
Googleスプレッドシート SORTN関数 超応用例(意外と使えるユニークな関数)

Googleスプレッドシートの SORTN関数 を取り上げてみます。
使い方によっては、UNIQUE関数とTAKE関数とSORT関数を組み合わせるような、
重複統合+上からの行数指定取得+並び替え処理
これを一発で賄える高機能関数。それがSORTN関数です。
SORTN関数は 「ソートンかんすう」って読み方・・・でいいのかな。こういう読み方ってホントわからないですよね。
MOD関数を昔「モッドかんすう」って読んでて恥ずかしい思いをした記憶がw(モデュラス が正しいっぽいけど、モッドでも間違いではないそうです)

Excelには存在しない SORTN関数は、簡単に言えば 並べ替えをした上から〇件を抽出する 関数です。
これだけならわざわざ単独で 紹介するほどではないんですが、実は 第3引数の 「同等項目の表示モード」を使うことで、他の関数とは一味違ったユニークな処理が可能となります。
多くのサイトでは SORT関数のオマケ程度にしか扱われていないSORTN関数の 真の力と超応用例を見ていきましょう!
前回までは 全3回でSORT関数を取り上げてきました。
Googleスプレッドシート 日本語並び替えのふしぎ

本題の SORTN関数に入る前に、SORT関数シリーズで触れなかった Googleスプレッドシートの 日本語(漢字)並び替えのふしぎ について、少し書きたいと思います。
SORT関数と QUERY関数では 日本語(漢字)並び替えが 違う
上の画像、A列の 苗字をSORT関数で昇順に並び替えたものが C列に出力されてるんですが、なんとなく日本人としてはしっくりくる並びですよね?
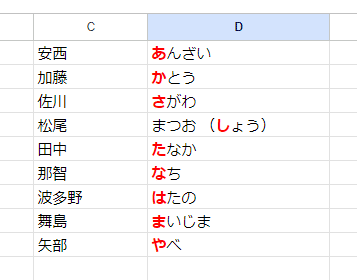
納得する理由は、こんな感じで漢字の(音読み)の頭文字できちんと あいうえお順になっているからです。
この例だと 唯一 「松尾」の松は「まつ」ではなく音読みが「しょう」になるので、さがわ と たなかの 間に入ってしまってますが、まあ仕方ないと納得できます。
このルールでの並び替えは、今回紹介する SORTN関数も同様ですし、機能の「範囲を並べ替え」やフィルタでの並べ替えでも同じ結果になります。

=QUERY(A1:A9,"order by A asc")
しかし QUERY関数の oder by 句を使った 日本語の並び替えは、まったく違う結果が返ります。日本人なら
これが昇順・・・だと・・・ (BLEACH風)
ってなる不思議な並びです。
このQUERY関数の漢字の並び替えロジックは、文字コードを確認すると理解できます。
ユニコードと JISコード

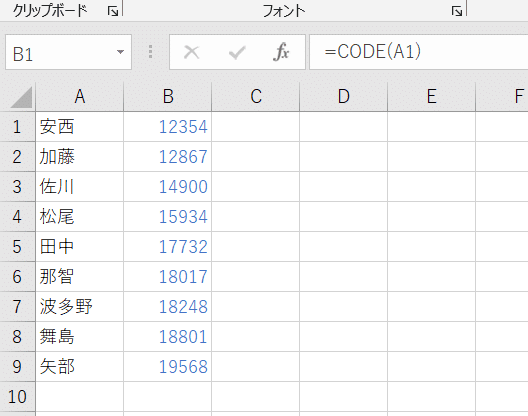
QUERY関数で並び替えた 漢字(苗字)の隣 D列に CODE関数を入れると、この数字が 昇順に並んでいるのがわかります。
ちなみに CODE関数は セル内の先頭の文字のコード値を返す関数で、「佐川」だったら「佐」という文字のコード値を返します。
そして、Googleスプレッドシートの CODE関数は ユニコード値を返す仕様となっています。
一方、インストール版の Excelの CODE関数は そのパソコンで使用されている文字セットに対応したコード値、日本であれば 通常は JISコードの値を返す関数となっています。
SORT関数の昇順 にした際の 漢字の並びは、音読み順っぽいけど 実際は JISコード値の昇順になってるってわけです。
なるほど・・・。えぇー!?(マスオさん風)
何が驚きかというと、Googleスプレッドシートには JISコードを返すような関数は存在しないからです。
ちなみに Excelにも Googleスプレッドシートにも CODE関数とは別に UNICODE関数という ユニコード値を返す関数が存在します。
Googleスプレッドシートの場合は、CODE関数も ユニコード値を返すので、CODE関数もUNICODE関数も同じ数値が返ります。
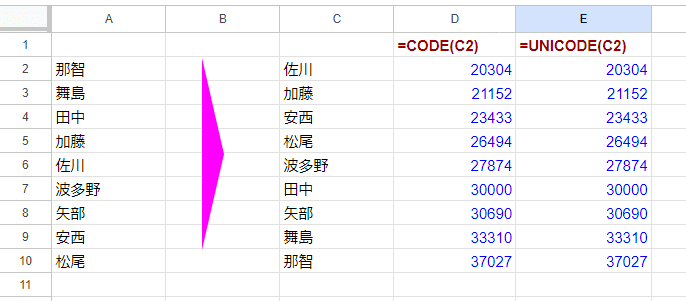
でも JISコード値を返す関数はありません。
それなのに SORT関数がJISコードベースで並べ替えできるってことは、どこかに ローカルの文字コード情報を持ってるってことなのかなと・・・。
じゃあ、JISコード値を返す関数あってもいいんじゃね?
と思うわけです。
ちなみに SORT関数や機能の並べ替えの基準となる 文字コード値は スプレッドシート の言語と地域の 設定に依存するようで
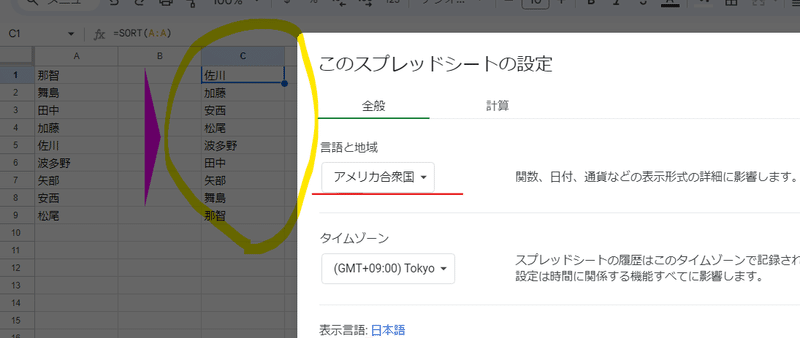
このように 日本 → アメリカ と変えた場合は、SORT関数の日本語の並べ替え が QUERY関数と同じユニコード値ベースになってしまいます。
日本語並べ替えに関する、ちょっと 不思議なお話でした。
それでは SORTN関数いってみましょう!
SORTN関数の基本
SORTN(範囲, [n], [同等項目の表示モード], [並べ替え基準列1, 昇順1], ...)
n - [省略可 - 既定値は 1] 返す項目の数です。0 より大きな値を指定してください。
同等項目の表示モード - [省略可 - 既定値は 0] 同等項目をどのように表示するかを示す数字です。
0: 範囲内を並び替えて最初の n 行(n 行に満たない場合はすべての行)を表示します。
1: 最初の n 行(n 行に満たない場合はすべての行)を表示し、さらに n 行目と同じ値の行があれば追加で表示します。
2: 重複する行を削除したうえで、最初の n 行(n 行に満たない場合はすべての行)を表示します。
3: 最初の一意の n 行(n 行に満たない場合はすべての行)と、それぞれの重複行を表示します。
冒頭で書いた通り SORTN関数は、指定したルールで並べ替えた上で、上位〇個だけ表示させるといった処理ができる関数です。
ちなみに、SORTN関数に該当する関数は Excelには存在しません。
単に 「並べ替えた上で、上位〇個だけ表示」だけだったら、他の関数を組み合わせれば わりと簡単に代用できます。
SORTNがユニークなのは 表示モード(第3引数)を切り替えることで、並べ替えた値に同じもの(重複)があった場合にどのように出力するかを指定できる点です。
サンプルデータを使って、まずは各モードを理解しましょう。
シンプルな使い方 (表示モード 0)
第2引数 である n (結果として返す件数)を省略した場合、並べ替えたデータの一番上を返す挙動となります。
また、第3引数の 表示モードを省略した場合は モード 0 となり、重複があっても上からシンプルに指定した件数 n を返します。
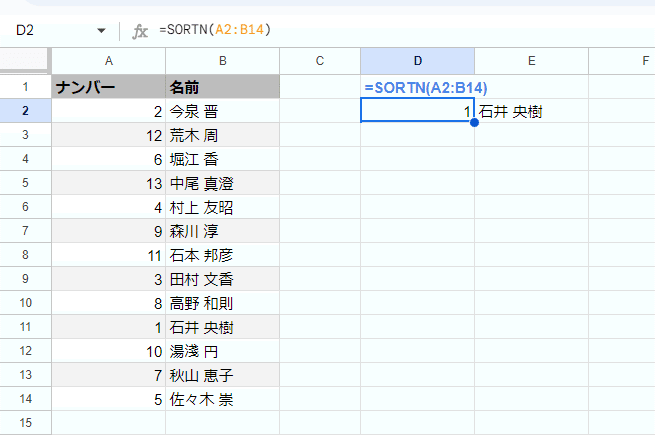
=SORTN(A2:B14)
↓ これと同じ意味
=SORTN(A2:B14,1,0,1,1)
SORTと同様に 第1引数(範囲)以外は省略可能で、その場合は
・範囲の一番左の列を
・昇順でで並び替えた上で
・一番上の1件目 だけを表示
となります。
同じことは 他の関数でも出来ますが
SORT関数 + INDEX関数
=INDEX(SORT(A2:B14),1)
MIN関数 + XLOOKUP関数(SORTも使わない処理)
=XLOOKUP(MIN(A2:A14),A2:A14,A2:B14)
と、複数関数の組み合わせで 記述が少し長くなります。
対象とするデータを少し変えましょう。
ミニお題もありますんで、チャレンジする方は 以下のサンプルデータをスプレッドシートにコピペしてお使いください。
氏名 スコア クラス
中濱 賢 90 A
工藤 真那 30 B
早川 隆則 80 C
佐々木 達也 95 B
高杉 恭子 60 C
安宅 佐知子 50 A
佐藤 彩子 95 B
松井 裕美 80 C
岡田 敦 40 B
佐藤 裕子 30 C
大内 卓也 50 B
菅原 強 95 A
毛利 小五郎 30 D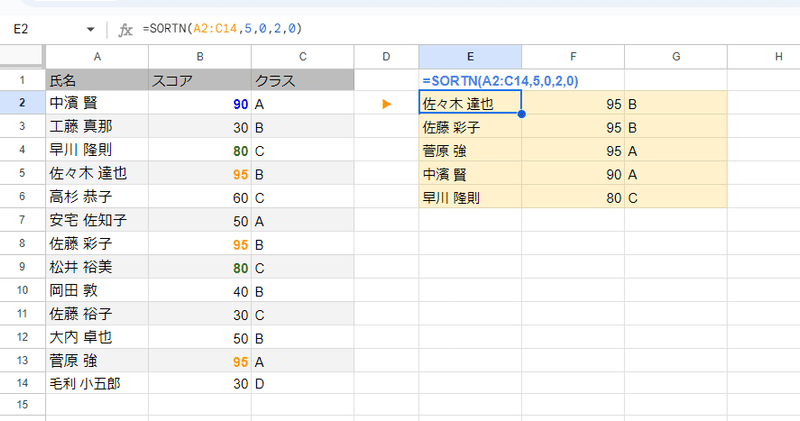
「A2:C14 の表データから スコアが高い順で 上位5名を抽出したい」といった場合は
=SORTN(A2:C14,5,0,2,0)
A2:C14の範囲から
上から 5 つ
モード0で取り出す
2列目を 0(降順)で並び替えた上で
このような記述になります。
では、ここでミニお題です。
Q. これと同じ結果をSORTNを使わずに得る為には、どのような式をつくればよいでしょうか?
幾つか方法があります。思いつくだけ作成してみましょう。
↓↓
回答です。
SORT + CHOOSEROWS
=CHOOSEROWS(SORT(A2:C14,2,0),SEQUENCE(5))
SORT + FILTER
=FILTER(SORT(A2:C14,2,0),SEQUENCE(ROWS(A2:C14))<=5)
QUERY orde by 句、limit句 利用
=Query(A2:C14,"order by B desc limit 5")
こんな方法があります。(他にもあります)
QUERY以外はいずれも3つ以上の関数を組み合わせた式ですし、Query関数も 並び替えの order by に加え、返す結果件数を制限する limit 句 を組み合わせており、初心者には難しいかもしれません。
SORTN関数だと非常にシンプルに記述できており、並べ替えて上位〇個だけ抽出という処理が簡単に出来る関数だってことがわかりますね。(その為に用意された関数なんで当然なんですが)
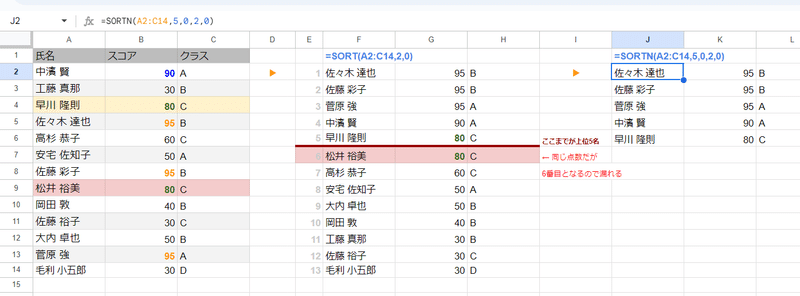
左の表の赤塗りつぶし、 松井 裕美さん に着目してみましょう。
スコアは80と 取り出したデータの5番目の 早川さんと同点ですが、そこは一切考慮されず 単純に 上から5件だけを取りだしている為、並びが上だった 早川さんの方が5番目のデータとして出力されています。
これが 重複(同位)を考慮しない モード0 の挙動となります。
同位があった場合に追加出力する (表示モード 1)
モード0 の結果だと
同じスコアなのに 結果から漏れてしまった 松井さんが可哀そうよ!松井さんも入れてあげなよ! 男子たち!
って、口うるさい いいんちょ に言われそうですよね。
そんな時に使えるのが モード1です。
モード1は 「さらに n 行目と同じ値の行があれば追加で表示します。」
という説明の通り、3件と指定した場合でも同位のデータがあれば3件を超えても追加表示するモードとなっています。
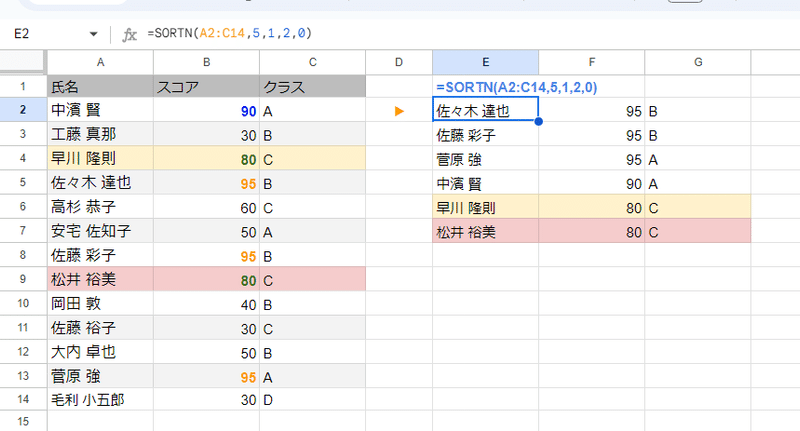
=SORTN(A2:C14,5,1,2,0)
単純に 先ほどの 第3引数の箇所を 1と変えるだけで、このように 第5位のスコア 80の同位である 松井さんも含めて 合計 6件のデーが出力されます。
では、またここでミニお題です。
Q. これと同じ結果をSORTNを使わずに得る為には、どのような式をつくればよいでしょうか?
少しだけ考えてみましょう
↓↓
回答の1例 はこちら。
=SORT(FILTER(A2:C14,B2:B14>=LARGE(B2:B,5)),2,0)
まず 5番目に大きいスコアを LARGE関数で取得します。
LARGE関数は 〇番目に大きい要素を取得する関数です。
ちなみに 同位(重複)があった場合は以下のように
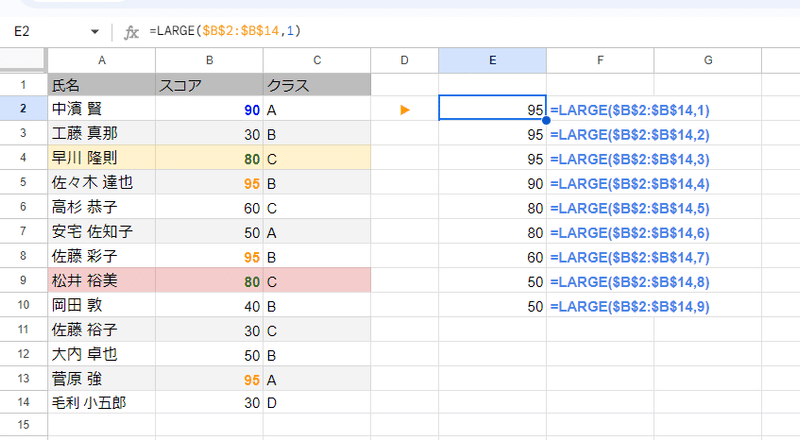
1番目に大きい数 95、2番目 95、3番目 95、4番目 90、5番目 80、6番目 80 ・・・ と 重複する値のそれぞれが 〇番目に大きいという扱いになります。SORT関数で降順に並べたものを 上から1,2,3…と連番を振ったイメージです。
FILTER関数で B列が LARGE(B2:B,5) 以上でデータを絞り込んでから SORT関数で並び替えることで、SORTN関数の n=5 モード1 と同じ結果が得られます。
キーの重複を削除して 結果を返す(表示モード2)
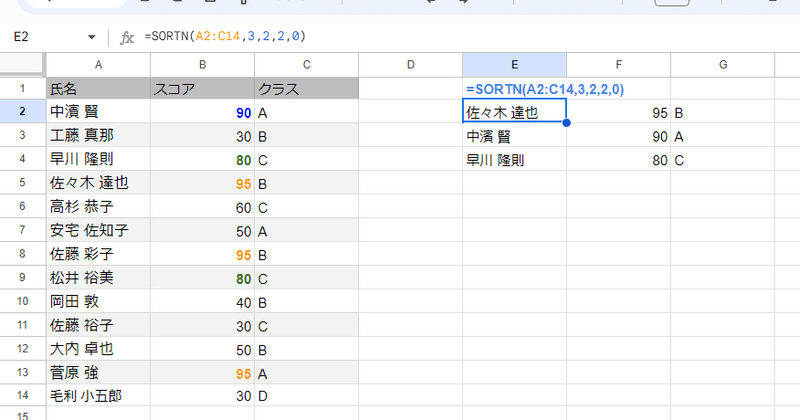
モード2は最も独特かもしれません。
「重複する行を削除したうえで、最初の n 行を表示」
というモードです。
「重複する行を削除」ってどういうこと?
少しわかりにくいですが、これは 並べ替えてから並べ替えのキー列を 部分的にUNIQUE関数にかけたイメージと思ってください。
上の画像だと 2列目 スコアを 降順に並べ替えているので

こんな処理がされて、結果として 1番高得点の 95から1人、2番目の高得点 90から1人、3番目の高得点 80から 1人の合計3人 が返るというわけです。
佐々木 達也 95 B
中濱 賢 90 A
早川 隆則 80 C
ちなみに 並べ替えのキー列を2つ指定してモード2で 5つ抽出する場合
=SORTN(A2:C14,5,2,2,0,3,1)
2列目(スコア)を降順で
3列目(クラス)を昇順で
今度は スコアとクラスの両方で重複を見るので
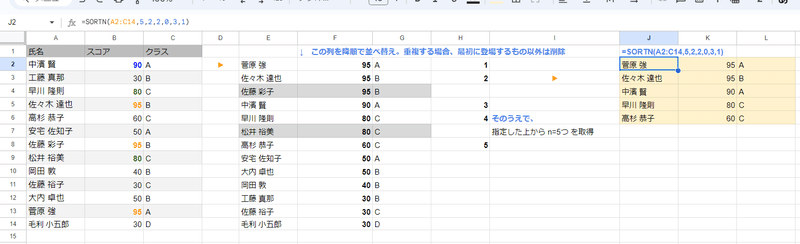
このように重複排除となる対象も変わってきます。
菅原 強 と 佐々木 達也は同じスコアですが、クラスが違うので 佐々木は重複とはみなされません。一方、佐藤 彩子 は 佐々木と 並べ替えキーである スコア、クラスともに同じなので重複となり、上に表示されている 佐々木だけが残り 佐藤は 削除対象(出力対象外)になっています。
ちなみに、このモード2を別関数で再現しようとすると結構面倒なんで、これはお題にはしないでさらっと紹介だけとします。

=SORTN(A2:C14,5,2,2,0,3,1)
↓ SORTNを使わない場合
=LET(x,SORT(A2:C14,2,0,3,1),y,FILTER(x,COUNTIFS(INDEX(x,,2),INDEX(x,,2),INDEX(x,,3),INDEX(x,,3),SEQUENCE(ROWS(x)),"<"&SEQUENCE(ROWS(x)))=0),FILTER(y,SEQUENCE(ROWS(y))<=5))
または
=LET(x,SORT(UNIQUE(B2:C14),1,0,2,1),y,FILTER(x,SEQUENCE(ROWS(x))<=5),ARRAYFORMULA(BYROW(y,LAMBDA(r,xlookup(CONCATENATE(r),B2:B14&C2:C14,A2:C14,)))))
最も独特な モード2は、実務で使うことあるのか??って思うかもしれませんが、意外とこれが使えるんです。後で活用例が登場します。
n番目までの条件に合致したものを全て返す (表示モード3)

nを 5で指定しているのに 9件も結果が返ってきました。これが モード3です。
モード3は 「最初の一意の n 行と、それぞれの重複行を表示します。」となっています。あいかわらず表現がわかりにくいですね。。
視覚化すると、モード2で 以下のように 重複として削除されていたデータが
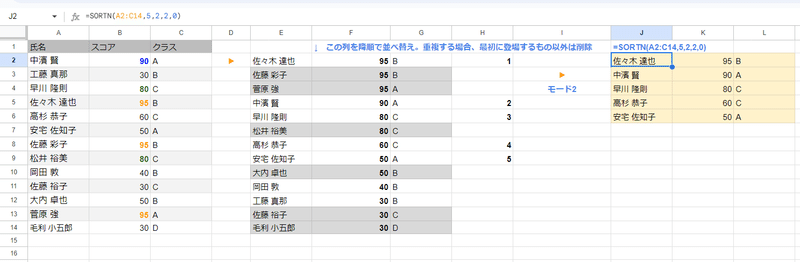
モード3だと重複も含め 条件の上から5番目までに合致するデータが全て返るわけです。

では このモード3の挙動を理解する為のミニお題です。
Q. これと同じ結果をSORTNを使わずに得る為には、どのような式をつくればよいでしょうか?
ちょろっとチャレンジしてみましょう。ヒントはモード1の時の式の応用です。
↓↓
回答です。
=SORT(FILTER(A2:C14,B2:B14>=LARGE(UNIQUE(B2:B14),5)),2,0)

モード1の時は LARGE関数をそのまま スコアに対して使いましたが、今回はUNIQUE関数で先に B列(スコア)の重複を削除して 一意のデータにしてから LARGE関数で 5番目に大きい値を取得しています。
あとは一緒ですね。
SORTN関数の モード切替のまとめ

4つのモードの 出力の違いはわかりましたでしょうか?
モード0 と 2は 指定した 件数(n)より多く結果が返ることはありませんが、1と3は n以上の件数の結果が返ることがあります。
SORTN関数のモードの違いについては、いきなり答える備忘録さんでも解説されています。
普通に 上位何個を取得したい時は、 SORTN関数の モード0を使ったり、同位のデータも含めたい時に モード1を使うといったケースが多いでしょう。
では普通とはちょっと違う使い方で、モード2、モード3は どんな時に使えるのか? ここからが SORTN関数の超応用例です!
SORTN関数 超応用例
ここまでは他の SORTN関数を紹介しているサイトとあまり変わりません。ここからが 本番です。
SORTN関数の何が便利なのか?これに触れてるサイトはほぼありません。
転スプ(転生したらSpreadsheetだった件)では、SORTN関数が単にまぎらわしい関数みたいに扱われてたりしますし、あまり評価されてないかもw
とりあえずは 1つお題を解いてみましょう。
Q1. 各クラスごとの最高得点の氏名と点数を抽出したい
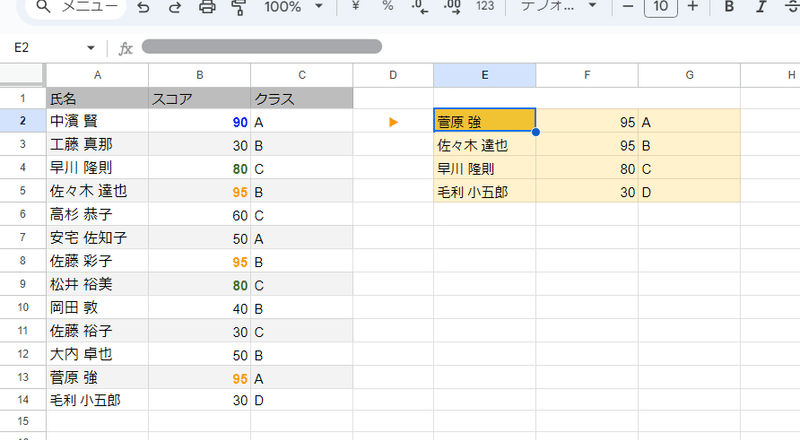
データは先ほどのものを使います。左のA2:Cの表データから 各クラス 毎の 最高得点者の氏名と その点数を取得したい。というお題です。(ただし 同じクラスに最高得点の同点者が2名以上いる場合も 1名だけ抽出でよい)
どうでしょう? 解けますでしょうか??
SORTN回のお題なんで、SORTN関数を使いそうだなってのはわかりますよね。あとは、隠している式の部分が結構短いってのもポイントです。
どうでしょうか? いけそうな方はチャレンジしてみましょう!
↓↓
ここから回答です。
↓↓
A1. 各クラスごとの最高得点の氏名と点数を抽出する
回答の前に、一緒に思考してみましょう。
SORTNを使うというヒントがなかった場合、多くの人は
MAXIFSを使う??
QUERY関数が使えそう?
この辺りを考えるんじゃないでしょうか?
もちろん出来なくはないですが、結構大変です。
そもそも MAXIFSを使うにしても、まずは UNIQUE関数で クラスの一意のリストを用意するところからですし、MAXIFSでクラスで絞り込んだ最高得点は取得できても 氏名データの取得には、また別の関数を使う必要があります。
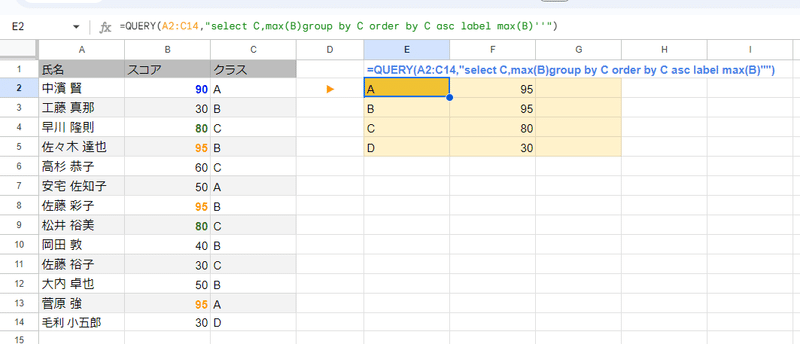
QUERY関数も同様で
=QUERY(A2:C14,"select C,max(B)group by C order by C asc label max(B)''")
QUERY関数のこちらの式でクラスごとの最高得点までは表にできるんですが、それが誰というデータは持ってこれません。
では、SORTNだったらこれが出来るのか?
こちらが回答です。

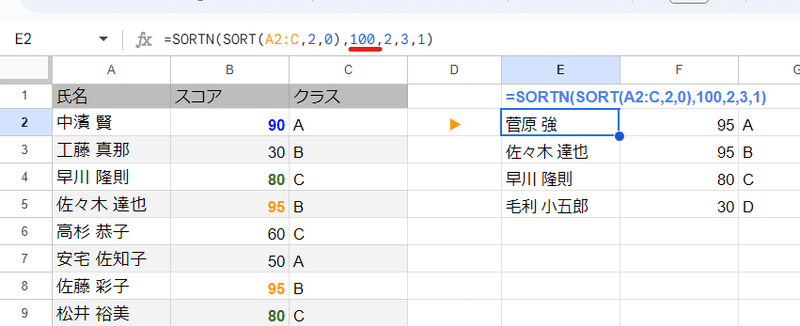
=SORTN(SORT(A2:C,2,0),100,2,3,1)
このようにシンプルに書けるんです!!
SORTNの中にSORT??ってなりますよね。解説していきましょう。
使っているのは SORTNの モード2 (重複排除)です。
この SORTN関数の モード2を使うことで、QUERY関数では出来なかった データ を ある列でグループ化(UNIQUE化)して そのグループ毎の 最大値(または最小値)の 行をまるっと持ってくることができるんです。(※ただし各グループごとに1行のみ)
まず 中のSORT関数を見ていきましょう。

2列目(スコア)を 0(FALSE 降順)で指定しているので、上のようにスコアが高い順にデータが並べ替えされます。
これをSORTNでは 3列目(クラス)を 1(TRUE 昇順)で並べ替えているのですが、SORTNではなくSORTを使うことで 並べ替えられたところまでを視覚化してみましょう。

このようにクラスごとに並んだ上で、クラス内で点数が高い順に並びました。
SORTNのモード2の重複排除は 並べ替えのキー列 (上の場合はクラス)が重複するデータがあった場合、1番目だけを残して後は削除するという挙動なので、各クラスの 一番点数の高い データ(各クラスで一番目のデータ)が出力できるわけです。
では、抽出する数 n をなぜ 100にしているのか?
厳密にやるなら 100ではなく COUNTUNIQUE(C2:C) でクラスの数を 求めてもいいんですが、SORTN関数は 「n 行に満たない場合はすべての行を表示」という挙動なので、nに十分大きな数を渡しておけば問題ありません。
式を簡略化する為に、100という 今回のケースだとクラス数ではありえない 適当に大きな数を使ったわけです。
ちなみに SORT関数で点数順にせず、SORTNで スコア順、クラス順にしたらダメなの?って思うかもしれませんが、SORTN側で スコア順、クラス順としてしまうと、スコアとクラス の両方で モード2の重複チェックがされてしまいます。
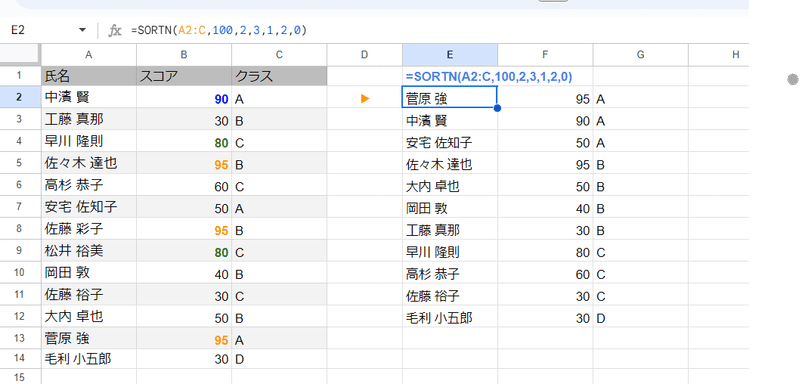
モード2を効果的に使う為には、SORTしてからSORTNという式を作る必要があるわけです。
どうでしょう、なんとなく理解できたでしょうか?
Q2. 各クラスごとに ランダムに1名選出したい
上のQ1と 先週までのSORT関数の応用例のおさらい問題です。
上の A2:B列のように クラス分けされた氏名(生徒)データがあった時、各クラスからランダムで1名選出したい時は、どのような式を作ればよいでしょうか?
※データの増減に対応できるよう 範囲は A2:Bとする
サンプルデータはこちらをご利用ください。
氏名 クラス
中濱 賢 A
工藤 真那 A
早川 隆則 A
佐々木 達也 A
高杉 恭子 A
安宅 佐知子 A
佐藤 彩子 A
松井 裕美 A
岡田 敦 A
佐藤 裕子 A
大内 卓也 A
菅原 強 B
澤 孝行 B
安藤 直之 B
山本 吉史 B
藤原 直樹 B
加瀬 香織 B
奥村 智洋 B
大城 はる B
梅野 健治 B
平澤 俊英 B
前田 久美子 B
山口 明子 C
大森 陽子 C
佐藤 沙織 C
斎藤 剛 C
境田 千賀子 C
赤岩 賢 C
森 賢一 C
武田 杏子 C
川口 ゆかり C
赤井 淳 C
石井 央樹 D
今泉 晋 D
田村 文香 D
村上 友昭 D
佐々木 崇 D
堀江 香 D
秋山 恵子 D
高野 和則 D
森川 淳 D
湯淺 円 D
石本 邦彦 E
荒木 周 E
中尾 真澄 E
高野 友宏 E
関岡 千里 E
藤原 博史 E
高橋 啓介 E
有田 孝 E
森田 高史 E
今村 秀嗣 Eやってみましょう!
↓↓
ここから回答です。
↓↓
A2. 各クラスごとにランダムに1名選出する
回答はこちら。

=SORTN(SORT(A2:B,RANDARRAY(ROWS(A2:A))*(B2:B<>""),0),100,2,2,1)
こちらが回答です。
SORT関数によるランダムな並べ替えは、SORT関数シリーズの第2回に登場しましたね。下のデータの入ってない空白行の処理がポイントでした。
SORT(A2:B,RANDARRAY(ROWS(A2:A))*(B2:B<>""),0)
先に RANDARRAY を使って データをランダムに並び替えた上で、
=SORTN( データ ,100,2,2,1)
と して各クラスの一番上だけ出力。
SORTN関数のところは 先ほどのQ1の回答と一緒です。簡単でしたかね?
Q3. 各クラスごとの最高得点の氏名 と点数を抽出したい(最高得点の同点がいる場合は複数名抽出したい)

再び Q1の お題に戻ってみましょう。
Q1 では クラスに最高得点者が2名以上いた場合でも 1名のみ抽出としましたが、やはり同じ最高得点なのに抽出されないのは可哀そうですね。
上のデータだと Bクラスの佐藤さん、Cクラスの松井さんが 先ほどの式では抽出できませんでした。
というわけで、A1の応用です。クラスごとの 最高得点者を全員抽出する式を考えてみましょう! 少し難しいです。
↓↓
ここから回答です。
↓↓
A3. 各クラスごとの最高得点の氏名 と点数を抽出する(最高得点の同点がいる場合は複数名抽出)
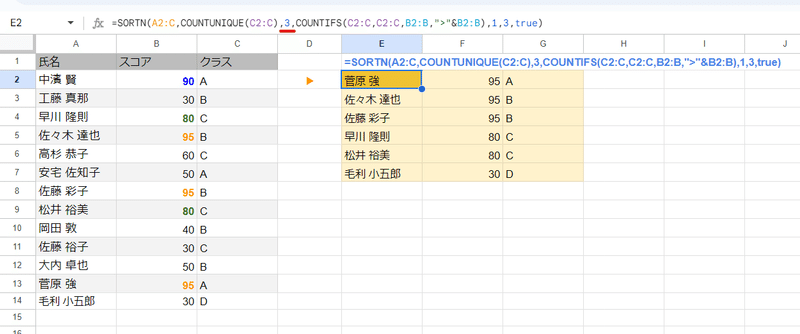
回答です。
=SORTN(A2:C,COUNTUNIQUE(C2:C),3,COUNTIFS(C2:C,C2:C,B2:B,">"&B2:B),1,3,1)
今回は SORTNのモード3 (全抽出)を使っています。
件数は COUNTUNIQUE(C2:C) でクラス数をカウントしていますが、ここが固定なら 4のようにクラスの数に変えても問題ないです。
並べ替え条件のキーは
第1 COUNTIFS(C2:C,C2:C,B2:B,">"&B2:B)
第2 3 (クラス)
と指定しています。
まず COUNTIFS(C2:C,C2:C,B2:B,">"&B2:B) でなにをやっているかを見てみましょう。
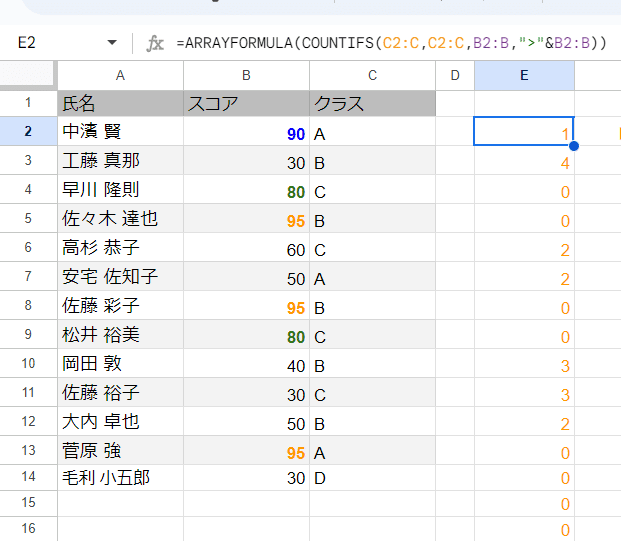
COUNTIFS(
C2:C,C2:C, // クラスが同じで
B2:B,">"&B2:B // 自分よりスコアが高い
)このような条件でカウントしています。
つまり クラスの中で一番点数が高ければ 0 が返るわけです。 ※ただし空白行も0となる
FILTERでこれを 条件に絞り込んでからSORTで並び替えでも良いんですが、
せっかくなんで SORTN関数で 第2条件をクラスとして 並べ替えて、必要な部分だけ取り出しています。
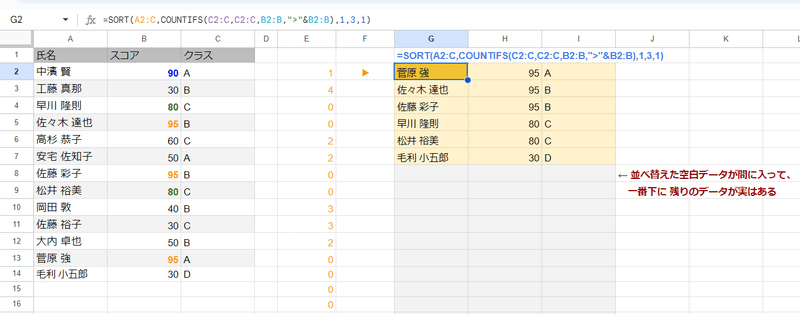
見た目上は 同じような結果を SORT関数で得ることが出来るんですが、実はこれ 結果の下にずらっと空白が入っていて、最後一番下に 残りのデータがある状態なんです。

この不要なデータを SORTNで クラス数を指定して モード3とすることで、
第1キー COUNTIFS(C2:C,C2:C,B2:B,">"&B2:B) が 0で
第2キー 3 (クラス) が A,B,C,D である
データだけに絞り込んでいるわけです。
SORTNのモード3は FILTER関数的な使い方が出来るっていう応用例でした!
SORTN関数と Googleフォーム

既に気づいてる方もいるかもしれませんが、このSORTN関数は 販売データや学校で使う生徒のデータ、そして Googleフォームから出力したデータと 相性がいいんです。
Googleフォームでの応用例
たとえば フォームの回答から、 本日のデータだけ表示や 回答者名が 〇〇さんのデータだけ表示 といったことは FILTER関数を使えば出来ます。

同じく 人ごとに 何件回答したか、商品ごとの 発注数の合計などの集計であれば QUERY関数 の出番です。
しかし、人ごとの最新の回答を見たい、商品ごとの直近の発注内容が見たいといった場合は、QUERY関数では対応できないですし、FILTER関数で式を作るのもなかなか大変です。
こういった要件には SORTN関数の モード2を使って
■人(2列目)ごとの 直近(タイムスタンプ1列目 降順)の回答データ
=SORTN(SORT(A2:D,1,0),100,2,2,1)
■商品(3列目)ごとの 直近(タイムスタンプ1列目 降順)の回答データ
=SORTN(SORT(A2:D,1,0),100,2,3,1)
と、簡単な式で 欲しい情報を取得することが出来ます。
では、最後にこのGoogleフォームのデータを使った SORTN関数の超応用問題にチャレンジしてみましょう!
Q4. フォームのデータから タイムスタンプで月毎の 商品別の 最大の発注数のオーダーを一覧にしたい
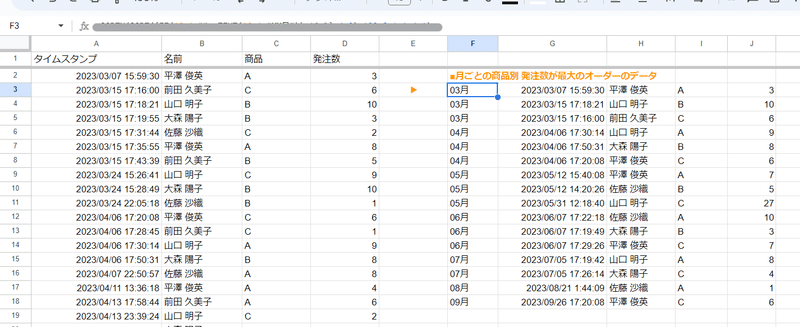
左のフォームデータから、右のような 月ごと、商品毎の最大発注数のオーダーを一覧で出力したい。というお題です。
サンプルデータはこちら
タイムスタンプ 名前 商品 発注数
2023/03/07 15:59:30 平澤 俊英 A 3
2023/03/15 17:16:00 前田 久美子 C 6
2023/03/15 17:18:21 山口 明子 B 10
2023/03/15 17:19:55 大森 陽子 B 3
2023/03/15 17:31:44 佐藤 沙織 C 2
2023/03/15 17:35:55 平澤 俊英 A 8
2023/03/15 17:43:39 前田 久美子 B 5
2023/03/24 15:26:41 山口 明子 C 9
2023/03/24 15:28:49 大森 陽子 B 10
2023/03/24 22:05:18 佐藤 沙織 B 1
2023/04/06 17:20:08 平澤 俊英 C 6
2023/04/06 17:28:45 前田 久美子 C 1
2023/04/06 17:30:14 山口 明子 A 9
2023/04/06 17:50:31 大森 陽子 B 8
2023/04/07 22:50:57 佐藤 沙織 A 8
2023/04/11 13:36:18 平澤 俊英 A 4
2023/04/13 17:58:44 前田 久美子 A 6
2023/04/13 23:39:24 山口 明子 C 2
2023/04/27 15:18:28 大森 陽子 B 7
2023/04/27 15:19:32 佐藤 沙織 A 3
2023/04/27 15:19:34 平澤 俊英 C 39
2023/04/27 15:19:35 前田 久美子 B 7
2023/04/27 15:20:19 山口 明子 B 1
2023/04/27 16:43:32 大森 陽子 B 4
2023/05/12 14:20:26 佐藤 沙織 B 5
2023/05/12 15:40:08 平澤 俊英 A 7
2023/05/12 22:42:33 前田 久美子 B 3
2023/05/31 12:18:40 山口 明子 C 27
2023/06/07 17:19:49 大森 陽子 B 3
2023/06/07 17:22:18 佐藤 沙織 A 10
2023/06/07 17:29:26 平澤 俊英 C 7
2023/06/07 17:33:22 前田 久美子 A 5
2023/06/13 17:20:45 山口 明子 C 5
2023/06/13 17:24:11 大森 陽子 A 10
2023/06/13 21:47:26 佐藤 沙織 B 6
2023/06/22 15:22:49 平澤 俊英 A 8
2023/06/22 15:24:34 前田 久美子 C 2
2023/06/22 21:53:12 山口 明子 A 2
2023/06/28 15:19:40 大森 陽子 B 25
2023/06/28 15:22:12 佐藤 沙織 B 1
2023/06/28 15:31:26 平澤 俊英 A 9
2023/06/30 13:19:13 前田 久美子 C 1
2023/07/05 17:19:42 山口 明子 A 8
2023/07/05 17:26:14 大森 陽子 C 4
2023/08/21 1:44:09 佐藤 沙織 A 1
2023/09/26 17:20:08 平澤 俊英 C 6
2023/09/29 13:25:08 安西 清 C 10条件は以下の通りとします。
フォームデータは全て2023年なので 年を考慮する必要はない
月ごと商品毎の最大発注数のオーダーが2件以上あっても1件だけ出力でよい
1列目に 〇〇月という列を追加して、他は元データの並びでよい
どうでしょうか? これまでのお題の答えをしっかり理解していれば回答できるはずです。
まずは自力でチャレンジしてみましょう。
↓↓
ここから回答です。
↓↓
A4. フォームのデータから タイムスタンプで月毎の 商品別の 最大の発注数のオーダーを一覧にする
回答です。
=SORTN(SORT({IF(A2:A="",,TEXT(A2:A,"MM月")),A2:D},4,0),100,2,1,1,4,1)

まず、SORT関数で 発注数(4列目)をキー列として降順で並び替えておくことで、発注数が多いデータが上にくるように下準備をしておきます。(下準備が大事なのは料理と一緒)
ここで合わせて、〇〇月という列を生成しておきましょう。
TEXT(A2:A,"MM月")
今回は 〇〇月 と表示したいって要件なんで、TEXT関数を使って2桁で月表示にしています。
これは MONTH関数で月の数値を取得しても 、後ろに"月"をつけて 文字列化して並べ替えをすると、2月より12月の方が上にきてしまうといった問題が発生するからです。(SORT関数のお題で登場しましたね)
2桁表記の月にするなら、最初から TEXT関数を使った方が簡単です。
ただし、空白セルに TEXT(A2:A,"MM月") を適用すると 空白を数字の 0と判断してしまい、シリアル値 0は 日付だと 1899/12/30 となるので、空白セルに対して TEXT関数は 12月を返してしまいます。
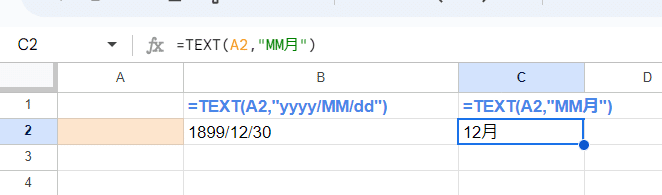
これを回避する為に IF関数で空白の際は空白を返すように分岐させます。
IF(A2:A="",,TEXT(A2:A,"MM月"))
これを元データと{ , } で横連結したものを SORT関数内で 発注数の降順に並び替えるついでに生成することで、配列処理用の Arrayformula を不要にしています。
SORT({IF(A2:A="",,TEXT(A2:A,"MM月")),A2:D},4,0)
このSORT関数の結果を SORTN関数で
=SORTN( SORT関数の結果, 100, 2, 1, 1, 4, 1)
100・・・ 出力する数(n)は十分に大きい適当な数
2 ・・・ モード2 重複排除
1,1 ・・・ 1列目( 〇〇月)を 昇順
4,1 ・・・ 4列目(商品)を昇順
※ 〇〇月が1列追加されてるので 商品は4列目
このように指定してすることで、モード2の 重複排除効果で
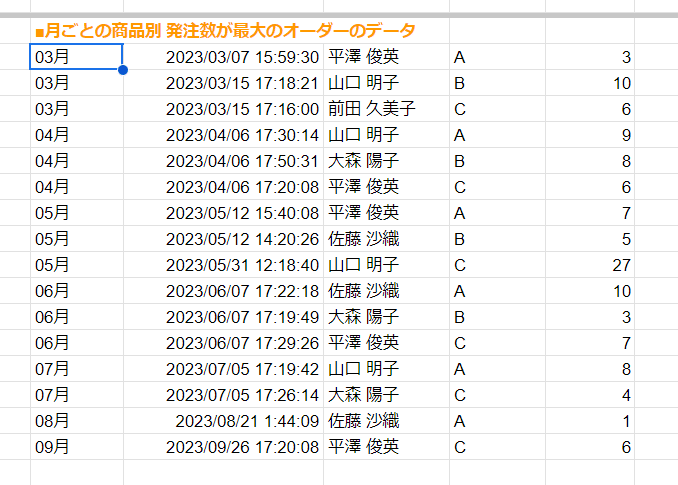
このように 月ごとに 商品毎の 最大発注数のデータを出力することが出来ます。
フォームの結果データと SORTN関数。いろいろ使えそうじゃないでしょうか?
SORTN関数は部分的なUNIQUE関数の処理が出来る便利な関数
全4回にわたって 超応用例を紹介してきた SORT関数 3回、SORTN関数 1回のシリーズも今回で終了です。
今回紹介した SORTN関数は使ったことがない人も多いんじゃないでしょうか?
でも、
データを部分的に UNIQUE処理して 各データの一番上だけもってこれたらいいな。
とか、
QUERY関数で グループ化 MAX 出力する際に、そのデータの他の要素も表示できたらなー。
と思ったことがある人は、結構いるんじゃないかと思います。
SORTN関数、まさにこれを実現できる関数だってことを今回知ることができましたね!
同じような処理は FILTER関数でも出来るんですが
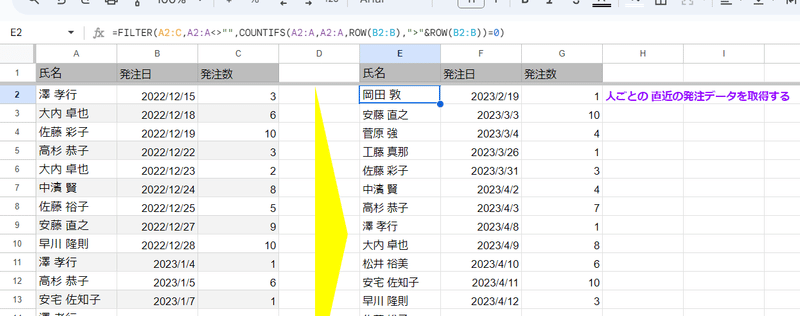
COUNTIFSを使ったちょっと複雑な式を組む必要があるので、ややハードルが高めかなと感じます。
一方、SORTN関数だと

=SORT(FILTER(A2:C,A2:A<>"",COUNTIFS(A2:A,A2:A,ROW(B2:B),">"&ROW(B2:B))=0))
↓
=SORTN(SORT(A2:C,ROW(A2:C)*(A2:A<>""),0),100,2,1,1)
このように 同じ結果を シンプルに記述することが出来ます。
ちなみに上の書き方も Excelでは機能しません。(ExcelのCOUNTIFSは配列を範囲部分の引数にとれない)
Googleフォームとも相性のよい SORTN関数、 是非使ってみてください!!
次回は「検索と置換」機能について 書きたいと思います。
この記事が気に入ったらサポートをしてみませんか?