3分ではじめる機械学習

こんにちは。GMOペパボ データサイエンティストの zaimy です。
ディープラーニングなどの発達によって機械学習は数年前から著しい盛り上がりを見せており、AI・人工知能などの言葉を生活の中で聞くことも増えた昨今、機械学習モデルの実装を自分で試してみる方も多いのではないでしょうか。
先日、マネージドクラウドでは、機械学習やデータサイエンスの分野で頻繁に利用される Python が利用可能になりました。Python には pyenv, venv, pipenv などの環境管理の仕組みや Anaconda などのディストリビューションがあり、どれを選択するかを含めて環境の構築や運用には少し慣れが必要ですが、マネージドクラウドでは独立した Python 環境をコンテナとしてサクッと作成することができます。
また、プログラムの実行結果を対話的に確認したり、コードや画像を埋め込んだドキュメントを作成できる Jupyter Notebook をマネージドクラウドで起動しておくことで、どこからでも常に同じデータ分析環境にアクセスすることが可能になります。
そこでこの記事では、マネージドクラウドで簡単な機械学習モデルを実装する方法について、以下の通り環境構築から順を追ってご紹介します(タイトルの「3分」は環境構築が完了するまで約3分という意味です)。
1. Python プロジェクトの作成とパッケージのインストール
2. 使用するデータの読み込み
3. 決定木の構築と評価
4. 決定木の可視化
「機械学習に興味はあるけれど、どうすれば自分で試せるのか分からない...」という方はぜひご一読ください。
アヤメの花を決定木で分類する
今回挑戦するタスクは「アヤメの花の分類」です。統計学や機械学習に触れたことのある方にはおなじみのデータかもしれません。3種類のアヤメについて花弁の長さと幅、がくの長さと幅を測定したデータを用いて分類モデルを構築し、新たなアヤメの測定値からその種類を予測することを目指します。
予測にはシンプルな機械学習の手法である決定木を用います。決定木では、ある特徴について「はい」「いいえ」で答えられる質問を階層的に持つ木構造を学習します。複雑なデータセットについては性能を発揮しづらい一方で、木構造を可視化できモデルの理解が容易などのメリットがあるため、今回はこれを採用しました。
Python プロジェクトの作成とパッケージのインストール
それでは、環境構築を始めましょう。Jupyter を使用したデータ解析基盤の作成 に沿ってインストールを行ってください。Python のバージョンは 3.7.1 を選択しましょう。
Jupyter Notebook の準備ができたら、プロジェクトのページにある SSH コマンドでコンテナへログインしてから、Python の機械学習パッケージである scikit-learn とデータ分析パッケージの pandas をインストールします。記事執筆時点では scikit-learn 0.20.1 と pandas 0.23.4 を利用しました。
$ pip install --user scikit-learn pandas
使用するデータの読み込み
Jupyter Notebook で Python 3 のノートブックを新規作成して、アヤメの花のデータを読み込みましょう。
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
pd.DataFrame(iris.data, columns=iris.feature_names)
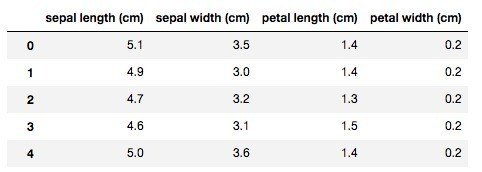
iris はディクショナリに似た Bunch クラスのオブジェクトで、次のキーと値を持ちます。
- DESCR: データセットの説明
- feature_names: 特徴の説明のリスト
- data: 測定値(花弁の長さ、花弁の幅、がくの長さ、がくの幅)の NumPy 配列
- target_names: 花の種類の名前のリスト
- target: 花の種類の NumPy 配列
data と target に格納されている値を使ってモデルを学習させますが、学習後のモデルが未知の測定値に対して正しく予測を行えるか評価する必要があります。そこで、データを「訓練データ」と「テストデータ」に分割して、前者をモデルの学習に利用し、後者でモデルが正しい予測を行えるか評価することが一般に行われます。scikit-learn では train_test_split 関数を用いることで、ランダムにデータを並べ替えた上で分割を行うことができます。今回は実行する度に結果が変わらないように random_state パラメータに任意の値を与えます。
また、機械学習では、花弁の長さのような特徴を表す値を「特徴量」、花の種類のような値を「ラベル」または「クラス」と言い、scikit-learn では特徴量を X で、ラベルを y で表す慣習があります。これに沿ってデータを分割するコードは次のようになります。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=2)決定木の構築と評価
それでは、決定木に訓練データを学習させましょう。木が分岐する際の基準値が全く同じになった場合はランダムに分岐が行われますが、今回は常に同じ結果を得るために random_state パラメータに任意の値を与えます。訓練データの学習は fit メソッドで行います。
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(random_state=0)
tree.fit(X_train, y_train)
学習が終わったら、score メソッドで訓練データとテストデータに対する予測精度を見てみましょう。
print("Accuracy on training data: {}".format(tree.score(X_train, y_train)))
print("Accuracy on test data: {}".format(tree.score(X_test, y_test)))

訓練データに対する精度が 100% となっていますが、これは訓練データを完全に分類できるまで木の成長が進んでいるからです。このような状態は「過剰適合」「過学習」と呼ばれ、新しいデータを入力した時に上手く分類できない=汎化性能が低いモデルになっています。そこで、max_depth パラメータで木の深さを指定することで、完全に訓練データに適合する前に成長を止める「事前枝刈り」を試してみます。
tree = DecisionTreeClassifier(max_depth=3, random_state=0)
tree.fit(X_train, y_train)
print("Accuracy on training data: {}".format(tree.score(X_train, y_train)))
print("Accuracy on test data: {}".format(tree.score(X_test, y_test)))
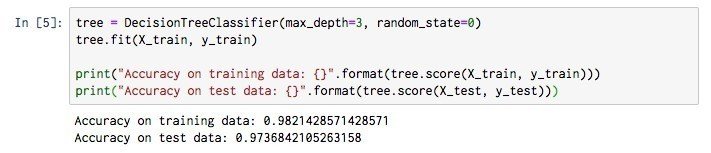
木の深さを3に制限することで、訓練データへの適合度合いがやや下がりましたが、テストデータに対する精度を向上させることができました。
決定木の可視化
モデルがどのように分類を行っているのかを知るために、決定木を可視化してみましょう。export_graphviz 関数を使って、ドット言語で表現された決定木を出力することができます。
from sklearn.tree import export_graphviz
export_graphviz(tree, out_file="dotfile", class_names=iris.target_names, feature_names=iris.feature_names, impurity=False)コンテナ上に作成された dotfile を Jupyter で開いて File > Download をクリックしてダウンロードします。ダウンロード後に、GraphViz などのソフトウェアで画像に変換しましょう。
# mac の場合
$ brew install graphviz
$ cd ~/Downloads/
$ dot -T png dotfile -o iris-decision-tree.png
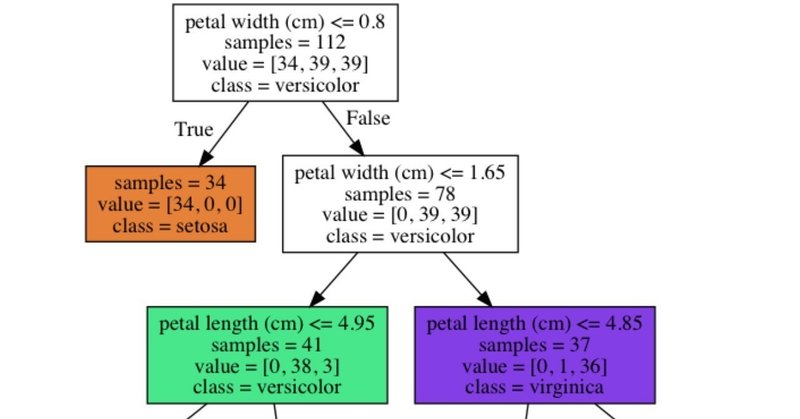
$ open iris-decision-tree.png以下のように決定木を可視化することができました。特徴量とその値の大小が質問になっており、「はい」「いいえ」で答えていくことでアヤメの花の種類を予測できることが分かります。
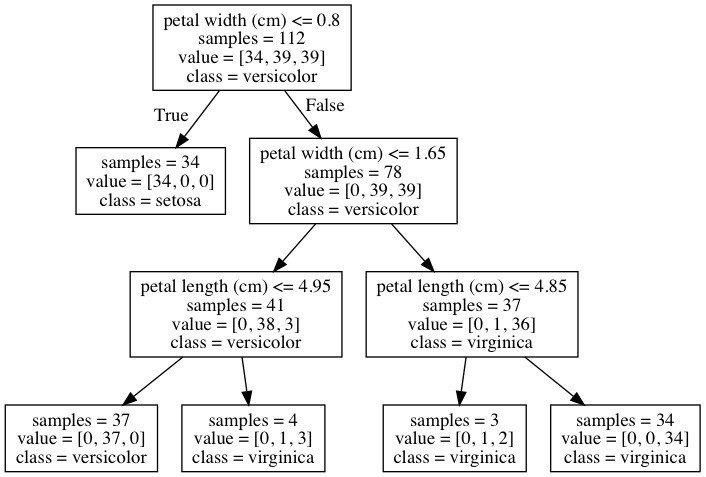
これで、新しく見つけたアヤメの花についても、特徴量(花弁の長さ、花弁の幅、がくの長さ、がくの幅)を測定することで種類を予測できるようになりました。
まとめ
この記事では、マネージドクラウド上で簡単な機械学習モデルを実装する方法をご紹介しました。マネージドクラウドでは Django などの web フレームワークを簡単に利用できるため、機械学習を行い、その結果を可視化して表示する web アプリケーションなども作成することが可能です。機械学習用途のOSライブラリのインストールなど、ご要望があればお気軽にお問い合わせください。
また、マネージドクラウドは2018年12月31日まで無料で使えるキャンペーンを実施中です。この機会にマネージドクラウドで機械学習をはじめてみてはいかがでしょうか。アカウントの登録はマネージドクラウド公式サイトからどうぞ。