
#コンピュータ談義 #演算高速化アイデア #2次元レジスタ #2次元演算モデル #思いつきヨタ話

私が80年代後半の頃、私的に温めていたアイデアです。
マシン語レベルでCPU を扱う場合は、レジスタ構成が重要になります。
8bit CPU (Z80、MC6800) の頃は限られたハードウェア・リソースからレジスタ数も少なく、用途も決められている事が多かったです。
(私は68派でしたので、Z80 の裏レジスタには羨ましさを感じていました😝)
Wiki から引用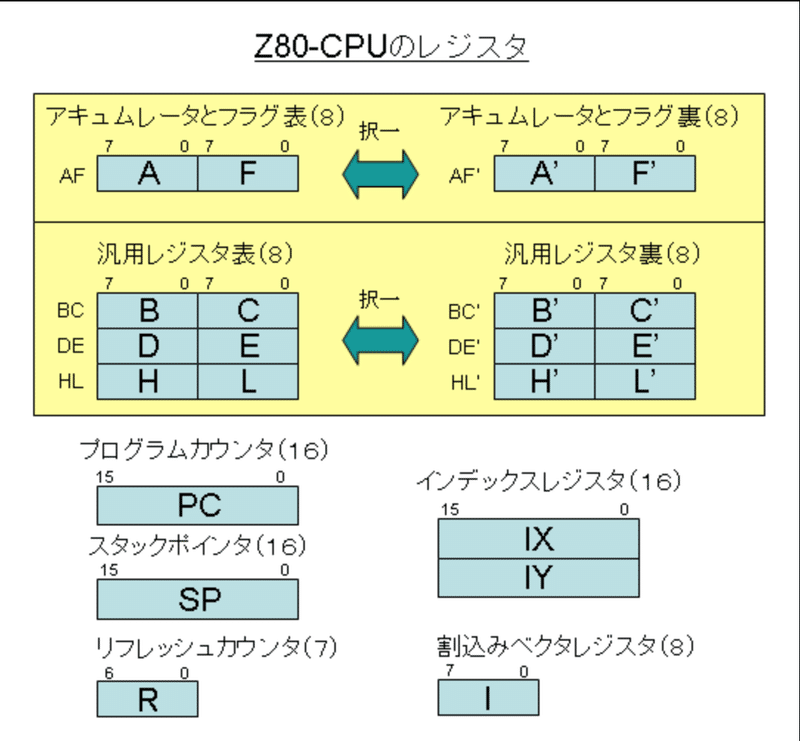
32bit RISC CPU が一般的になって来た頃は、32bit幅の汎用レジスタが32本というのが一般的になりました。
実際には32本のレジスタというのはプログラミングモデル的な話で、高速化の為にもっと多くの物理レジスタを内部的に実装(レジスタ・リネーミング)していているような処理系(CPU)も多くありました。
一般的に汎用レジスタは r(0)からr(31) の様に1次元的に定義されています。
なので、r(1)とr(2) の値を足してr(3) に代入するというニーモニック(演算指示)は下記の様になります。
add r(1),r(2),r(3);
この方式の制約は、一つのニーモニックで一つの演算器(この場合は加算器)しか動作させられない事です。
>>>ハードウェア的拡張 始め
現在はハードウェア側の工夫により、依存関係の無い複数の命令を同時に実行(スーパースケーラー)させる事ができますので、
add r(1),r(2),r(3);
add r(4),r(5),r(6);
の様に記述すれば2つの加算器が同時に動作させられます。
3命令同時実行可能ならば3つ同時にです。
ただ実際こういったハードウェア的に並列度を上げるのは、せいぜい3命令までが現実的だと思われます。
<<<ハードウェア的拡張 終わり
2次元レジスタ
私のアイデアは単純で、1次元的に定義されている汎用レジスタを2次元的に定義すれば平行度を上げられるのでは無いかというものでした。
SIMD(Single Instruction Multiple Data)的拡張ですね。

論理的にr(0,0)からr(9,9) と100本のレジスタを定義して 8行8列(r(1,1)からr(8,8))の行列として扱おうという事です。
そしてそれに見合う数、8つの演算器(加算器、乗算器、除算器...)を用意して同時に実行させれば1次元ニーモニックより8倍の演算速度が得られます。
ニーモニックとしては、
add r(1,*),r(2,*),r(3,*);
(少々冗長なので実際には add r(1,*),r(2),r(3) とか、add_row r(1),r(2),r(3) みたいにした方が実用的かと思います)
といった感じです。
1行目の各レジスタの値に、2行目の各レジスタの値を加えて、結果を3行目のレジスタに入れるという動作になります。
これで1命令で8個の加算器を同時実行させられます。
列方向の演算は
add r(*,1),r(*,2),(*,3);
の様になります。
プログラミングモデルとして8行8列の行列として扱えれば、一般的に使用される行列演算をニーモニック(命令)として予め用意しておいてプログラミング時の負荷を減らす事も可能です。
何故レジスタを8x8 では無く10x10 にしたかと言うと、行列へのインアウトの緩衝エリア(r(0,*),r(9,*),r(*,0),r(*,9))があるとより使い勝手が良いだろうと言う事と、行列演算として使いづらいであろう4つの角点(r(0,0), r(0,9),r(9,0),r(9,9)) を特殊用途(ステータスレジスタ、インデックスレジスタ等)として定義できるのではと考えました。
また下記の様な演算の際にも、0列と9列を使えます。
この演算を1命令で指示できますので、見通しの良い演算記述となると思います。
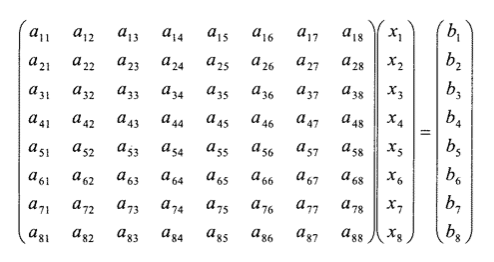
このアイデアを浮動小数点アクセレータとして考えた場合、各レジスタ幅を64bit (倍精度)にすると、内部バス幅は最低1,536bit 幅(64x8x3) になってしまいますが、現在の半導体プロセスなら何とかなるでしょう。
メモリバスも一度に1行(列)のデーターを引っ張って来られるようにすると、512bit 幅(64x8) 必要になります。
80年代の頃はあれこれ色々と考えても、どうしてもハードウェア制約上メリットを得られる考え方ではありませんでしたが、今なら何とかなるかと思いヨタ話として記述してみました。😝
付け足し...
90年代に実装が始まったインテルCPU のMMX が既にこう言った考え(SIMD)を先取りしています。
最初MMX の説明を見た時には、当時のハードウェアリソースに対するプログラミングモデルとして何てバランスの良い実装だろうと感心しました。
64bit 幅のfpu レジスタを8bit レジスタ8 個として分割し、1命令で8演算を同時に行える様にしていました。
最初の実装では単純な2進数演算(それも8bit)に限定されていましたし、結局1次元方向しか並列度を拡張できませんでしたが、MMX 拡張により音声データー処理や画像処理速度が飛躍的に向上した事は素晴らしい成果だと思います。
最近のGPU の低レベルの実装アーキテクチャを知りませんが、ひょっとすると既に実現されているかも知れません。
この記事が気に入ったらサポートをしてみませんか?