ビットコインと株、債券を組み合わせた最適ポートフォリオ割合は?【pythonコード付き】

ビットコインと株、債券を組み合わせて、リスクとリターンのバランスを取ろうとしたら、どんな割合になるのか気になったので計算しました。
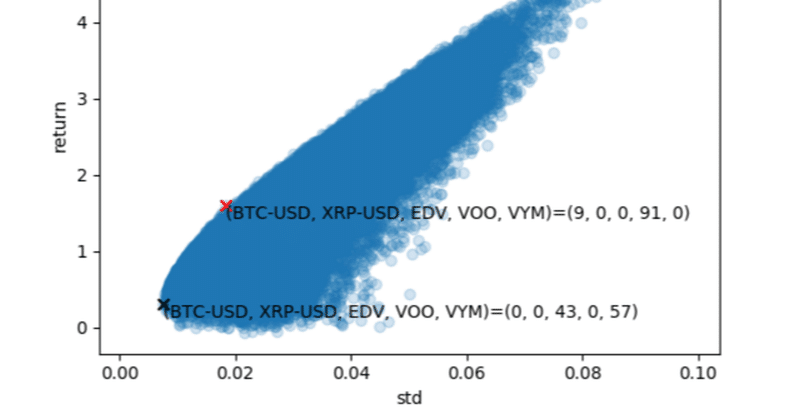
ビットコインとリップル、EDV(超長期米国債ETF)、VOO(S&P500連動ETF)、VYM(米国高配当株ETF)を6年前から現在(2024/03/18)まで保有し続けたときのリスクあたりのリターンが最大になる割合と、リスクが最小になるポートフォリオの割合を探す。
最後に、計算に使ったpythonコードを掲載するので、使える人は自身の好みの銘柄で試してみて欲しい。

グラフの縦軸が6年間のリターンで、横軸が日次リターンの標準偏差を表している。グラフの各点が、様々な割合のポートフォリオの結果を指す。
リスクあたりのリターンが最大になるポートフォリオは赤い点で、ビットコイン 9.3%、VOOが90.7%となった。(6年利益+161%, 日次リスク2%)
意外とビットコインの割合が大きい。債権は含まれなかった。
リスクを最小にするポートフォリオは黒い点で、リップル 0.4%、EDV 40.3%、VYM 57.3%となった。(6年利益+31%, 日次リスク0.7%)
ほんの少しだがリップルが組み込まれた。
計算しといて難だが、リスク・リターン比を最適化した場合の6年間の利益が+161%とちょっと物足りない結果に私は思ってしまった。暗号資産界隈の荒波に揉まれるのに慣れてしまった私はリスクジャンキー過ぎるのかも?
ちなみに、ビットコインとマグニフィセント7でリスクあたりリターンが最大になるポートフォリオを組んだら、
ビットコイン14%、マイクロソフト34%、エヌビディア52%のポートフォリオで6年リターン+920%という結果に。( 日次リスク6.7%)
うーん、エヌビディア最強!!
計算コードはこちら↓適宜改造して使って欲しい。
import pandas as pd
import datetime
import yfinance
import numpy as np
import warnings
import matplotlib.pyplot as plt
from scipy.optimize import minimize
warnings.simplefilter('ignore')
# シャープレシオ
def func1(x,s,rfr):
tot = s @ x
r = tot[1:-1] - tot[0:-2]
std = np.std(r)
ret = tot[-1] - 1
y = (ret-rfr)/std
return -y
# リスク
def func2(x,s,rfr):
tot = s @ x
r = tot[1:-1] - tot[0:-2]
std = np.std(r)
return std
# 資産の和を1に拘束
def cons(x):
return sum(x)-1
#期間を指定
years = 6
days = years*365
end = datetime.date.today()
start = end - datetime.timedelta(days=days)
# 銘柄指定
coins = ['BTC-USD','XRP-USD']
#stocks = ['AAPL','AMZN','GOOGL','META','MSFT','NVDA','TSLA',] #マグニフィセント7
stocks = ['VOO','VYM','EDV']
RFR = 1.03**years-1. # risk free ratio
# ダウンロード
df_c = yfinance.download(coins,start,end,auto_adjust=True)["Close"]
df_s = yfinance.download(stocks,start,end,auto_adjust=True)["Close"]
# 合体
df = pd.merge_asof(df_c,df_s,on='Date')
df.ffill(inplace=True) # NaNを直前の値で埋める
df.set_index('Date',inplace=True)
tickers = df.columns.to_list()
print(df)
# 相関行列
#corr = df.corr()
#print(corr)
cl = df.values
n = cl.shape[0]
l = cl.shape[1]
a = np.zeros((n,l))
for i in range(l):
a[:,i] = cl[:,i]/cl[0,i]
m = 100000
std = np.zeros(m)
ret = np.zeros(m)
ratio = 0
best = None
for i in range(m):
rnd = np.random.rand(l)
rnd = rnd/np.sum(rnd)
tot = a @ rnd
r = tot[1:-1] - tot[0:-2]
std[i] = np.std(r)
ret[i] = tot[-1] - 1
bounds = [[0., 1.] for i in range(l)]
cons = ({'type': 'eq', 'fun': cons},)
xini = np.random.rand(l)
xini = xini/np.sum(xini)
result_s = minimize(func1, xini, constraints=cons, bounds=bounds, args=(a,RFR))
result_m = minimize(func2, xini, constraints=cons, bounds=bounds, args=(a,RFR))
xs = result_s["x"]
tot = a @ xs
r = tot[1:-1] - tot[0:-2]
std[0] = np.std(r)
ret[0] = tot[-1] - 1
xm = result_m["x"]
tot = a @ xm
r = tot[1:-1] - tot[0:-2]
std[1] = np.std(r)
ret[1] = tot[-1] - 1
print('maximize:return/std')
print('std_s',std[0])
print('ret_s',ret[0])
print('per_s',xs)
print('minimize:std')
print('std_m',std[1])
print('ret_m',ret[1])
print('per_m',xm)
plt.scatter(std,ret,alpha=0.2)
txt = '('+', '.join(tickers)+')='+'('+', '.join(['{:.0f}'.format(100*n) for n in xs])+')'
plt.text(std[0],ret[0],txt,va="top")
plt.scatter(std[0],ret[0],marker='x',c='r',s=40)
txt = '('+', '.join(tickers)+')='+'('+', '.join(['{:.0f}'.format(100*n) for n in xm])+')'
plt.text(std[1],ret[1],txt,va="top")
plt.scatter(std[1],ret[1],marker='x',c='k',s=40)
plt.xlabel('std')
plt.ylabel('return')
plt.show()
yfinanceに銘柄のリストを渡したときに、返ってくるデータフレームの列順は、渡したリストの銘柄の順番と違う。暗号資産と株の順番が混ざるのが嫌だったので、上のコードでは別々に分けて取得した後に合体させている。
この記事が気に入ったらサポートをしてみませんか?