高校数学をプログラミングで解く(数学I編)「3-4 データの相関」

はじめに
今回は、数学Iで学ぶ「データの相関」について、2つの変量のデータの散布図を描くプログラムとそれらのデータの共分散と相関係数を求めるプログラムを作成し、データの相関関係について考察します。
データの相関
まず、相関関係、共分散、相関係数についてまとめておきます。
相関関係
2つの変量のデータにおいて、一方が増えると他方が増える(減る)傾向が認められるとき、2つの変量の間に正の(負の)相関関係があるという。
共分散
$${x}$$の偏差と$${y}$$の偏差の積$${(x_k-\bar{x})(y_k-\bar{y})}$$の平均値
$$
s_{xy} = \frac{1}{n} \{ (x_1-\bar{x})(y_1-\bar{y})+(x_2-\bar{x})(y_2-\bar{y})+ \cdots +(x_n-\bar{x})(y_n-\bar{y}) \}
$$
相関係数
$$
r = \frac{s_{xy}}{(x \mathrm{の標準偏差})(y \mathrm{の標準偏差})} \ \ (-1 \leq r \leq 1)
$$
今回は、2つの変量のデータに対して散布図を描き、共分散、相関係数の値を求めるプログラムを作成していきます。
利用するデータの準備
今回2つの変量のデータは以下のものを利用します。
$$
x : 43,39,51,27,65,24,62,33,56,48 \\
y : 59,62,84,53,76,48,83,47,65,72
$$
なお、$${x}$$の値と$${y}$$の値とは順に対応しています。また、プログラムではそれぞれfloat型の配列として扱います。
int data_num = 10; // データ数
float[] data_x = {43,39,51,27,65,24,62,33,56,48}; // データx
float[] data_y = {59,62,84,53,76,48,83,47,65,72}; // データy散布図を描く
ではまず、散布図を描いてみます。今回準備した2つの変量のデータの散布図を描くプログラムを作成してみました。
// 散布図を描く
void setup(){
size(600, 600); // キャンバスの大きさを指定する
background(255,255,255); // 背景を白色にする
noFill(); // 図形の塗りつぶしなし
noLoop(); // 繰り返し処理をしない
// データ
int data_max_value = 100;
int data_num = 10; // データ数
float[] data_x = {43,39,51,27,65,24,62,33,56,48}; // データx
float[] data_y = {59,62,84,53,76,48,83,47,65,72}; // データy
// 余白
float margin = 50.0;
// 表示範囲
float range = width - 2.0 * margin;
// 目盛り間の幅
float segment = range / data_max_value;
// 目盛りのサイズ
float segment_size = 10.0;
// 描画する目盛りの個数
int display_segment_num = 10;
// 描画する目盛りの幅
int display_segment = data_max_value / display_segment_num;
// 箱ひげ図の両端の線分のサイズ
float edge_size = 50.0;
// 箱ひげ図の箱のサイズ
float box_size = 100.0;
// 箱ひげ図の中心軸の位置
float center_line = (height - 2.0 * margin) /2.0;
translate(margin, margin); // 座標系の原点を移動
// x軸を描く
line(0.0, range, range, range);
// x軸に目盛りを描く
fill(0,0,0); // 文字の色を黒色にする
textSize(20); // 文字のサイズを調整
textAlign(CENTER, TOP);
for(int k=0; k<=display_segment_num; k++){
line(segment * display_segment * k, range-segment_size/2.0, segment * display_segment * k, range+segment_size/2.0);
text(display_segment * k, segment * display_segment * k, range+segment_size/2.0);
}
// y軸を描く
line(0.0, 0.0, 0.0, range);
// y軸に目盛りを描く
textAlign(RIGHT, CENTER);
for(int k=0; k<=display_segment_num; k++){
line(-segment_size/2.0, range-segment * display_segment * k, segment_size/2.0, range-segment * display_segment * k);
text(display_segment * k, -segment_size/2.0, range-segment * display_segment * k);
}
// 罫線を引く
stroke(192,192,192);
for(int k=1; k<=display_segment_num; k++){
line(segment_size/2.0, range-segment * display_segment * k, range, range-segment * display_segment * k);
line(segment * display_segment * k, range-segment_size/2.0, segment * display_segment * k, 0.0);
}
translate(0.0, range); // 座標系の原点を移動
scale(1,-1); // y軸方向を反転
// 散布図を作成する
stroke(0,0,0);
strokeWeight(3);
for(int i=0; i<data_num; i++){
point(segment * data_x[i], segment * data_y[i]);
}
}ソースコード1 散布図を描くプログラム
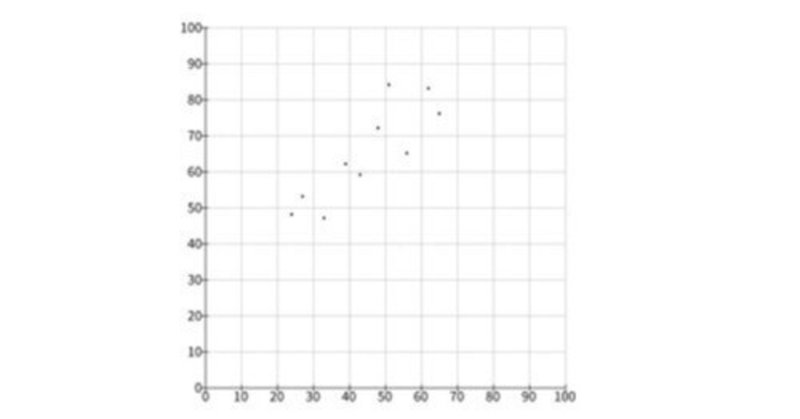
このソースコード1を、Processingの開発環境ウィンドウを開いて(スケッチ名を「drawScatterPlot」としています)、テキストエディタ部分に書いて実行すると、図1のように準備した2つの変量のデータの散布図が実行ウィンドウのキャンバスに描かれます。

この散布図を描くプログラムについての解説はしませんが、他の2つの変量のデータの散布図を描きたい場合は、ソースコード1の
// データ
int data_max_value = 100;
int data_num = 10; // データ数
float[] data_x = {43,39,51,27,65,24,62,33,56,48}; // データx
float[] data_y = {59,62,84,53,76,48,83,47,65,72}; // データyの部分を書き換えることで再利用することができます。
なお、正直なところ、散布図を描くのであれば、ソースコード1のようにProcessingを利用するよりも、Excelなどの表計算ソフトウェアを利用した方が簡単です。
散布図からの考察
図1の散布図を見ると、データの傾向として、$${x}$$の値が増えると、$${y}$$の値が増える傾向がみられます。これは、今回利用している2つの変量のデータは正の相関があることを示唆しています。以下で、共分散、相関係数を求めて、正の相関があることを数値的にも見てみます。
共分散、相関係数を求める
共分散と相関係数を求めるプログラムを作成します。アルゴリズムは共分散と相関係数の定義通りに行います。
共分散を求める関数
まず、共分散を求める関数を示します。相関係数を計算する際に、$${x}$$の平均値と$${y}$$の平均値を求める必要がありますが、平均値を求める関数は記事『高校数学をプログラミングで解く(数学I編)「3-1 データの整理、データの代表値」』で作成しましたので、そのときのcalcmeanvalue関数を利用します。
// 共分散を計算する関数
float calccovariance(
int data_num, // データ数
float[] data_x, // 1つ目のデータxの配列
float[] data_y // 2つ目のデータyの配列
){
// x及びyの平均値を計算する
float mean_x = calcmeanvalue(data_num, data_x);
float mean_y = calcmeanvalue(data_num, data_y);
float sum = 0.0;
for(int i=0; i<data_num; i++){
sum += (data_x[i] - mean_x) * (data_y[i] - mean_y);
}
return sum / data_num;
}ソースコード2 データの共分散を求める関数
相関係数を求める関数
次に、相関係数を求める関数を示します。相関係数を計算する際に、$${x}$$の標準偏差と$${y}$$の標準偏差を求める必要がありますが、標準偏差を求める関数は記事『高校数学をプログラミングで解く(数学I編)「3-3 分散と標準偏差」』で作成しましたので、そのときのcalcstandarddeviation関数を利用します。
// 相関係数を計算する関数
float calccorrelationcoefficient(
int data_num, // データ数
float[] data_x, // 1つ目のデータxの配列
float[] data_y // 2つ目のデータyの配列
){
// xとyの共分散を計算する
float covariance = calccovariance(data_num, data_x, data_y);
// x及びyの標準偏差を計算する
float sd_x = calcstandarddeviation(data_num, data_x);
float sd_y = calcstandarddeviation(data_num, data_y);
// 相関係数を計算する
float r = covariance / sd_x / sd_y;
return r;
}ソースコード3 データの相関係数を求める関数
なお、上記2つの共分散及び相関係数を求める関数は、いずれも引数にデータ数「data_num(int型)」と2つの変量のデータ「data_x(float型の配列)」、「data_y(float型の配列)」を渡すと、それぞれ共分散及び相関係数を計算して返す関数となっています。
共分散、相関係数を求めるプログラム
それでは、上記共分散、相関係数を求める関数を利用して、2つの変量のデータの共分散と相関係数を求めるプログラムを作成します。
// データの共分散と相関係数を求める
void setup(){
// データ
int data_num = 10; // データ数
float[] data_x = {43,39,51,27,65,24,62,33,56,48}; // データx
float[] data_y = {59,62,84,53,76,48,83,47,65,72}; // データy
// 共分散
float covariance = calccovariance(data_num, data_x, data_y);
println(covariance);
//相関係数
float correlation_coefficient = calccorrelationcoefficient(data_num, data_x, data_y);
println(correlation_coefficient);
}
// 平均値を計算する関数
float calcmeanvalue(
int data_num, // データ数
float[] data // データの配列
){
float sum = 0.0;
for(int i=0; i<data_num; i++){
sum += data[i];
}
return sum / data_num;
}
// 分散を計算する関数(偏差の2乗の平均値を利用)
float calcvariance(
int data_num, // データ数
float[] data // データの配列
){
// 平均値を計算する
float mean = calcmeanvalue(data_num, data);
float sum = 0.0;
for(int i=0; i<data_num; i++){
sum += (data[i] - mean) * (data[i] - mean);
}
return sum / data_num;
}
// 標準偏差を計算する関数
float calcstandarddeviation(
int data_num, // データ数
float[] data // データの配列
){
// 分散を計算する
float variance = calcvariance(data_num, data);
// 標準偏差を計算する
float sd = sqrt(variance);
return sd;
}
// 共分散を計算する関数
float calccovariance(
int data_num, // データ数
float[] data_x, // 1つ目のデータxの配列
float[] data_y // 2つ目のデータyの配列
){
// x及びyの平均値を計算する
float mean_x = calcmeanvalue(data_num, data_x);
float mean_y = calcmeanvalue(data_num, data_y);
float sum = 0.0;
for(int i=0; i<data_num; i++){
sum += (data_x[i] - mean_x) * (data_y[i] - mean_y);
}
return sum / data_num;
}
// 相関係数を計算する関数
float calccorrelationcoefficient(
int data_num, // データ数
float[] data_x, // 1つ目のデータxの配列
float[] data_y // 2つ目のデータyの配列
){
// xとyの共分散を計算する
float covariance = calccovariance(data_num, data_x, data_y);
// x及びyの標準偏差を計算する
float sd_x = calcstandarddeviation(data_num, data_x);
float sd_y = calcstandarddeviation(data_num, data_y);
// 相関係数を計算する
float r = covariance / sd_x / sd_y;
return r;
}ソースコード4 データの共分散と相関係数を求めるプログラム
このソースコード4を、Processingの開発環境ウィンドウを開いて(スケッチ名を「calcCovarianceandCorrelationCoefficient」としています)、テキストエディタ部分に書いて実行すると、図2のように、共分散、相関係数の順に
147.98
0.85602164
と、コンソールに出力されます。

共分散、相関係数からの考察
今回利用した2つの変量のデータについて、散布図から正の相関を持つことが示唆されていました。実際に、相関係数を見てみると「0.85602164」と正の値で、かつ1に近い値を持っているので、今回利用した2つの変量のデータについては数値的にも正の相関を持つことが示唆されます。
練習問題
以下の2つの変量のデータについて、散布図を描き、共分散や相関係数を求めて、その相関関係について考察せよ。
$$
x : 78,63,86,54,92,57,95,69,81,73 \\
y : 32,29, \ \ 4,48, \ \ 2,37,13,41,26,15
$$
まとめ
今回は、数学Iで学ぶ「データの相関」について、2つの変量のデータの散布図を描くプログラムとそれらのデータの共分散と相関係数を求めるプログラムを作成し、データの相関関係について考察しました。
まず、最初に散布図を描いてそこから相関関係について考察を行いました。散布図の作成はExcelのような表計算ソフトウェアなどを利用した方が便利です。ただ、散布図を描くプログラムをProcessingのような、本来向いていないプログラミング言語で作成することは勉強になりますので、今回作成したプログラム(ソースコード1)について変数の値を変更してみながら理解を深めていってもらいたいです。
次に、共分散と相関係数を計算することで相関関係について考察を行いました。今回利用した2つの変量のデータは比較的わかりやすいデータで、相関係数が1に近い値を持っていたので、正の相関を持つことが示唆されました。実際のデータはもっとわかりにくいデータも多いので、そう簡単に相関関係を見ることができないことが多いのですが、様々なデータについて統計処理を行いつつ、いろいろな観点からデータを見ていくことで少しずつデータ処理の能力が身についていきます。データサイエンティストのような仕事を行う方はこういう経験をできるだけ多く積んでいくことをお勧めします。
参考文献
改訂版 教科書傍用 スタンダード 数学I(数研出版、ISBN9784410209178)
この記事が気に入ったらサポートをしてみませんか?