pythonで仮想通貨② 暗号通貨自動売買MLbotのエッジを探す。【イーサリアム(ETH-USDT) ロジスティック回帰】

暗号通貨の自動売買botにおいて、エッジは無限にあります。
しかし、収益化出来るエッジは中々ネットには落ちていません。
今回はロジスティック回帰という【※枯れた技術】でありながら、イーサリアムの自動売買において、収益化できそうなエッジである『p値のズレ具合』を見つけたっぽい気がするので、ご紹介したいと思います。
※枯れた技術とは、価格が安くなった古い技術の新しい使い道を考えることで、新しい商品を生み出すという手法のこと。任天堂の立役者:横井軍平の理論
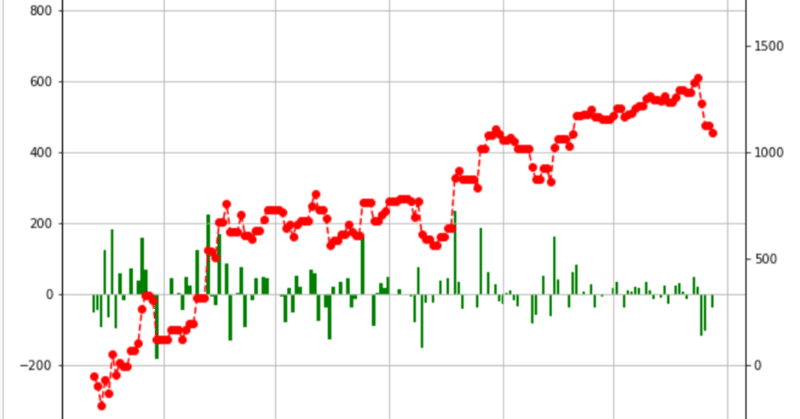
まず初めに損益グラフを見て頂きたいと思います。
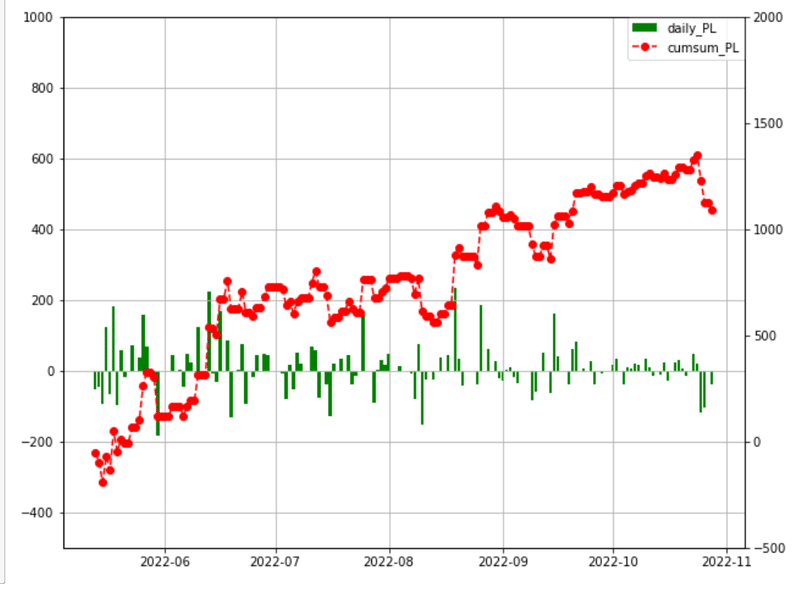
これは、2022年5月13日~2022年10月30日(本日)まで稼働させたBOTの収益グラフです。👇
・左側の縦軸がデイリーの損益(緑色のグラフ)
・右側の縦軸が期間累計の損益(赤色のグラフ)

とりあえず、1,090ドル(≒161,208円 レート:1ドル=147.9円)のプラスで終えています。
5ヵ月で約16万円の利益なので、月額32,000円の収益という計算になります。
まぁ、悪くない金額だと思料します。
1.MLbotのロジック公開
ロジックは単純です。
売買単位は1回のトレードで1ETH(イーサリアム)です。
ロジスティック回帰を使います。
説明変数:昨日の【始値、終値、出来高、曜日】を設定。
目的変数:当日の【上昇、下落】確率です。
確率が60%を超えるときだけ売買します。
例
・上昇確率が60%を超える:当日の始値でイーサリアム現物購入。終値で売却。
・下落確率が60%を超える:当日の始値でイーサリアムショート。終値で決済。
これだけです。
ロジックは単純なのですが、二点ポイントがあります。
それは、
1.『訓練データとテストデータの各予測値をt検定し、p値が概ね50%以上になるように学習させる。※このとき時系列に学習させない!学習期間はバラバラにする』
2.学習期間は長すぎない方がよい(大体40日~60日程度の学習が良さそう)。
ということです。
これが冒頭で述べたエッジである『p値のズレ具合』です。
仮説検定
H0:訓練データとテストデータの予測値に何ら関係は無い。
H1:訓練データとテストデータの予測値に何らかの有意性がある。
というt検定に置いて、学習の結果算出された予測値が有意ではない(つまりH0が採択される)、場合にワークすることが多いです。
これは、例え訓練データの正解率が高く、テストデータの正解率が低い場合でも、予測値に差がないことを意味します。つまり、訓練データの正解率が高ければ、テストデータの予測値も低いとは言えない、という状況を確認するために行います。
また、学習期間が長すぎると、確率が50%付近に収束してきて、60%以上の確率が算出されなくなります。
2.ロジック考察
データは下記サイトより取得させて頂きます。
http://nipper.work/btc/index.php?market=BitMEX&coin=btcjpy-quarterly-futures&periods=86400&after=1420070400
ライブラリインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns曜日と翌日のイーサリアムが上昇したか、下落したかをyに正解として格納。
df = pd.read_csv("ETH.csv")
df
# 上記サイトのBittrex時間は24時間ずれるため、shiftで補正。
df["Date"] = df["Date"].shift(1)
df
import datetime as dt
import locale
df["week"] = pd.to_datetime(df["Date"], format="%Y-%m-%d")
df["week_num"] = df["week"].dt.dayofweek
df["week"] = df["week"].dt.day_name()
df
# 前日との差分をDiffへ格納
df["Diff"] = df["Close"].diff()
df["y"] = df["Diff"].apply(lambda x: 1 if x > 0 else 0).shift(-1)
df = df.dropna()
# CSV保存
#df.to_csv('history.csv')
dfここまでの結果👇

値上がり日数と値下がり日数を見てみます。
print((df["y"] == 1).sum()) #値上がり日数
print((df["y"] == 0).sum()) #値下がり日数値下がり日数が若干多いです。

次に、説明変数を作るために、新しいデータフレームdfsに前日のデータを格納します。
dfs = df[["Date", "Open", "Close","Volume", "week_num", "y"]]
#dfs = dfs.set_index('Date')
#dfs = dfs.reset_index()
dfs["yes_Open"] = dfs["Open"].shift(1)
dfs["yes_Close"] = dfs["Close"].shift(1)
dfs["yes_Volume"] = dfs["Volume"].shift(1)
dfs = dfs.dropna()
dfsここまでの結果👇
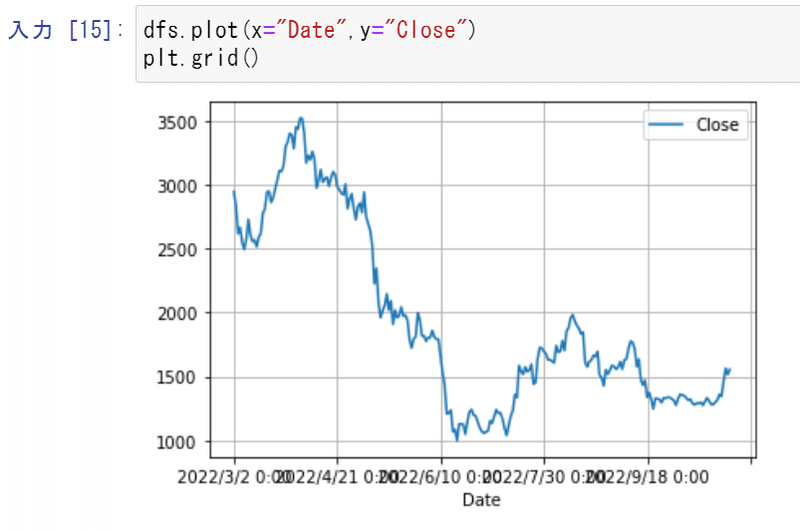
ついでに期間中のイーサリアムの値動きが下記です👇
5月頭から急落しています。
ここからロジスティック回帰の準備です。ライブラリをインポート。
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import roc_curve, auc
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
X = dfs[["yes_Open","yes_Close", "yes_Volume", "week_num"]]
y = dfs.loc[:,'y']
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size = 0.3, random_state = 42)
#説明変数は標準化しておく(あとで回帰係数を比較するため)
scaler_X = StandardScaler()
X_train = scaler_X.fit_transform(X_train)
X_test = scaler_X.transform(X_test)
#モデルの構築と学習
lr = LogisticRegression()
model = lr.fit(X_train, y_train)
#訓練データ,テストデータに対する予測
y_pred_train = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
#最初の10サンプルだけ表示してみる
print(y_pred_train[:30])
print(y_pred_train.size)
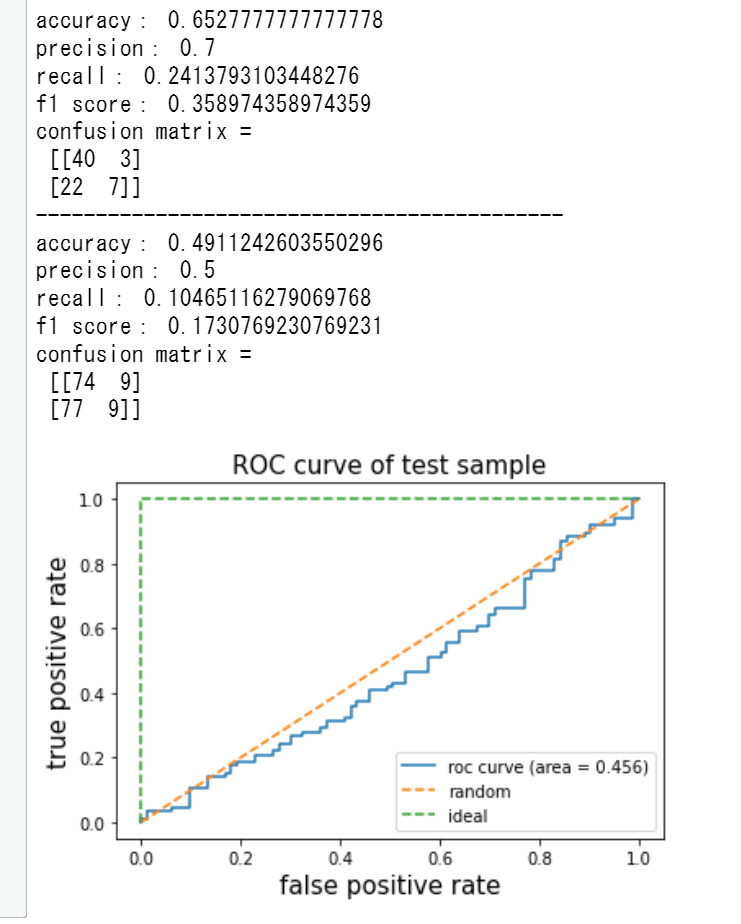
print(y_pred_test.size)ここまでの結果👇

モデル評価の為可視化👇
#訓練データ
print('accuracy:', accuracy_score(y_true=y_train, y_pred=y_pred_train))
print('precision:', precision_score(y_true=y_train, y_pred=y_pred_train))
print('recall:', recall_score(y_true=y_train, y_pred=y_pred_train))
print('f1 score:', f1_score(y_true=y_train, y_pred=y_pred_train))
print('confusion matrix = \n', confusion_matrix(y_true=y_train, y_pred=y_pred_train))
print("--------------------------------------------")
#テストデータ
print('accuracy:', accuracy_score(y_true=y_test, y_pred=y_pred_test))
print('precision:', precision_score(y_true=y_test, y_pred=y_pred_test))
print('recall:', recall_score(y_true=y_test, y_pred=y_pred_test))
print('f1 score:', f1_score(y_true=y_test, y_pred=y_pred_test))
print('confusion matrix = \n', confusion_matrix(y_true=y_test, y_pred=y_pred_test))
#ROC曲線の描画、AUCの計算(ROC曲線の下側の面積)の計算
y_score = lr.predict_proba(X_test)[:, 1] # 検証データがクラス1に属する確率
fpr, tpr, thresholds = roc_curve(y_true=y_test, y_score=y_score)
plt.plot(fpr, tpr, label='roc curve (area = %0.3f)' % auc(fpr, tpr))
plt.plot([0, 1], [0, 1], linestyle='--', label='random')
plt.plot([0, 0, 1], [0, 1, 1], linestyle='--', label='ideal')
plt.legend()
plt.title('ROC curve of test sample',fontsize=15)
plt.xlabel('false positive rate',fontsize=15)
plt.ylabel('true positive rate',fontsize=15)
plt.show()ROC曲線は0.5以下。ダメダメです👇
しかし、訓練データの正解率は65%とまずまずです。
予測値同士のt検定に置いて、テストデータの予測値がこれと差が無ければ、テストデータの正解率が低くても、このエッジを採用するというロジックです。
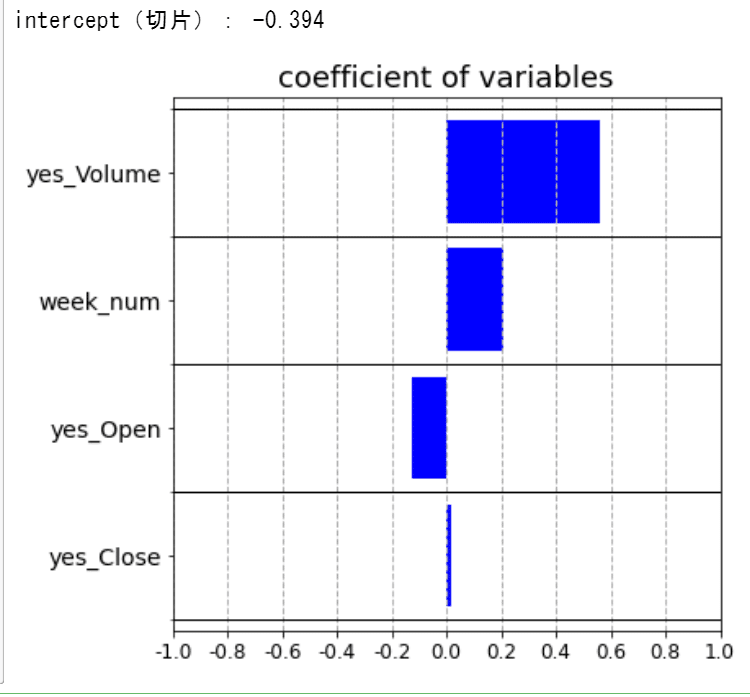
切片(intercept)の表示
print("intercept(切片):", round(lr.intercept_[0],3))
#回帰係数を格納したpandasDataFrameの表示
df_coef = pd.DataFrame({'coefficient':lr.coef_.flatten()}, index=X.columns)
df_coef['coef_abs'] = abs(df_coef['coefficient'])
df_coef.sort_values(by='coef_abs', ascending=True,inplace=True)
df_coef = df_coef.iloc[-10:,:]
#グラフの作成
x_pos = np.arange(len(df_coef))
fig = plt.figure(figsize=(6,6))
ax1 = fig.add_subplot(1, 1, 1)
ax1.barh(x_pos, df_coef['coefficient'], color='b')
ax1.set_title('coefficient of variables',fontsize=18)
ax1.set_yticks(x_pos)
ax1.set_yticks(np.arange(-1,len(df_coef.index))+0.5, minor=True)
ax1.set_yticklabels(df_coef.index, fontsize=14)
ax1.set_xticks(np.arange(-10,11,2)/10)
ax1.set_xticklabels(np.arange(-10,11,2)/10,fontsize=12)
ax1.grid(which='minor',axis='y',color='black',linestyle='-', linewidth=1)
ax1.grid(which='major',axis='x',linestyle='--', linewidth=1)
plt.show()係数を見てみます👇
このモデルでは、昨日の出来高と曜日の影響が大きい様です。
df_model = pd.DataFrame(index=["Open", "Close","Volume", "week_num"])
df_model["偏回帰係数"] = model.coef_[0]
print("intercept: ", model.intercept_)
df_model
ここでt検定を行います。👇
p値は0.49で見事に棄却されます。
# Welchのt検定
from scipy import stats
sample_a = y_pred_train # 条件1の全データの配列
sample_b = y_pred_test # 条件2の全データの配列 (ndarray)
p = stats.ttest_ind(sample_a, sample_b, equal_var=False)
display(p)
print("p値 : {}".format(p[1]))
そして予測値の確率を算出します👇
# 確率算出の際は、predict_proba()メソッドを利用
# テストデータの予測確率
Y_pred_proba = model.predict_proba(X_test)
# データ出力
df_proba = pd.DataFrame()
df_proba["値下がり確率(y=0)"] = Y_pred_proba[:,0]
df_proba["値上がり確率(y=1)"] = Y_pred_proba[:,1]
print(df_proba)
確率をそのままデータフレームへ格納。新たなデータフレームdfGを作成👇
dfG = dfs[72:]
dfG["値下がり確率(y=0)"] = Y_pred_proba[:,0]
dfG["値上がり確率(y=1)"] = Y_pred_proba[:,1]
dfG値下がり確率がとても多いように感じます👇
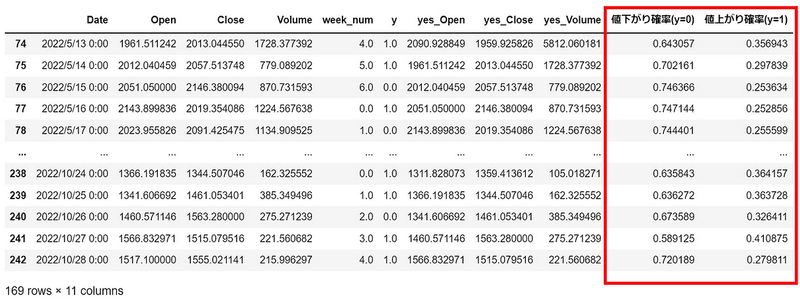
それぞれ何日あるか調べます。👇

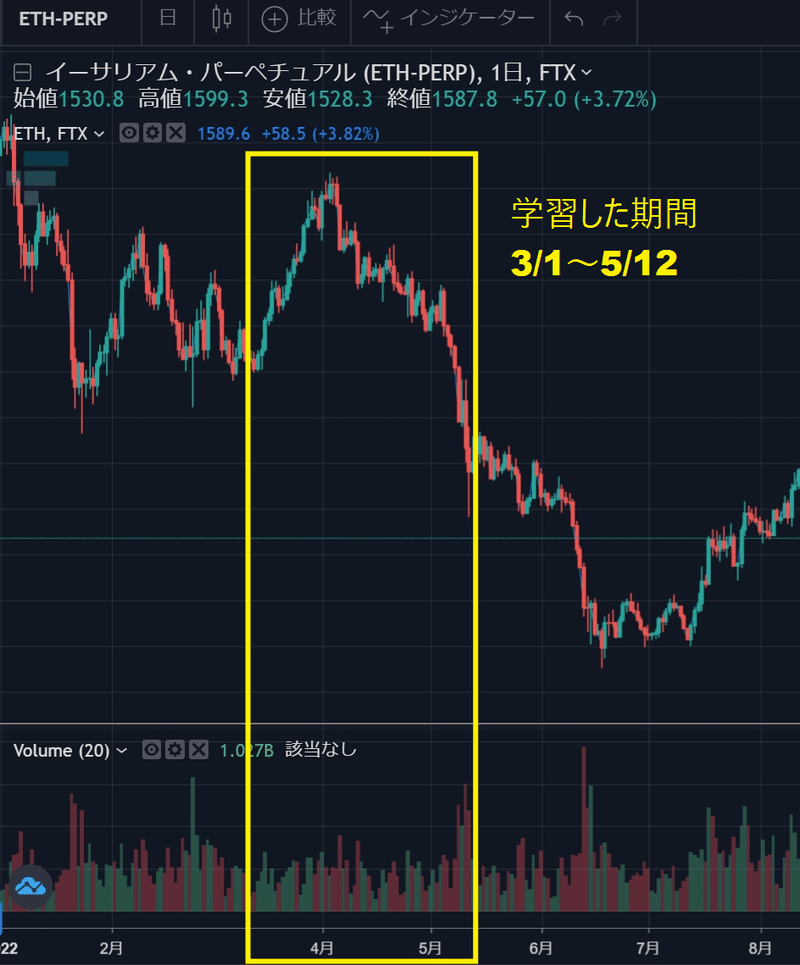
本来であれば、学習した期間は、下記の様になるはずです👇。
しかし、今回はsklearnの(shuffle=True)なので、下記ではなくランダムに学習しています!!!
ここで売買ロジックとその結果をデータフレームに格納します。👇
def Short(row):
if row["値下がり確率(y=0)"] > 0.6:
row["short_in"] = row["Open"]
row["short_out"] = row["Close"]
return row
def Buy(row):
if row["値上がり確率(y=1)"] > 0.6:
row["buy"] = row["Open"]
row["sell"] = row["Close"]
return row
#1行ごとにbuy/sell()を呼び出す
dfG = dfG.apply(Short, axis=1)
dfG = dfG.apply(Buy, axis=1)
dfG = dfG.fillna(0)
dfG["short_PL"] = dfG["short_in"] - dfG["short_out"]
dfG["buy_PL"] = dfG["sell"] - dfG["buy"]
dfG["short_PL_cum"] = dfG.short_PL.cumsum()
dfG["buy_PL_cum"] = dfG.buy_PL.cumsum()
dfG["PL"] = dfG["short_PL"] + dfG["buy_PL"]
dfG["PL_cum"] = dfG.PL.cumsum()
dfG.head(12)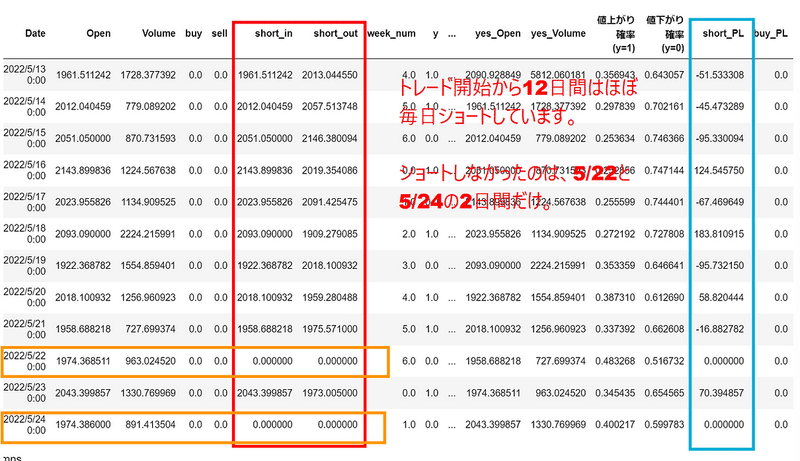
月別の結果を集計してみます👇
dfG["Date"]=pd.to_datetime(dfG["Date"])
dfG["月別集計"] = dfG.Date.apply(lambda x: x.strftime('%Y/%m'))
grouped = dfG.groupby("月別集計")
month_records = pd.DataFrame({"現物利益": grouped.buy_PL.sum(),
"ショート利益": grouped.short_PL.sum(),
"合算利益": grouped.PL.sum()})
print("---------------------------------------------------")
print( month_records )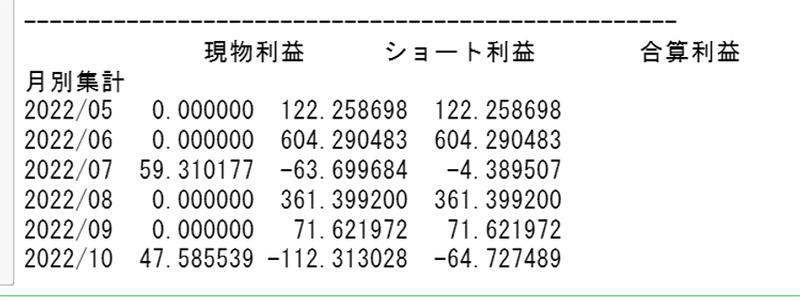
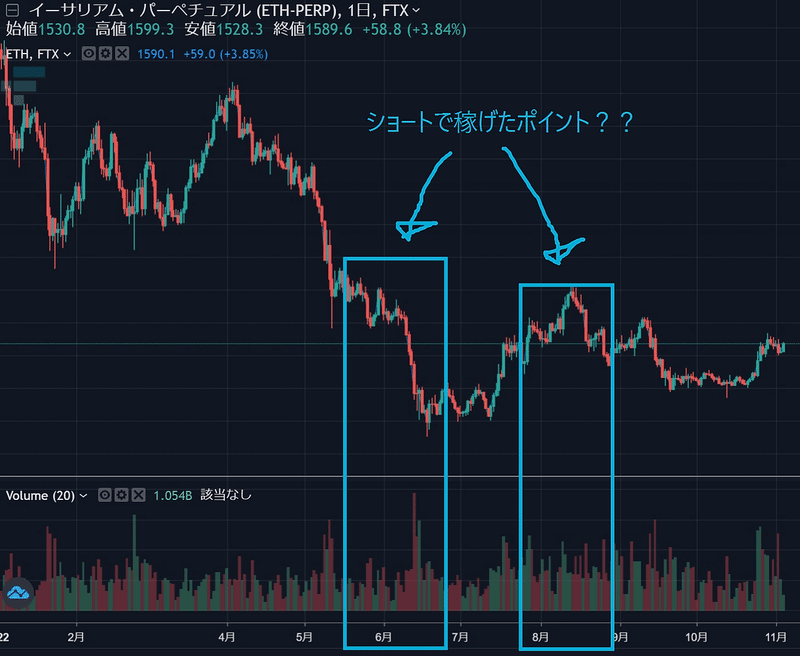
6月と8月にショートで大きく利益を伸ばしています。
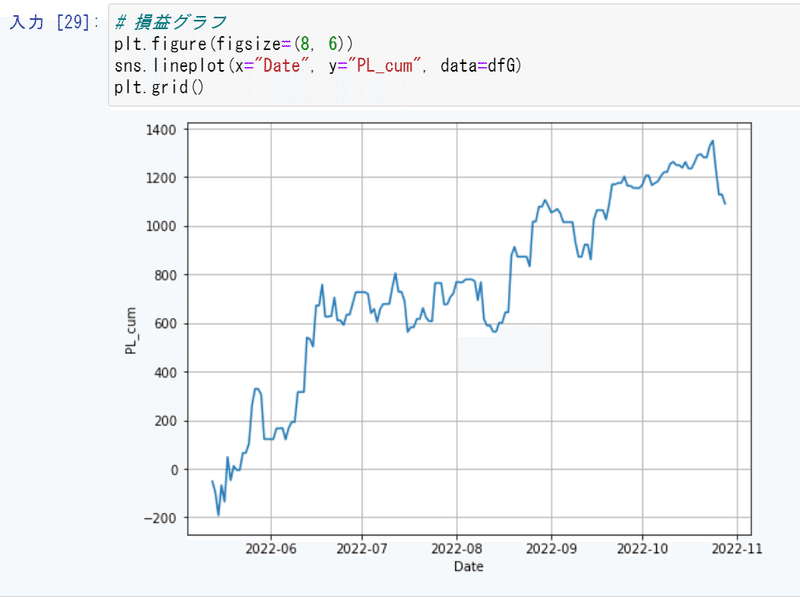
損益グラフを見てみます👇
最初こそマイナスですが、その後は徐々に盛り返しています。
デイリーと累計の損益グラフをまとめて表示します👇。
dfG = dfG.set_index('Date')
fig, ax1 = plt.subplots(1,1,figsize=(10,8))
ax2 = ax1.twinx()
ax1.bar(dfG.index, dfG["PL"],color="green",label="daily_PL")
ax2.plot(dfG["PL_cum"],color="red",marker ="o", linestyle = "--",label="cumsum_PL")
ax1.set_ylim(-500,1000)
ax2.set_ylim(-500,2000)
handler1, label1 = ax1.get_legend_handles_labels()
handler2, label2 = ax2.get_legend_handles_labels()
ax1.legend(handler1+handler2,label1+label2,borderaxespad=0)
ax1.grid(True)
fig.show()冒頭で表示したグラフです👇。
3.改良点(交差検証や実装など)
改良点はいくらでもありますが、今回のロジックの場合、交差検証も行っていませんし、botのAPIやスリッページなどの取引所対策のコードも一切検証されていません。しかもランダムに値動きを学習しています(未来を学習したといっても過言ではありません)。
たまたまワークしている様に見えた、に過ぎないというのが実情です。
本来であれば、有意性のある説明変数(エッジ)を見つけて、検証期間を5つとかに区切って、t検定。それぞれのp値が0.05以下かつp値の平均値も0.05以下なら、リリースする、などの検証を行うべきでしょう。
しかし、今回のような単純なロジスティック回帰でも、p値をエッジに向けるのではなく、予測値に向けることで、訓練データの説明変数の妥当性を担保することが出来るような気がしました(気がしただけです(´;ω;`)ウゥゥ)。
株価のようにランダムウォークな時系列分析においては、統計学の使い方にも正攻法以外の使い方があっても面白いのかな?と思いましたので記事にしました。
以上です。
e^iπ + 1 = 0