
【2-8】Rで集計を行う色々な方法

`summarise()` has grouped output by 'group'. You can override using the `.groups` argument.
はじめに
今までの記事ではRの基本的な使い方やdata.frameを扱う方法、複数のファイルを繋げる方法を紹介してきました。今までの方法を組み合わせればある程度のデータの集計やグラフを作る下準備ができたと言えます。
今回はいよいよ集計する方法を紹介します。具体的にはグループごとの人数や合計、平均値などです。これらの計算は色々な方法があるため、代表的な方法を紹介します。
データの準備
#pacmanパッケージがあるかを確認。なければinstall.packagesパッケージをインストール
if (!require("pacman")) install.packages("pacman")
#今回使うパッケージ
pacman::p_load(tidyverse, rio)
url <- "https://github.com/mitti1210/myblog/raw/master/data.xlsx"
data <- import(url, which = "anova")
head(data)
D0:0日目のテストの結果
D30:30日目のテストの結果
D60:60日目のテストの結果
*架空データ
このdata.frameでは以下のような集計ができます。
D0の平均
D30の平均
D60の平均
group毎のD0の平均
group毎のD30の平均
group毎のD60 の平均
Rでは色々な方法で集計が可能です。
集計で使う関数色々
第1章で少しだけ紹介がありましたが、集計を行う関数を紹介します。
平均:mean() *ExcekだとAVERAGE()
標準偏差:sd() *ExcelだとSTDEV()
最大値:max()
最小値:min()
中央値:median()
数字の丸め:round() *例えば「小数点第2位まで」など
ちなみに途中にNA(空欄)があると全て結果がNAとなります。
その時はmean(ベルトル, na.rm = TRUE)とつけるとNAを無視してくれます
sum(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
sum(1, 2, 3, 4, NA, 6, 7, 8, 9, 10)
sum(1, 2, 3, 4, NA, 6, 7, 8, 9, 10, na.rm = TRUE) 
集計は基本縦に行うのが基本
Rでは基本的に縦に集計を行うことが多いです。ある行の集計を行う基本的な方法としてsummarize関数があります。
dplyrパッケージのバージョンを確認
データの集計に使う有名なパッケージとしてdplyrパッケージがあります。dplyrはtidyverseパッケージに含まれているため、いつもは気にしなくても良いのですが、今から行う方法はdplyrのパッケージのバージョンで異なります。
#dplyrのバージョンを確認
packageVersion("dplyr")
dplyrのバージョンが1.1以降の場合のsummarize()
バージョン1.1以降の場合はsummarize関数のみで集計ができます。
基本的な使い方
基本的な使い方は以下のとおりです。
`data.frame` |> summarize(`つけたい列名` = `計算`)
#D0の平均を求める
data |> summarize(meanD0 = mean(D0))
もしNAがあったときはmean(D0, na.rm = TRUE)とする
復数の集計を出すには並べることができます。
#D0, D30, D60の平均を求める
data |>
summarize(
meanD0 = mean(D0),
meanD30 = mean(D30),
meanD60 = mean(D60)
) 
グループごとに集計を行う
グループごとに集計する場合は.byを使います。
#D0, D30, D60の平均を求める
data |>
summarize(
meanD0 = mean(D0),
meanD30 = mean(D30),
meanD60 = mean(D60),
.by = group
) 
longデータだと集計が楽
D0, D30, D60の3つだと手打ちもいいですが、20個くらいあると面倒くさいです。その場合はlongデータにすること便利です。
#long形式にすると集計はもっと楽
long_data <-
data |>
pivot_longer(cols = starts_with("D"))
head(long_data) 
#group×日数の平均を求める
long_data |>
summarize(
mean = mean(value),
.by = c(group,name)) 
復数の集計を一覧に出すこともできます。
#他の集計も可能
long_data_summarize <-
long_data |>
summarize(
sum = sum(value),
mean = mean(value),
sd = sd(value),
mean_plus_sd = mean + sd,
mean_minus_sd = mean - sd,
median = median(value),
min = min(value),
max = max(value),
p25 = quantile(value, 0.25),
n = n(),
.by = c(group, name)
)
long_data_summarize 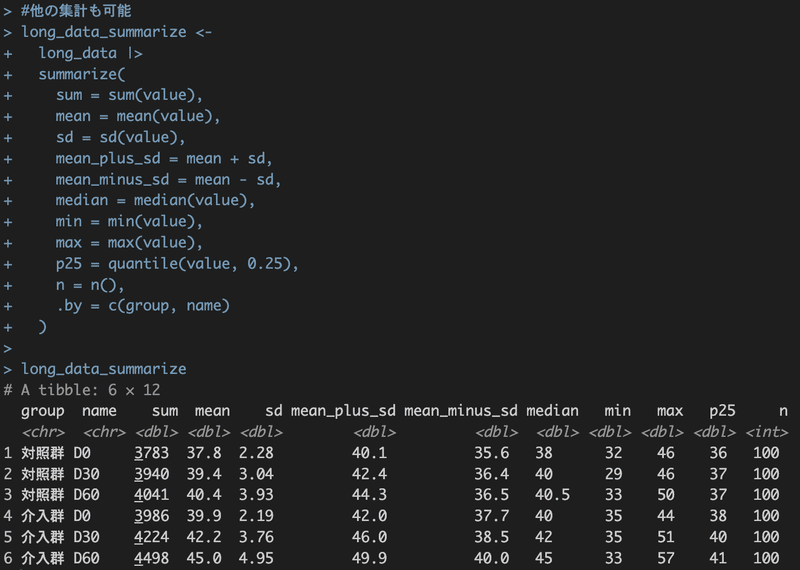
ちなみにp25は25%分位点としてquantle()を使いました
n数はn()を使います。()の中は何も入れません
ちなみにwideデータに戻すことも可能です。
long_data_summarize |>
pivot_wider(
values_from = sum:n,
names_from = name)
long_data_summarize |>
pivot_wider(
values_from = sum:n,
names_from = group) 
dplyrのバージョンが1.1より前の場合のsummarize()
バージョンが古いと.by = が使えません。
そのためgroup_by()とsummarize()の組み合わせが必要です。
data |>
group_by(group) |>
summarize(mean = mean(D0)) 
ただグループが復数になると注意が必要です。
long_data |>
group_by(group, name) |>
summarize(mean = mean(value)) 
上の画像をみると今までと違うところが2箇所あります。
1つ目は``summarise()` has grouped output by 'group'. You can override using the `.groups` argument.`のコメントです。
これは復数のグループがある時に、集計した後のグループ化をどうるか指定してください。という意味があります。
そこで2つめの違いですが、`Groups: group [2]`の文字が追加されています。
これはsummarize()は何も指定しないとgroup_by(group, name)の最後だけのnameが外れて、残りのgroupがグループ化されたままになります。
この後の集計でグループ化を残したほうが都合良ければよいのですが、なれない場合は一旦グループ化を外したほうがいいかもしれません。
グループ化を外すにはsummarize(.group = "drop)をつけるか、後でungroup()を使います。
long_data |>
group_by(group, name) |>
summarize(mean = mean(value), .groups = "drop")
long_data |>
group_by(group, name) |>
summarize(mean = mean(value)) |>
ungroup() 
型を確認する
平均をだすならmean(data$D0)でも出せます。
これとsummarize()は何が違うのでしょうか?
#型を調べる
mean(data$D0) |> class()
data |> summarize(mean = mean(D0)) |> class() 
結論から言うとmean()は数字でsummarize()はdata.frameです。
data.frameであるのは大きなメリットがあり、特にグラフを作る時にこの結果を使うことができます。
nest()とmutate()を使う
代表的な集計はsummarize()ですが、nest()を使うと違ったメリットがあります。ただ中級編とも言えるので難しければ後回しで大丈夫です。
#nestを使う
nest_data <- long_data |> group_nest(group, name)
nest_data
dataというが変わりました。
これはdataにはそれぞれ100行×1列(value)のデータがありますという意味になります。nestは入れ子とも表現されます。
このnestされたデータに対し、mutate()を使って集計を行います。
map_***()はfor文のように繰り返しを行う関数です。
map_dbl()は出力がnumericになります。
必要なのは.xと.fです。
.xはdata、.fは関数を指定し、1つ1つのdataに対して関数を当てはめていきます。
.fで関数の組み合わせを行うときはチルダ~を使います。
nest_data_summarize <-
nest_data |>
mutate(
mean = map_dbl(
.x = data,
.f = ~pull(.x, value) |> mean())) #.xはここではdataのこと
nest_data_summarize

nest()を使う方法のメリットとして、dataが残るためnestしたデータを戻すことができます。unnest()を使います。
ここではさらに平均 - valueを求めます
nest_data_summarize |>
unnest(cols = data) |>
mutate(distance = value - mean) |> view()

summarize()を使うと元のデータは消えてしまうため、このように集計したデータと元のデータを組み合わせたい場合はnest()を使うのも1つの方法です。
まとめ
今回は集計、特にsummarize()の解説を行いました。
longデータに直しsummarizeで集計しグラフを作るという流れはよく行う流れなのでぜひ挑戦してみて下さい。
この記事が気に入ったらサポートをしてみませんか?