
Photo by
oryotao
pycaretで機械学習を始める前のはなし

始めに
pycaretについて試したことを書いていこうと思いますが、まずは基本的な確認事項から。
バージョン確認
import pycaret
pycaret.__version__私の環境では'2.3.10'でした。
サンプルデータセットの確認
機械学習にはデータが欠かせない。大体の機械学習ライブラリにはデータセットがついているけど、pycaretにもたくさんのデータセットが付いてくる。あくまで練習用のデータでしょうが、面白そうなのが幾つかあります。
from pycaret.datasets import get_data
get_data(”index”)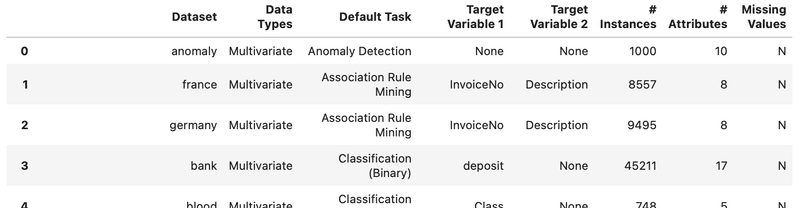
ちなみに、get_dataのパラメータに渡している"index"は、デフォルトパラメータなので、無くても結果は同じになります。データの取得にはオンラインである必要がありますのでご注意を。
サンプルデータを選んで取得
サンプルデータのDataset列の名前を使って、pandasのDataFrame形式でデータを取得することができます。今回はタイタニックのデータにしようと思います。
ちなみに、タイタニックデータというのは、あの大型客船タイタニックの乗客情報から、生存したかどうかを機械学習を使って予想するためのデータで、機械学習の練習でよく使われるデータです。生存かどうかを判定するので、バイナリクラス分析となります。
data_titanic = get_data("titanic")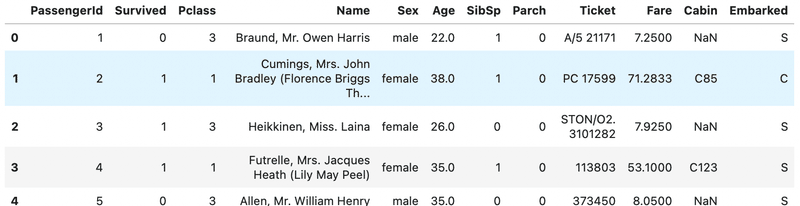
データ件数を確認
data_titanic.shape(891, 12)
891件のレコードデータと、12個の特徴があることが分かります。
欠損値の確認
タイタニックのデータに欠損値があることは、get_data()のtitanicの行のMissing Valuesの項目がYであることから分かります。

どの特徴に欠損値がどのくらいあるのか調べた結果がこれ。
#欠損値の確認
data_titanic.isnull().sum()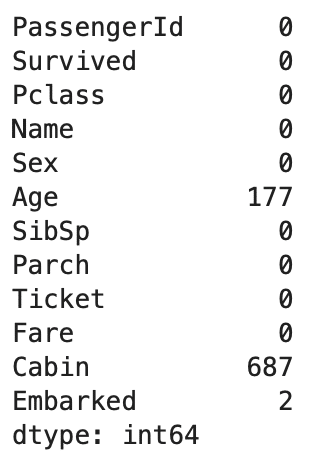
年齢(=Age)不詳と船室番号(=Cabin)不明が多いな。
長くなりそうなので、次から本格的なデータ解析ということで。なかなかpycaretの本題に入れませんが気長にやります。
この記事が気に入ったらサポートをしてみませんか?