エンジニア女子が触れているプログラミング言語の傾向をPythonを使って分析する - (エピソード5)

Python製の形態素解析器 Janome を使って再び形態素解析で名詞のみを抜き出す
前回の自身のミスにより、もう一度形態素解析から行っていきます。
一度実施していることなので、駆け足で進んでいこうと思います。
Janomeで形態素解析を行って、名詞のみを抜き出します
from janome.tokenizer import Tokenizer
from janome.analyzer import Analyzer
from janome.tokenfilter import *
import glob
import os
def main(filepath, t, a, result_file):
with open(filepath) as f:
text = f.read()
for token in a.analyze(text):
print(token.surface)
result_file.write(token.surface + "\n")
def listup_files(path):
return [os.path.abspath(p) for p in glob.glob(path)]
if __name__ == "__main__":
print("=== 処理を開始します ===")
target_path = "./texts/*"
path_list = listup_files(target_path)
t = Tokenizer()
token_filters = [POSKeepFilter('名詞')]
a = Analyzer(token_filters=token_filters)
with open("./textanalysis_result_2.csv", mode="w") as f:
f.write("単語\n")
for i in path_list:
main(i, t, a, f)
print("=== 処理が完了しました ===")
token_filters = [POSKeepFilter('名詞')]とすることで名詞のみを抜き出します。
また、token.surfaceでテキストのみを抜き出してcsvファイルに書き込むように変更しています。
CSVファイルをgoogle spreadsheetsにインポート
今度は一つの記事の中に複数の単語が現れている場合でも、すべて一つずつ抽出されるため、行数がすごいことになっています。

Google Spreadsheets内で重複している単語の数をそれぞれ数える方法
Google スプレッドシートで一意の単語を抜き出す方法
まずは一意の単語リストを作成します。意外とGoogle spreadsheetだとやり方が直感的でないような気がしたので、キャプチャ付きで書いていきます。
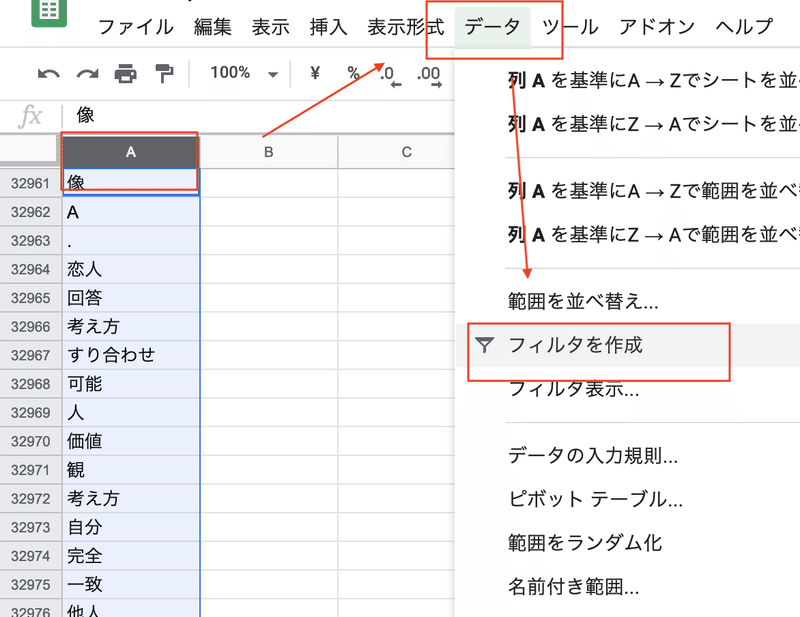
一意にしたい行を選択した状態でデータメニューを選択し、フィルタを作成を選択する
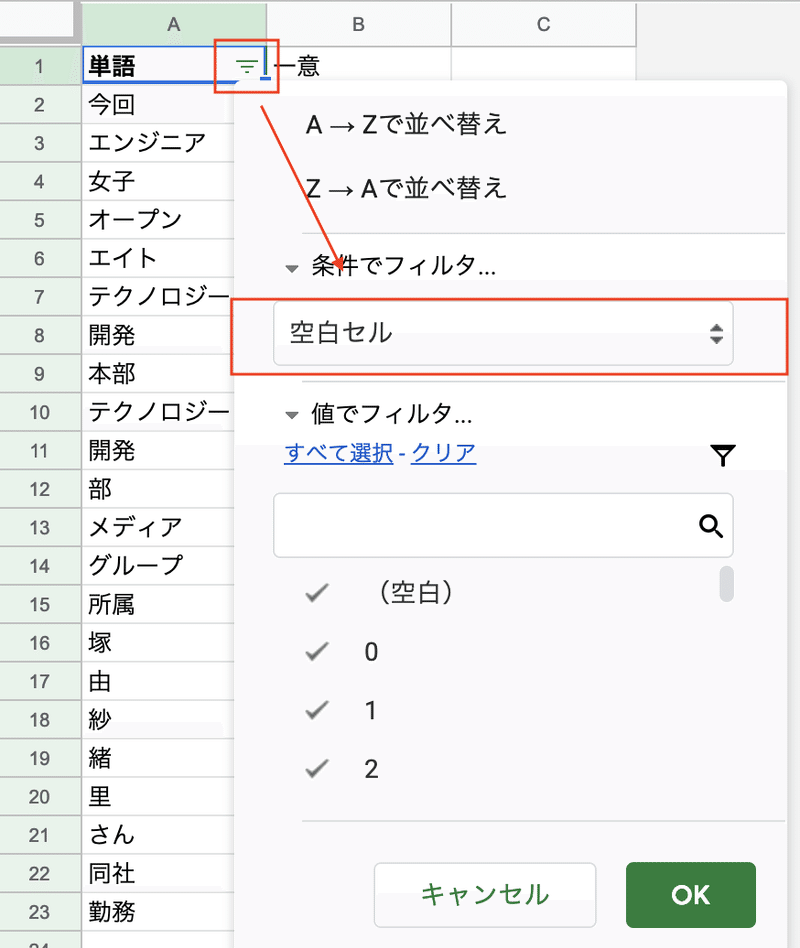
選択した行の先頭に矢印アイコンが付くので、そこを選択することで条件でフィルタをすることができます。そこに空白セルを選択すれば空白セルのみ表示することができるので、あとは行を削除すればOKです。
重複した文字列を削除した行を作成する
これはUNOQUE関数を利用します。
B行に対して、下記のような計算式を代入することで、重複を覗いた文字の行が作成されます。
=UNIQUE(A2:Aの最終セル)簡単ですね。
一意に抜き出した単語の重複数を取得する
次に不要な文字列を削除しようと思っていましたが、考えてみればこれは特に不要そうです。
まずはシートのC列に下記の計算式を入力し、単語が入力されているセル全てにコピペします。
これで一意に抜き出した文字列の重複数を表示することができます。
=COUNTIF(A$2:A$A行の最終行,B2)(セルを選択するときに A$2 と指定することで、行が変わっても固定で同じセルの値を格納することができます。)
この場合COUNTIF関数の第一引数にはセルの範囲を入力します。一行目が単語と書かれたいわゆるヘッダー行になるので、2行目から最後までを対象は似とし、第2引数には一意に抜き出したB行の単語をセットすることで、一意に抜き出した単語のカウントを取得できます。
(ちなみにこの処理は結構時間がかかります)
数の多い順にソートしていく
ここまでやれれば、後は重複数の多い順にソートして、技術系単語を見ていくだけです。
(ソート自体はC行を選択した状態でデータメニューからZ→Aでシートを並べ替えというのをやれば簡単に並び替えできます)
結果は次回見ていくことにしましょう。
頂いたサポートは、より面白い記事を執筆するためのリサーチ費用やクラウド導入費用など、何らかの用途に使用していきたいと考えています。