得られたセレクターパスになります。「ol:nth-child(8)」というのは8番目にある<ol>タグという意味です。ただし、BeautifulSoupライブラリーでは「nth-child」の表記に対応していないので、代わりに「nth-of-type」を使用します。
body > ol:nth-child(8) > li:nth-child(1) > a作品一覧のURLをスクレイピングしてみよう
それではCSSセレクターを使用したスクレイピングと、作品一覧のスクレイピングをしてみます。まずは必要なモジュールのインポート・・・
from bs4 import BeautifulSoup
import urllib.request as req次に処理を書いていきます
url = "https://www.aozora.gr.jp/index_pages/person148.html"
res = req.urlopen(url)
soup = BeautifulSoup(res, 'html.parser')
#CSSセレクターを使って抽出
sel = soup.select_one("ol > li:nth-of-type(1)")
print(sel.text)
#一覧を抽出
li_list = soup.select("ol > li")
for li in li_list:
a = li.a
if a != None:
name = a.string
href = a.attrs["href"]
print(name, "=", href)こちらをファイル名「natume.py」と保存して、コンソールから実行
$ python3 natume.py
イズムの功過 (新字新仮名、作品ID:2314)
イズムの功過 = ../cards/000148/card2314.html
一夜 = ../cards/000148/card1086.html
永日小品 = ../cards/000148/card758.html
岡本一平著並画『探訪画趣』序 = ../cards/000148/card2669.html
思い出す事など = ../cards/000148/card792.html
カーライル博物館 = ../cards/000148/card1046.html
薤露行 = ../cards/000148/card769.html
学者と名誉 = ../cards/000148/card2383.html
硝子戸の中 = ../cards/000148/card760.html
・・・
うまくいくとこんな感じです。結果の一行目はCSSセレクターを使用して抽出したデータです。今回はわかりやすくするために別々の状態にしました。
二行目からは作品のURL一覧を抽出しています。たくさん出てでますね。これらを「pandas」を使用してデータ読み込んでcsvにしたりしてデータのやり取りをしたりするんですね。
というわけで、CSSセレクターの確認方法やら、スクレイピングの方法やらでした。
まとめ
CSSセレクターを確認するとタグ情報や欲しいデータのセレクターがわかる。確認方法は「開発者ツール」「検証」「ソースページ表示」からセレクターの確認、コピーができる。それを利用すると、本当に欲しいところだけを抽出したデータが取れる。
以上ですーー。
この記事が気に入ったらサポートをしてみませんか?