
図書館蔵書の半自動予約 by Python ③

実施手順
デスクトップにPythonをインストール必要なライブラリのインストールGoogle Spread sheetのAPIキーの取得Google Spread sheetのJSON化プログラムをご自身の環境に合わせて書き換える → ここ
プログラム
from playwright.sync_api import sync_playwright, expect
#from google.cloud import sheets
import requests
def login_and_take_screenshot(playwright, url, username, password, url2):
browser = playwright.chromium.launch()
context = browser.new_context()
page = context.new_page()
page.goto(url)
page.wait_for_load_state("load")
# ログイン処理
page.click('text=ログイン')
page.fill('[name="txt_usercd"]', username)
page.fill('[name="txt_password"]', password)
page.click('text=ログイン')
# spreadsheet data
response = requests.get(
'https://sheets.googleapis.com/v4/spreadsheets/10xxxxxxxxxxxQ/values/sheet1?key=Axxxxxxxxxxxxxng'
)
response.raise_for_status()
data = response.json()
# 検索キーワードをテキストボックスに入力
for index in range(1, len(data['values'])):
if data['values'][index] is None:
break
keyword = data['values'][index][0]
page.fill('[name="txt_word"]', keyword)
page.get_by_role('button', name='検索').click()
page.get_by_role('link', name='予約かごへ').click()
page.get_by_role('link', name='トップメニュー').click()
page.goto(url2) #MyLibrayの予約かご
page.get_by_role('link', name='全選択').click()
page.get_by_role('button', name='通常予約').click()
page.get_by_role('button', name='予約').click()
# スクリーンショットの取得
page.screenshot(path='screenshot.png')
# ブラウザを閉じる
browser.close()
if __name__ == '__main__':
# 以下はログインに必要な情報
url = 'https://www.------.jp/'
username = 'xxxxxxxx'
password = 'yyyyyyyy'
url2 = 'https://www.zzzzzzz.jp/'
with sync_playwright() as p:
login_and_take_screenshot(p, url, username, password, url2)
ご自身の環境に合わせて書き換える
プログラムを実行させるには、ご利用されるサイトのHTMLソースに合わせた変更、基本情報の入力、予約までのフローの変更などが必要です。(ページの下の方に詳細を記載しています。)
お手数ですが、ご自身の環境に合わせて修正を行ってください。
なお、現時点では、検索結果で対象の本が、1冊だけの場合と、複数冊の場合で、条件分岐するコードを含んでいません。
ですので、検索結果が複数出てきそうなタイトルの場合、spreadsheetに「著者とタイトル」や、「タイトルと出版年」など複数の情報を記載して、検索結果が1冊に絞り込まれるようにして下さい。
ご参考:プログラムの変更方法や、変更箇所
HTMLソースの確認方法
DFCを受講された方でしたら、覚えておられる方も多いかと思います。
ご自分の使われるサイトを開いて、右クリックして”検証”で、ソースコードが表示され、矢印のアイコン(下図👇)をクリックすると、カーソルが合わさった要素に色が付き、デベロッパーツール側のHTMLソースもハイライト表示されます。
① HTMLソースに合わせた変更
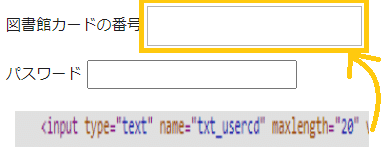
例えば、17行目の"page.fill('[name="txt_usercd"]', username)"というコードは、下図の黄色い枠にカード番号を入力するコードです。
当方の図書館のサイトでは、この枠は"txt_usercd"という名前のHTML要素になっています。こういった箇所を、利用しているウェブサイトの要素に合わせて変更してください。
②基本情報の入力
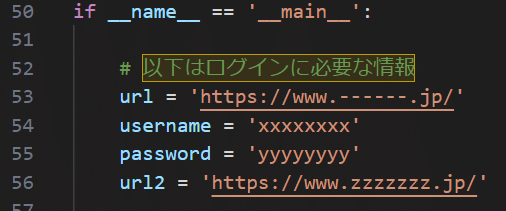
53行目はログイン画面のURL、54と55行目にログイン情報、
56 行目はログイン後のURLになっています。
書き換えてください。
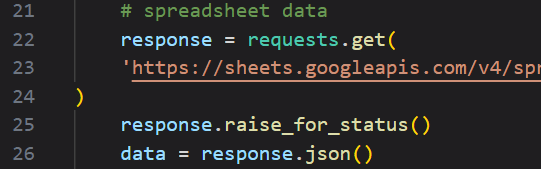
また、手順3で準備したJSONを取得するURLを23行目に入力してください。
③検索から予約までのフローを変更
当方の図書館サイトでは以下の流れで予約が完了しますので、プログラムもその順序で書いています。こちらも変更して下さい。
サイトのログインフォームにusernameとpasswardを入力、ログイン。
「検索窓にタイトル等を入力し”検索”→”予約かご”→”トップメニュー”」という操作を繰り返す。
最後に”予約かご”→”全選択”→”通常予約”→”予約”で予約完了。
④Spread sheetのデータ取得範囲の変更
30行目で、Spreadsheetの”A2からデータがあるセルまで”と範囲指定しています。ご自分のSpreadsheetに合わせてください。
この辺りは、AIにコードを書いてもらいました。

準備できたらプログラムを実行してみてください
分かりにくい点などフィードバック頂けますと、勉強になりありがたいです。
この記事が気に入ったらサポートをしてみませんか?