Pythonでの分析はじめの一歩: データの可視化にチャレンジ

GMOペパボ データサイエンティスト(絶賛修行中)のyrarchiです。
今日は、Pythonでデータ分析を学びはじめて半年の私が、ウェブブラウザでデータ解析ができるJupyter Notebookを使って、簡単な分析にチャレンジしてみたいと思います。
Jupyter Notebookを使うと、段階的にプログラムを実行し、その実行結果を確認しながら進めることができます。試行錯誤しながら進められるので、私のような初心者の方にもおすすめです。
ただし、Jupyter Notebookを使うにはPython実行環境が必要で、環境の構築は少し手間がかかります。
そこで、今回はマネージドクラウドを利用します。
マネージドクラウドは、PythonだけでなくRailsやPHPなどWebアプリケーション開発環境をワンボタンで構築し、手軽に運用できるサービスです。
ローカル(自分のPC)にあるcsvデータをマネージドクラウド上で開いて、簡単な集計とデータの可視化を行うことがこの記事の目標です。
今回は、職場の所在地である福岡における気温データを例として、分析してみたいと思います。
今年の夏は大変暑かったですが、今年福岡に引っ越してきたので、あの暑さが例年どおりなのか、あるいは特別暑かったのか、判断がつきません。そこで、例年の気温と比較することで、その点を明らかにしてみたいと思います。
データは気象庁の過去の気象データ・ダウンロードより取得しました。なお、使用したデータは以下の条件で取得しています。
- 地点:福岡県を選択→福岡を選択
- 項目:日別値を選択→日平均気温を選択
- 期間:2018年1月1日から11月30日
1. 下準備
まず、[Python] Jupyter を使用したデータ解析基盤の作成を参照して、マネージドクラウドでJupyter Notebookを使えるようにします。
Jupyter Notebookが使えるようになったら、必要なパッケージをインストールします。今回は、以下の2つのパッケージを使用します。
- pandas : データの加工や入出力を行えます
- matplotlib : データをグラフ化できます
まず、プロジェクトのページにあるSSHコマンドでログインします。(ターミナルで、プロジェクトのSSH / SFTP → SSHコマンドに記載のsshからはじまるコマンドを実行します)
そして、上記の2つのパッケージをインストールします。
$ pip install --user pandas matplotlib
次に、データを準備します。
ホームディレクトリにcsvというフォルダを作り、そこにローカルのcsvファイルをアップロードします。


2. Jupyter Notebookで分析していく
ここまで準備ができたら、Jupyter Notebookを開いて分析をしていきます。
まず、先ほどインストールしたパッケージを使うため、インポートします。
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline%matplotlib inlineは、Jupyter Notebook上でグラフを表示させるためのマジックコメントです。
次に、先ほどアップロードしたcsvデータを読み込みます。
df = pd.read_csv("./csv/temp_fukuoka_2018.csv")まずは、データを表示してみたいと思います。
最初から5行目までを表示するには、下記のようにします。
df[:5]Jupyter Notebook上では、下記のような表示になります。Inが実行したコードで、Outにその結果が表示されます。

データは左から日付、その日の平均気温、平均気温の平年値となっています。
日付データについて、型を確認してみるとstr(文字列)になっているので、変換しておきます。
type(df["date"][0])
# str
df["date"] = pd.to_datetime(df["date"], format="%Y/%m/%d")
type(df["date"][0])
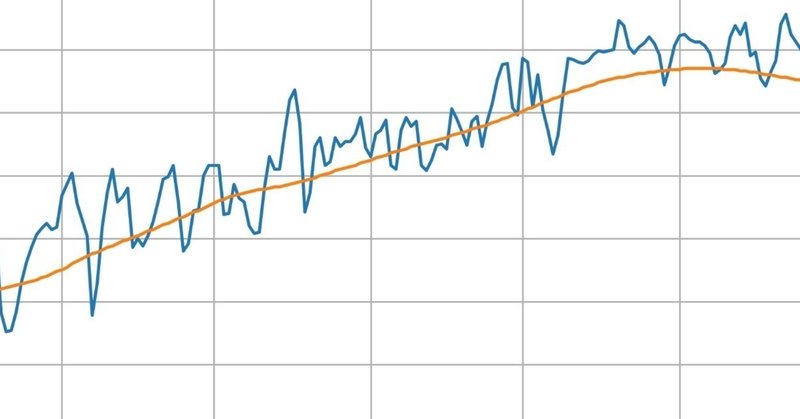
# pandas._libs.tslibs.timestamps.Timestampそれでは、データの概要を確認するため、 平均気温とその平年値をプロットしてみます。
plt.figure(figsize=(16, 4))
# ave_tempとave_temp_normalをプロットする labelは凡例での表示名の指定
plt.plot(df["date"], df["ave_temp"], label="ave_temp")
plt.plot(df["date"], df["ave_temp_normal"], label="ave_temp_normal")
plt.xlabel("date")
plt.ylabel("ave_temp")
plt.legend() # 凡例を表示する
plt.grid() # 補助線を表示する
plt.show()
今年の平均気温は、おおむね平年値の辺りを前後しているように見えます。 しかし、7月中旬〜8月にかけては平年値を超えていることが多く、例年より暑い日が多かったという認識でもよさそうです。
もう少し詳しく見るため、月ごとに、平年値より平均気温の高かった日と低かった日の比率を出してみることにします。 まず、平均気温とその平年値との差を計算する列を作ります。
df["diff_ave_temp"] = df["ave_temp"] - df["ave_temp_normal"]次に、月ごとにその差がプラスかマイナスかで件数を数え、割合を計算した表を作ります。
# 月とdiff_ave_tempの符号で件数を集計する
df_diff = pd.crosstab(df["date"].dt.month, df["diff_ave_temp"] > 0, rownames=["month"])
df_diff.rename(columns={False : "minus", True : "plus"}, inplace=True)
#件数から割合を計算する
df_diff["minus_rate"] = round(df_diff["minus"] / (df_diff["plus"] + df_diff["minus"]), 3) # roundは数値を四捨五入する関数
df_diff["plus_rate"] = round(df_diff["plus"] / (df_diff["plus"] + df_diff["minus"]), 3)
df_diff
この例年より平均気温が高かった/低かった割合をグラフにしてみます。
plt.figure(figsize=(10, 4))
plt.bar(df_diff.index, df_diff["minus_rate"], label="minus_rate")
plt.bar(df_diff.index, df_diff["plus_rate"], bottom=df_diff["minus_rate"], label="plus_rate")
plt.xlabel("month")
plt.ylabel("rate")
plt.legend(bbox_to_anchor=(1, 1)) # bbox_to_anchorは凡例の位置の調整のため
plt.grid()
plt.show()
今年は、冬の時期(1・2月)には例年より平均気温が低い日が多かった一方、春〜夏の時期(3~9月)には例年より高い日が多く、特に8月は8割以上の日で 平年値より高かったことがわかりました。
以上より、例年と比べ今年は暑い夏だったと思っても良さそうです。あれが福岡の一般的な暑さだとつらいなと思っていたので、少しほっとしました。
以上、ごく簡単ではありますが、データの読み込み、集計とグラフ化の方法を見てきました。
ロリポップ!マネージドクラウドは年末まで無料キャンペーン中なので、ぜひ手元にあるcsvデータを使って、データの可視化をやってみてください!